python批量旋转裁剪图片实战
python批量旋转裁剪图片实战
引子
有一本PDF电子书,由扫描的图片生成的,每页的截图看起来如下图:
它是展开扫描的,两页并列在一张图片上。并且每页又是分两栏,这样的PDF在手机、平板上,需要放大阅读,不停地左右移动,非常不便。
就想到将PDF导出为图像文件,将每张图片分割为两张,再合成为PDF,这样阅读起来就舒服多了。
导出PDF为图像后,发现图像又是这样的:

有两个方法:
- 一是 在 PS 中创建一个动作,对图片进行旋转、裁剪、新建、粘贴、另存为操作,再对得到的图片重命名;不断重复这个过程。
- 二是 学 python 的,用 python 对导出的图片进行批量操作,“自动化办公”。
第一种方法非常枯燥、费时。
python 人的思路
- 使用 python PIL 库;
- 创建一个
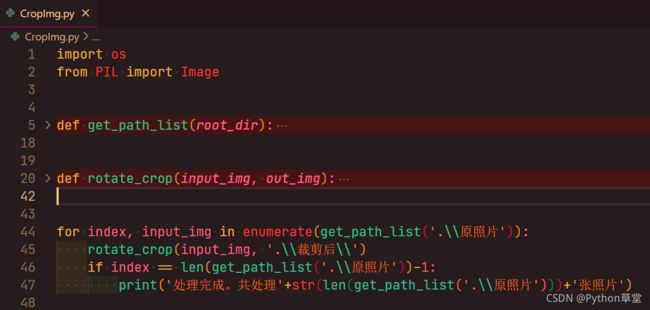
CropImg.py模块,存储全部代码; - 定义一个函数
def get_path_list(root_dir):,获取原照片保存目录下的全部照片的完整文件名,保存到一个列表中,函数返回这个列表; - 定义一个方法
def rotate_crop(input_img, out_img):,遍历列表中的每张照片,打开照片、旋转照片、将照片一分为二、分别重命名保存到指定目录中。 - 小程序的结构如下图:
效果
运行CropImg.py,几分钟即完成了几百页图片的处理,结果非常满意。


学习 python,自动化处理一些重复的办公任务,其乐无穷!
完整的代码可以到 Python草堂QQ群 457079928 下载。有问题和更好的想法也可以到草堂来讨论!