Pytorch基础知识(7)单目标检测
目标检测是在图像中找到特定目标位置的过程。根据图像中目标的数量,我们可以处理单目标或多目标检测问题。本章将重点介绍使用PyTorch实现单目标检测。在单目标检测中,我们试图在给定的图像中只定位一个目标。对象的位置可以通过边界框定义。
我们可以用下面的三种格式的一种来表示一个边界框:
- [x0, y0, w, h]
- [x0, y0, x1, y1]
- [xc, yc, w, h]
其中:
- x0, y0 表示边界框左上角的坐标
- x1, y1 表示边界框右下角的坐标
- w, h 表示边界框的宽度和高度
- xc, yc 表示边界框质心的坐标
作为一个例子,让我们看看下面的截图,其中xc, yc = 1099, 1035;W, h = 500,
500;X0, y0 = 849, 785;x1, y1 = 1349, 1285:
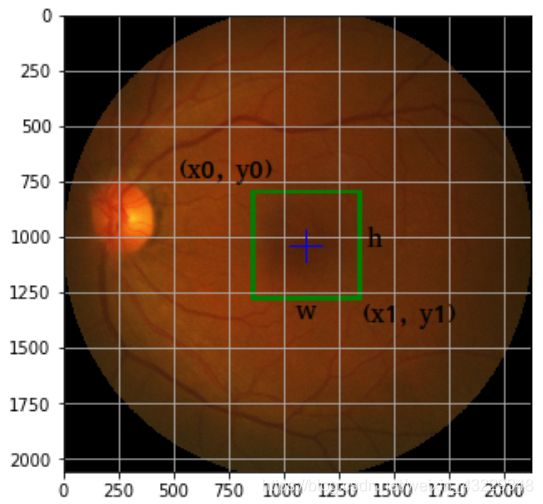
因此,单目标检测的目标是预测一个用四个数字表示的边界框。在方形物体的情况下,我们可以通过固定宽度和高度将问题简化为只预测两个数字。在本章中,我们将创建一个算法来用两个数字定位眼睛图像中的中央凹。
在本章中,我们将介绍以下内容: - 数据分析
- 用于目标检测的数据变换
- 创建自定义数据集
- 创建模型
- 定义损失、优化器和IOU度量
- 模型的训练与评估
- 部署模型
数据分析
数据分析通常是为了了解数据的特征。在数据分析中,我们将检查数据集和可视化数据的样本或使用箱线图、直方图和其他可视化工具统计特征。例如,对于表格数据,我们希望看到列、几行、许多记录和如数据的平均值和标准偏差的统计度量。对于图像数据,我们将在图像中显示样本图像、标签或对象的边界框。
我们将使用来自Grand Challenge网站上的iChallenge-AMD 比赛的数据。这个竞赛有多个任务,包括分类、定位和分割。我们只对定位任务感兴趣。在本教程中,我们将探索iChallenge-AMD数据集。
准备
-
数据准备
iChallenge-AMD数据集
需要创建一个账户才能下载数据集。 -
选择Download选项
-
点击images and AMD labels下载数据

-
点击Download按钮,选择Direct Download。下载到iChallenge-AMD-Training400.zip文件后,将.zip文件移到代码同目录下的data目录中。
-
解压.zip文件到data/Training400。目录中包含拥有89张图片名为AMD的文件夹,以及拥有311张图片名为Non-AMD文件夹和名为Fovea_location.xlsx的Excel文件。
-
Excel文件包含了400张(89 + 311)图像中中央凹的中心位置。
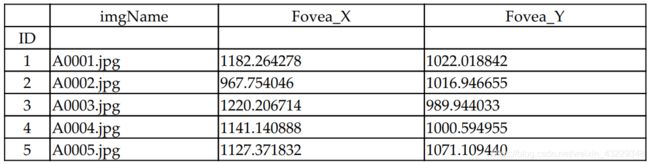
为了探索数据集,首先显示一些样本数据以及对应的标签数据
探索数据
- 导入Fovea_location.xlsx文件并且打印前几个数据
import os
import pandas as pd
path2data = "./data/"
path2labels = os.path.join(path2data, "Training400", "Fovea_location.xlsx")
# make sure to install xlrd
labels_df = pd.read_excel(path2labels, index_col="ID")
labels_df.head()
结果显示如下:
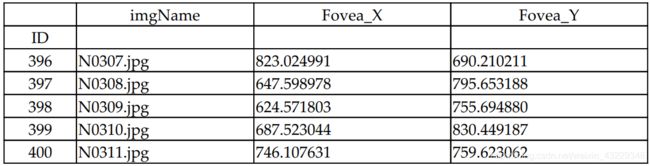
- 打印后几个数据
labels_df.tail()
结果显示如下:
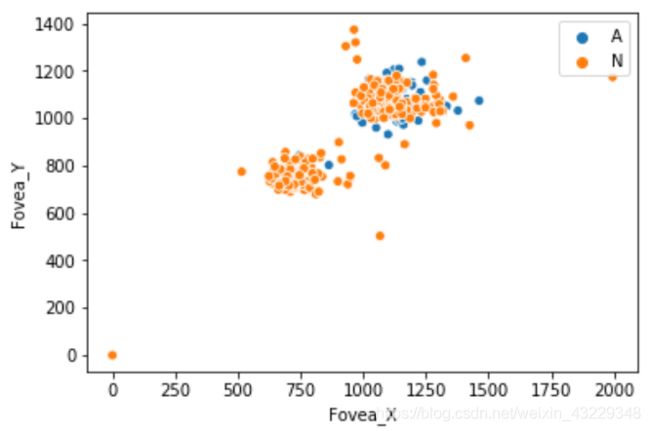
- 然后,我们将显示Fovea_X和Fovea_Y坐标的散点图
import seaborn as sns
AorN = [imn[0] for imn in labels_df.imgName]
sns.scatterplot(x=labels_df["Fovea_X"], y=labels_df["Fovea_Y"], hue=AorN)
- 显示样本图像
import numpy as np
from PIL import Image, ImageDraw
import matplotlib.pylab as plt
# fix random seed
np.random.seed(2021)
# 设置参数
plt.rcParams["figure.figsize"] = (15, 9)
plt.subplots_adjust(wspace=0, hspace=0.3)
nrows, ncols=2, 3
# 随机获取图片
imgName = labels_df["imgName"]
ids = labels_df.index
rndIds = np.random.choice(ids, nrows*ncols)
print(rndIds)
打印随机选择的图片索引:
[ 73 371 160 294 217 191 247 25]
下一步,定义一个加载图片以及对应标签的函数
def load_img_label(labels_df, id_):
imgName = labels_df["imgName"]
if imgName[id_][0] == "A":
prefix = "AMD"
else:
prefix = "Non-AMD"
fullPath2img = os.path.join(path2data, "Trainging400", prefix, imgName[id_])
img = Image.open(fullPath2img)
x = labels_df["Fovea_X"][id_]
y = labels_df["Fovea_Y"][id_]
label = (x, y)
return img, label
# 定义一个显示图像以及bbox的函数
def show_img_label(img, label, w_h=(50, 50), thickness=2):
w,h = w_h
cx,cy=label
draw = ImageDraw.Draw(img)
draw.rectangle(((cx-w/2, cy-h/2), (cx+w/2, cy+h/2)), outline="green", width=thickness)
plt.imshow(np.asarray(img))
# 显示带有bbox的图片
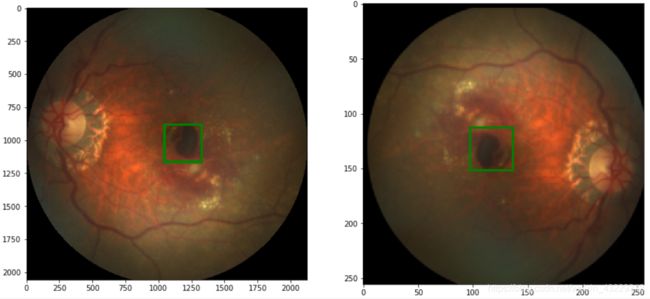
for i, id_ in enumerate(rndIds):
img, label = load_img_label(labels_df, id_)
print(img.size, label)
plt.subplot(nrows, ncols, i+1)
show_img_label(img, label, w_h=(150, 150), thickness=20)
plt.title(imgName[id_])
# (2124, 2056) (1037.89889229694, 1115.71768088143)
# (1444, 1444) (635.148992978281, 744.648850248249)
# (1444, 1444) (639.360312038611, 814.762764100936)
# (2124, 2056) (1122.08407442503, 1067.58829793991)
# (2124, 2056) (1092.93333646222, 1055.15333296773)
# (2124, 2056) (1112.50135915347, 1070.7251775623)
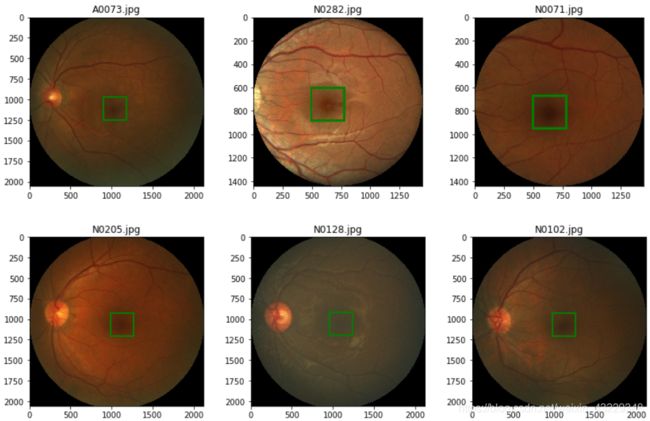
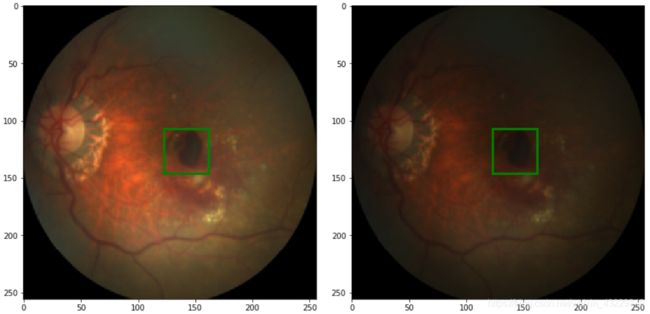
以下图像显示了带有bbox的样本图像
- 用两个列表收集图像的宽与高
h_list, w_list = [], []
for id_ in ids:
if imgName[id_][0] == "A":
prefix = "AMD"
else:
prefix="Non-AMD"
fullPath2img = os.path.join(path2data, "Training400", prefix, imgName[id_])
img = Image.open(fullPath2img)
h,w = img.size
h_list.append(h)
w_list.append(w)
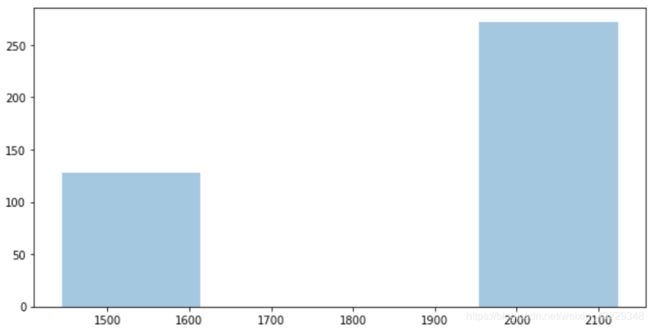
- 绘制出宽和高的分布
sns.distplot(a=h_list, kde=False)
sns.distplot(a=w_list, kde=False)
代码解析:
在步骤1中,我们从Excel文件中加载标签。我们使用了pandas库,并假设Fovea_location.xlsx位于./data/Training400文件夹中。在Windows系统上,您可能不需要安装任何东西。对于Linux系统,要使用pandas加载Excel文件,需要安装xlrd包。
然后,我们将文件加载到一个pandas DataFrame中,并打印出它的前几行。DataFrame有三列:imgName、Fovea_X和Fovea_Y。imgName列表示图像文件名,Fovea_X列和Fovea_Y列分别表示中央凹中心的X和Y坐标。注意,前89行对应于AMD图像,以字母A开头。
在步骤2中,我们打印了DataFrame的尾部。您可以看到ID达到400,与图像的数量相同。另外,请注意,最后311行对应的是非amd图像,以字母N开头。
在步骤3中,我们展示了Fovea_X和Fovea_Y的散点图。我们使用了seaborn库来显示散点图。Seaborn是一个基于matplotlib的Python数据可视化库。它提供了一个高级界面来绘制统计图形。
正如我们所观察到的,这些中心聚集成两组。同样,图像类别(AMD vs Non-AMD)和中央凹位置之间也没有相关性。有趣的是,有一些图像在(0,0)坐标处有中央凹。我们可以从DataFrame中删除零值,如下面的代码块所示:
labels_df = labels_df.replace(0, None)
labels_df.dropna
然而,因为只有很少的图像像这样,我们选择保留它们。
在第4步中,我们显示了一些带有中央凹边界框的随机图像。中央凹的位置是作为一个中心点给出的,因此,为了显示一个边界框,我们使用PIL.imageDraw包中的rectangle创建一个矩形。我们还打印了图像尺寸大小。正如我们所看到的,图像有不同的尺寸。
在步骤5中,我们得到图像的高度和宽度列表。这将用于绘制步骤6中高度和宽度的分布。分布图显示,大部分的高度和宽度都在1900到2100之间。
目标检测的数据变换
数据扩充和数据变换是深度学习算法训练的关键步骤,特别是对于小数据集。本章中的iChallenge-AMD数据集只有400张图片,这被认为是一个小数据集。提醒一下,我们稍后将分割此数据集的20%用于评估目的。由于图像有不同的大小,我们需要调整所有的图像到一个预先确定的大小。然后,我们可以利用各种增强技术,如水平翻转、垂直翻转和平移,在训练期间扩充我们的数据集。
在目标检测任务中,当我们对图像进行这样的转换时,我们也需要更新标签。例如,当我们水平翻转图像时,图像中物体的位置将发生变化。而torchvision.transforms提供了用于图像变换的实用函数,我们需要构建自己的函数来更新标签。在这个教程中,我们将开发一个管道,同时实现单目标检测中的图像变换和标签更新。我们将开发水平翻转、垂直翻转、平移和调整大小。然后可以根据需要向管道添加更多的变换。
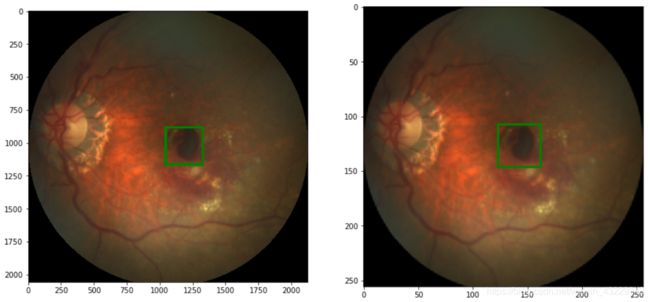
- 首先,实现一个调整图像大小的函数
import torchvision.transforms.functional as TF
def resize_img_label(image, label=(0., 0.), target_size=(256, 256)):
w_orig, h_orig = image.size
w_target, h_target = target_size
cx, cy = label
image_new = TF.resize(image, target_size)
label_new = cx/w_orig * w_target, cy/h_orig * h_target
return image_new, label_new
# 使用上面的函数调整图像大小
img, label = load_img_label(labels_df, 1)
print(img.size, label)
img_r, label_r = resize_img_label(img, label)
print(img_r.size, label_r)
plt.subplot(1, 2, 1)
show_img_label(img, label, w_h=(150, 150), thickness=20)
plt.subplot(1, 2, 2)
show_img_label(img_r, label_r)
# (2124, 2056) (1182.26427759023, 1022.01884158854)
# (256, 256) (142.4951295024006, 127.25526432230848)
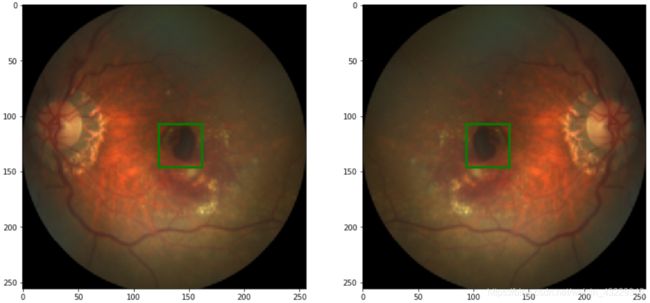
- 接下来,我们将定义一个函数来实现随机水平翻转图像
def random_hflip(image, label):
w,h=image.size
x,y=label
image = TF.hflip(image)
label = w-x, y
return image, label
# 使用上面的函数翻转图像大小
img, label = load_img_label(labels_df, 1)
img_r, label_r = resize_img_label(img, label)
img_fh, label_fh = random_hflip(img_r, label_r)
plt.subplot(1, 2, 1)
show_img_label(img_r, label_r)
plt.subplot(1, 2, 2)
show_img_label(img_fh, label_fh)
- 接下来,我们将定义一个函数来实现随机垂直翻转图像
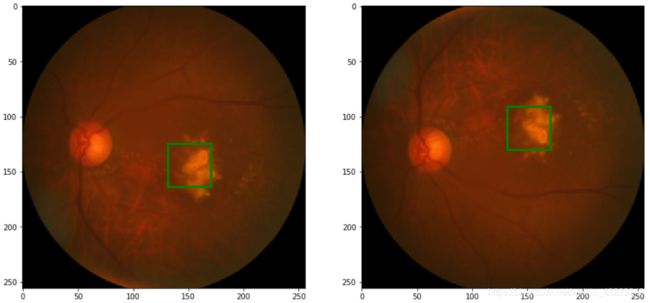
def random_vflip(image, label):
w,h = image.size
x,y = label
image = TF.vflip(image)
label = x, h-y
return image, label
# 使用上面的函数翻转图像大小
img, label = load_img_label(labels_df, 7)
img_r, label_r = resize_img_label(img, label)
img_fv, label_fv = random_vflip(img_r, label_r)
plt.subplot(1, 2, 1)
show_img_label(img_r, label_r)
plt.subplot(1, 2, 2)
show_img_label(img_fv, label_fv)
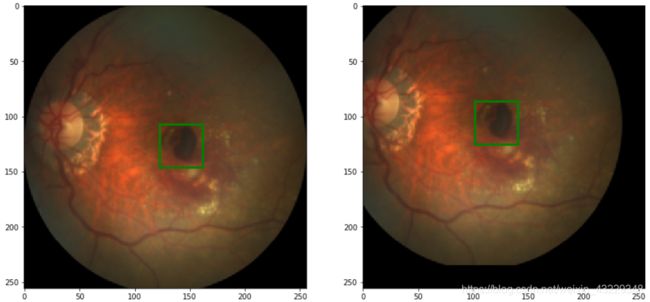
- 下一步,实现图像沿任意角度的随机平移
import numpy as np
np.random.seed(1)
def random_shift(image, label, max_translate=(0.2, 0.2)):
w,h=image.size
max_t_w, max_t_h = max_translate
cx,cy = label
trans_coef = np.random.rand()*2-1
w_t = int(trans_coef*max_t_w*w)
h_t = int(trans_coef*max_t_h*h)
image = TF.affine(image, translate=(w_t, h_t), shear=0, angle=0, scale=1)
label = cx+w_t, cy+h_t
return image, label
# 使用上面的函数平移图像
img, label = load_img_label(labels_df, 7)
img_r, label_r = resize_img_label(img, label)
img_t, label_t = random_shift(img_r, label_r, max_translate=(.5, .5))
plt.subplot(1, 2, 1)
show_img_label(img_r, label_r)
plt.subplot(1, 2, 2)
show_img_label(img_t, label_t)
- 将以上的函数组合到一个函数transformer上
def transformer(image, label, params):
image, label = resize_img_label(image, label, params["target_size"])
if random.random() < params["p_hflip"]:
image, label = random_hflip(image, label)
if random.random() < params["p_vflip"]:
image, label = random_vflip(image, label)
if random.random() < params["p_shift"]:
image, label = random_shift(image, label, params["max_translate"])
image = TF.to_tensor(image)
return image, label
# 使用以上函数
import random
np.random.seed(0)
random.seed(0)
img, label = load_img_label(labels_df, 1)
params = {
"target_size": (256, 256),
"p_hflip": 1.0,
"p_vflip": 1.0,
"p_shift": 1.0,
"max_translate": (0.2, 0.2),
}
img_t, label_t = transformer(img, label, params)
# 显示原始图像以及变换后的图像
plt.subplot(1,2,1)
show_img_label(img, label, w_h=(150,150),thickness=20)
plt.subplot(1,2,2)
show_img_label(TF.to_pil_image(img_t), label_t)
代码解析
在步骤1中,我们定义了一个函数来调整PIL图像的大小,并将标签更新到目标大小。调整PIL图像的大小,我们可以使用torchvision.transforms.functional的resize函数。作为一个提醒,PIL以这种格式返回图像大小:width, height=image.size。这可能会让人感到困惑,如果你使用OpenCV包,有时会产生bug。
为了更新标签,也就是中央凹坐标,我们需要根据每个维度的大小来缩放坐标。缩放因子是对应于x坐标的w_target/w_orig 和对应于y坐标的h_target/h_orig。
在步骤2中,我们构建了一个函数来水平翻转图像和标签。我们使用torchvision中的hflip函数来实现水平翻转图像。对于水平翻转,y坐标是相同的,只有中央凹的x坐标位置会变成width-x。查看翻转前后的图像,注意中央凹和网膜位置的变化。
在第3步中,我们构建了一个函数来实现垂直翻转图像和标签。我们使用了torchvision的vflip函数来垂直翻转图像。在垂直翻转的情况下,x坐标保持不变,只有中央凹位置的y坐标会改变为height-y。查看翻转前后的图像,注意中央凹和网膜位置的变化。
在步骤4中,我们定义了一个函数来将图像向左、向右、向上或向下移动或平移。
变换大小是随机选择的;但是,它受到max_translate =(0.2, 0.2)参数的限制。这意味着x和y维度的最大平移量将是0.2width和0.2height。例如,对于256*256的图像,每个方向的最大平移量为51像素。要设置数据增强过程中最大的图像平移量,请考虑感兴趣对象的位置。您不希望平移后的对象落在图像之外。对于大多数问题,在[0.1,0.2]范围内的值是安全的。但是,请确保根据您的具体问题调整这个值。此外,为了在任意方向(左、右、上、下)随机平移图像,我们生成一个范围为[- 1,1]的随机值,并将其乘以最大平移量。
为了变换图像,我们使用torchvision的affine函数。此函数可以执行其他类型的转换,如旋转、剪切和缩放。这里,我们只使用了变换特性。最后,随着平移量的增加,中央凹中心的x和y坐标也会发生变化。
在步骤5中,我们将多个变换叠加到一个函数中。稍后,我们将把变换函数传递给dataset类。正如从变换的图像中观察到的,五种变换依次应用到PIL图像。在构建自定义变换时,应该注意函数的顺序。例如,最好先调整图像的大小,以减少其他变换的计算复杂度。此外,利用TF.to_tensor变换为张量。这个变换缩放PIL图像到[0,1]范围和调节图像到[channel,height,width]形状。因此,为了显示变换后的图像,我们使用TF.to_pil_image()将其转换回PIL图像。我们还参数化了增强参数,以便您可以使用不同的值。如果您想禁用转换,您可以简单地将概率设置为零,就像我们将对验证数据集所做的那样。变换概率的一般值是0.5。在这里,为了强制所有的转换,我们将概率设置为1.0。
还有其他类型的变换可以应用于图像以增强数据。有些不需要对标签进行任何更新。
例如,我们可以通过调整亮度来创建新的图像,如下面的代码块所示:
img, label = load_img_label(labels_ds, 1)
# resize image and label
img_r, label_r = resize_img_label(img, label)
# adjust brightness
img_t = TF.adjust_brightness(img_r, brightness_factor=0.5)
label_t = label_r
plt.subplot(1,2,1)
show_img_label(img_r, label_r)
plt.subplot(1,2,2)
show_img_label(img_t, label_t)
同样,我们可以通过调整对比度和伽马校正来创建新的图像,如下代码块所示:
# brightness
img_t = TF.adjust_contrast(img_r, contrast_factor=0.4)
# gamma correction
img_t = TF.adjust_gamma(img_r, gamma=1.4)
我们通常对标签进行另一种转换。在这个转换中,我们使用以下函数将标签缩放到[0,1]的范围:
def scale_label(a, b):
div = [ai/bi for ai,bi in zip(a,b)]
return div
对于目标检测任务,将标签缩放到[0,1]的范围是重要的,这样可以更好地收敛模型。
我们可以将这些变换集成到transformer函数中,如下面的代码块所示:
def transformer(image, label, params):
# previous transformations here
image, label = resize_img_label(image, label, params["target_size"])
if random.random() < params["p_hflip"]:
image, label = random_hflip(image, label)
if random.random() < params["p_vflip"]:
image, label = random_vflip(image, label)
if random.random() < params["p_shift"]:
image, label = random_shift(image, label, params["max_translate"])
if random.random() < params["p_brightness"]:
brightness_factor = 1+(np.random.rand()*2-1)*params["brightness_factor"]
image = TF.adjust_brightness(image, brightness_factor)
if random.random() < params["p_contrast"]:
contrast_factor = 1+(np.random.rand()*2-1)*params["contrast_factor"]
image = TF.adjust_contrast(image, contrast_factor)
if random.random() < params["p_gamma"]:
gamma = 1+(np.random.rand()*2-1)*params["gamma"]
image = TF.adjust_gamma(image, gamma)
if params["scale_label"]:
label = scale_label(label, params["target_size"])
image = TF.to_tensor(image)
return image, label
# 使用transformer函数变换图像
np.random.seed(0)
random.seed(0)
# load image and label
img,label = load_img_label(labels_df,1)
# 设置变换参数并应用变换参数
params = {
"target_size": (256, 256),
"p_hflip": 1.0,
"p_vflip": 1.0,
"p_shift": 1.0,
"max_translate": (0.5,0.5),
"p_brightness": 1.0,
"brightness_factor":0.8,
"p_contrast":1.0,
"contrast_factor":0.8,
"p_gamma":1.0,
"gamma":0.4,
"scale_label":False
}
img_t, label_t = transformer(img, label, params)
plt.sublot(1,2,1)
show_img_label(img,label,w_h=(150,150),thickness=20)
plt.subplot(1,2,2)
show_img_label(TF.to_pil_image(img_t),label_t)

# 最后使用以下函数将标签缩放到以前尺寸
def rescale_label(a,b):
# a->[0,1] b->[w, h]
div=[ai*bi for ai,bi in zip(a,b)]
return div
创建自己的数据集
在这个教程里面,使用torch.utils.data中的Dataset类创建自己的数据集。我们可以通过实现Dataset类的子类并覆盖Dataset类中的__init__和__getitem__函数来做到这一点。__len__函数返回数据集的长度,并且可以通过Python的len函数调用。__getitem__函数返回指定索引处的图像。然后,我们将使用torch.utils.data中的Dataloader类来创建数据加载器。使用数据加载器,我们可以自动获得小批数据进行处理。
1.定义一个自定义数据集类。
# 首先,加载所需的包:
from torch.utils.data import Dataset
from PIL import Image
# 然后定义数据集类的大部分
class AMD_dataset(Dataset):
def __init__(self, path2data, transform, trans_params):
pass
def __len__(self):
return len(self.labels)
def __getitem__(self,idx):
pass
# 下一步,定义__init__函数
def __init__(self, path2data, transform, trans_params):
path2labels = os.path.join(path2data, "Training400_labels", "Fovea_location.xlsx")
labels_df = pd.read_excel(path2labels, index_col="ID")
self.labels = labels_df[["Fovea_X", "Fovea_Y"]].values
self.imgName = labels_df["imgName"]
self.ids = labels_df.index
self.fullPath2img = [0]*len(self.ids)
for id_ in self.ids:
if self.imgName[id_][0]=="A":
prefix = "AMD"
else:
prefix = "Non-AMD"
self.fullPath2img[id_-1]=os.path.join(path2data, "Training400", prefix, self.imgName[id_])
self.transform = transform
self.trans_params = trans_params
# 下一步定义__getitem__函数
def __getitem__(self, idx):
image = Image.open(self.fullPath2img[idx])
label = self.labels[idx]
image,label = self.transform(image, label, self.trans_params)
return image, label
# 然后,覆盖相关函数
AMD_dataset.__init__==__init__
AMD_dataset.__getitem__==__getitem__
- 下一步,创建AMD_dataset的两个对象
# 为训练集定义变换参数
trans_params_train = {
"target_size":(256,256),
"p_hflip":0.5,
"p_vflip":0.5,
"p_shift":0.5,
"max_translate":(0.2, 0.2),
"p_brightness":0.5,
"brightness_factor":0.2,
"p_contrast":0.5,
"contrast_factor":0.2,
"p_gamma":0.5,
"gamma":0.2,
"scale_label":True,
}
# 为验证集定义变换参数
trans_params_val = {
"target_size":(256,256),
"p_hflip":0.,
"p_vflip":0.,
"p_shift":0.,
"p_brightness":0.,
"p_contrast":0.,
"p_gamma":0.,
"gamma":0.,
"scale_label":True,
}
# 定义两个AMD_dataset类对象
amd_ds1 = AMD_dataset(path2data, transformer, trans_params_train)
amd_ds2 = AMD_dataset(path2data, transformer, trans_params_val)
- 将数据集分为训练集和验证集
from sklearn.model_selection import ShuffleSplit
sss = ShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
indices = range(len(amd_ds1))
for train_index, val_index in sss.split(indices):
print(len(train_index))
print("-"*10)
print(len(val_index))
# 320
#----------
# 80
from torch.utils.data import Subset
train_ds = Subset(amd_ds1, train_index)
print(len(train_ds))
val_ds = Subset(amd_ds2, val_index)
print(len(val_index))
# 320
# 80
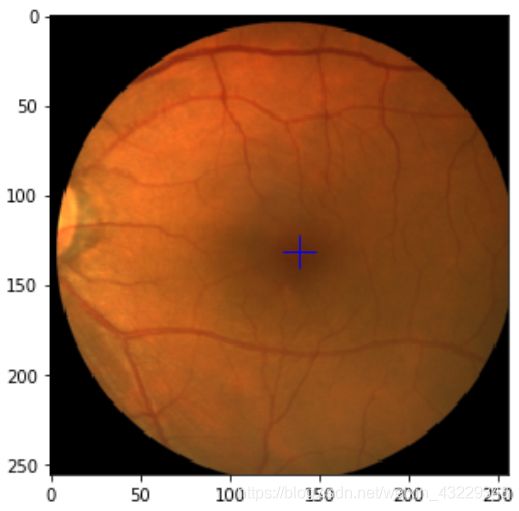
- 显示train_ds 和val_ds的样本图像
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(0)
# 定义一个函数显示图像和标签
def show(img, label=None):
npimg = img.numpy().transpose((1,2,0))
plt.imshow(npimg)
if label is not None:
label = rescale_label(label, img.shape[1:])
x,y=label
plt.plot(x,y,'b+',markersize=20)
# 显示train_ds的图片
plt.figure(figsize=(5,5))
for img,label in train_ds:
show(img, label)
break
- 接下来,我们将为训练和验证数据集定义两个数据加载器
from torch.utils.data import DataLoader
train_dl = DataLoader(train_ds, batch_size=8, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=16, shuffle=False)
- 获取train_dl中的一个batch数据
for img_b, label_b in train_dl:
print(img_b.shape, img_b.dtype)
print(label_b)
break
# torch.Size([8, 3, 256, 256]) torch.float32
#[tensor([0.5291, 0.4909, 0.4503, 0.6669, 0.6911, 0.5623, 0.5050, 0.6388],dtype=torch.float64)
#,tensor([0.4875, 0.5098, 0.3617, 0.7018, 0.7039, 0.4745, 0.4944, 0.6458],dtype=torch.float64)]
# 注意到,每批标签返回的是list列表,使用以下代码转换为tensor
import torch
# extract a batch from training data
for img_b, label_b in train_dl:
print(img_b.shape, img_b.dtype)
# convert list to tensor
label_b = torch.stack(label_b, 1)
label_b = label_b.type(torch.float32)
print(label_b.shape, label_b.dtype)
break
# torch.Size([8, 3, 256, 256]) torch.float32
# torch.Size([8, 2]) torch.float32
- 获取val_dl中的一个batch数据
for img_b, label_b in val_dl:
print(img_b.shape, img_b.dtype)
# convert to tensor
label_b = torch.stack(label_b,1)
label_b=label_b.type(torch.float32)
print(label_b.shape, label_b.dtype)
break
# torch.Size([16, 3, 256, 256]) torch.float32
# torch.Size([16, 2]) torch.float32
代码解析:
在步骤1中,我们定义了自定义数据集类。为了提高代码可读性,我们在几个片段中介绍了这一步。我们首先定义了数据集类的大部分。然后,我们实现了__init__函数。在这个函数中,我们从
Fovea_location.xlsx文件中读取相应坐标作为数据标签并保存在self.labels中。为了能够从本地文件中加载图像,我们还可以在self.fullPath2img中获得图像的完整路径。在AMD文件夹中有89张图片,它们的名字以字母A开头,其余的在Non-AMD文件夹中,它们的名字以字母N开头。因此,我们使用第一个字母来查找图像文件夹,并设置相应的前缀。最后,我们设置了变换函数和变换参数。接下来,我们定义了__getitem__函数。在这个函数中,我们加载一个图像及其标签,然后使用transformer函数对它们进行变换。最后,我们用__init__和__getitem__重写了这两个类函数。
在步骤2中,我们创建了AMD_dataset类的两个对象,这是用于数据分割的目的。我们定义了两个转换参数,trans_params_train和trans_params_val,并将它们分别传递给两个实例。trans_params_train定义了我们想要应用到训练数据集的变换。因此,我们以0.5的概率启用了实现的变换函数。另一方面,trans_params_val定义了我们想要应用于验证集上的变换方法。因此,我们通过将其概率设置为0.0来禁用所有数据增强函数。对于训练数据集和验证数据集,仅仅将图像的大小调整为256256和缩放标签的范围为[0,1]。
在步骤3中,我们将图像分成训练集和验证数据集两组。为此,我们首先使用sklearn中的ShuffleSplit分割图像索引。我们将20%的图像分配给验证数据集。结果是320张用于训练的图像和80张用于评估的图像。然后,我们利用torch.utils的subset类,获得从amd_ds1数据集在train_index索引处的train_ds。类似地,获得从amd_ds2数据集在val_index索引处的val_ds。注意,train_ds继承了amd_ds1的transformer函数,而val_ds继承了amd_ds2的transformer函数。到目前为止,您应该清楚了为什么我们首先定义了AMD_dataset类的两个实例:为训练和验证数据集提供不同的变换函数。如果只定义数据集类的一个对象并传递不同的索引,它们将具有相同的转换函数。
在第4步中,我们描述了来自train_ds和val_ds的示例图像。我们定义了一个辅助函数来显示张量图像,并将其标签作为+标记。张量是CHW,所以我们把它重塑为HW*C。标签包含重新缩放的x和y坐标。因此,我们将其重新调整为图像大小。我们首先描绘了来自train_ds的一个示例图像。如果您重新运行此代码片段,您应该会看到由于随机转换而产生的示例图像的不同版本。接下来,我们展示了来自val_ds的示例图像。验证数据集没有随机转换,因此如果重新运行此代码片段,您应该会看到相同的图像。
在步骤5中,我们定义了两个用于训练和验证数据集的数据加载器。在训练和评估期间,数据加载器自动从训练和验证数据集中获取小批量数据。创建PyTorch数据加载器非常简单。只需传递数据集并定义批处理大小。训练数据集的批处理大小被认为是一个超参数。因此,您可能希望尝试不同的值以获得最佳性能。对于验证数据集,批处理大小不会对性能产生任何影响。
在步骤6和步骤7中,我们从train_dl和val_dl中获得一批数据。如前所述,标签批处理作为列表返回。我们需要一个torch.float32类型张量。因此,我们将列表转换为张量,并根据需要改变它的类型。注意,根据预先设置的批处理大小,我们从train_dl获得8个样本的批处理,从val_dl获得16个样本的批处理。
构建模型
在这个教程中,将为单目标检测问题构建一个模型来预测图像中目标的中心点x和y坐标。我们将为这个任务构建一个由几个卷积层和池层组成的模型,如下图所示:
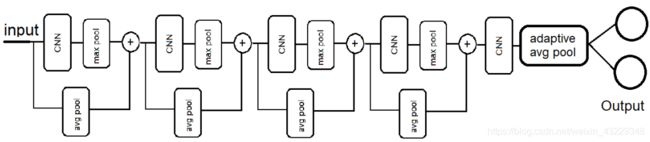
该模型将接收一个调整大小后的RGB图像,并提供两个线性输出。如果您对预测边界框的宽度或高度感兴趣,您可以简单地将输出数量增加到4。在我们的模型中,我们将利用ResNet中所谓的跳跃连接技术。
#1. 导入相应的包
import torch.nn as nn
import torch.nn.functional as F
#2.定义模型类的大部分框架
class Net(nn.Module):
def __init__(self, params):
super(Net, self).__init__()
def forward(self, x):
return x
#3. 定义__init__函数
def __init__(self, params):
super(Net, self).__init__()
C_in,H_in,W_in=params["input_shape"]
init_f=params["initial_filters"]
num_outputs=params["num_outputs"]
self.conv1 = nn.Conv2d(C_in, init_f, kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(init_f+C_in, 2*init_f, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(3*init_f+C_in, 4*init_f, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(7*init_f+C_in, 8*init_f, kernel_size=3, stride=1, padding=1)
self.conv5 = nn.Conv2d(15*init_f+C_in, 16*init_f, kernel_size=3, stride=1, padding=1)
#4. 定义forward函数
def forward(self, x):
identity = F.avg_pool2d(x, 4, 4)
x = F.relu(self.conv1(x))
x = F.max_pool2s(x, 2, 2)
x = torch.cat((x, identity), dim=1)
identity = F.avg_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2s(x, 2, 2)
x = torch.cat((x, identity), dim=1)
identity = F.avg_pool2d(x, 2, 2)
x = F.relu(self.conv3(x))
x = F.max_pool2s(x, 2, 2)
x = torch.cat((x, identity), dim=1)
identity = F.avg_pool2d(x, 2, 2)
x = F.relu(self.conv4(x))
x = F.max_pool2s(x, 2, 2)
x = torch.cat((x, identity), dim=1)
x = F.relu(self.conv5(x))
x = F.adaptive_avg_pool2d(x,1)
x = x.reshape(x.size(0), -1)
x = self.fc1(x)
return x
#5. 覆盖Net类中的相关函数
Net.__init__=__init__
Net.forward=forward
#6. 创建Net类对象
params_model = {
"input_shape": (3, 256, 256),
"initial_filters": 16,
"num_outputs": 2,
}
model = Net(params_model)
# 将模型移到GPU设备上
if torch.cuda.is_available():
device = torch.device("cuda")
model = model.to(device)
print(model)
# Net(
# (conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
# (conv2): Conv2d(19, 32, kernel_size=(3, 3), stride=(1, 1),padding=(1, 1))
# (conv3): Conv2d(51, 64, kernel_size=(3, 3), stride=(1, 1),padding=(1, 1))
# (conv4): Conv2d(115, 128, kernel_size=(3, 3), stride=(1, 1),padding=(1, 1))
# (conv5): Conv2d(243, 256, kernel_size=(3, 3), stride=(1, 1),padding=(1, 1))
# (fc1): Linear(in_features=256, out_features=2, bias=True)
# )
代码解析:
在步骤1中,我们定义了模型Net类的框架。为了可读性,我们将代码显示为几个片段。首先,我们加载所需的包。然后,我们用两个主要函数定义了这个类:__init__和forward。接下来,我们在__init__函数中定义了模型的构建块,它有五个nn.Conv2d块。注意,我们在所有nn.Conv2d中设置padding=1,并保持输出大小能被2整除。在构建带有跳过连接的网络时,这一点非常重要。
同时,检查每个nn.Conv2d层的输入通道数。在跳过连接的情况下,输入通道的数量将是前一层输出通道和跳过层输出通道的总和。接下来,我们定义了层与层之间连接的前向函数。检查跳过连接是如何建立的。我们使用avg_pool2d来获取identity,它与x经过nn.Conv2d和F.max_pool2d后具有相同的大小。我们使用torch.cat将x与identity在dim=1维度堆叠起来。
当concatenating(堆叠)两个张量时,除了在堆叠维度外,其他维度必须有相同的形状。提醒一下,这里张量的形状是BCHW。
forward函数中有四个跳过连接块。最后一个卷积神经网络(CNN)块是一个没有跳过连接的nn.Conv2d层。CNN最后一层的输出通常被称为特征提取。然后,我们使用adaptive_avg_pool2d层对提取的特征进行自适应平均池化,得到输出大小为11。
对于任何输入大小,adaptive_avg_pool2d的输出大小将是您在其参数中指定的任何大小。然后,我们reshape或flatten特征,并将它们传递到linear层。因为我们预测的是坐标值,所以最后一层不需要激活。最后,我们覆盖了Net类的__init__和forward函数。
在步骤2中,我们定义了模型参数并创建了Net类的一个对象。我们决定将图像缩小到256256。您可以尝试不同的值,例如128128或512*512。此外,initial_filters(第一个CNN层中的滤波器数量)被设置为16,可以尝试8或其他值。输出的数量被设置为2,因为我们只预测两个坐标。您还可以将此模型用于另一个单对象检测问题,该问题有四个输出,以预测对象的宽度和高度。
接下来,我们将模型转移到CUDA设备上。最后,我们打印出模型。注意,print (model)不显示使用torch.nn.functional创建的函数层。
定义损失函数,优化器以及IOU度量
在这个教程中,我们将首先为我们的单目标检测问题定义一个损失函数。检测任务常用的损失函数是均方误差(MSE)和smoothed_L1损失。在smoothed_L1损失中,当MSE小于1时,使用L2损失,否则使用L1损失。smoothed_L1损失对异常值的敏感性低于MSE,在某些情况下,可以防止爆炸梯度。我们将使用smoothed_L1损失。
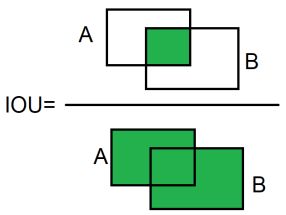
然后,我们将定义优化器来自动更新模型参数。最后,我们将为我们的对象检测定义一个性能度量即IOU。IOU的图示如下图所示:
#1. 首先我们定义损失函数
loss_func = nn.SmoothL1Loss(reduction="sum")
# 让我们试试已知值的loss:
n,c = 8, 2
y = 0.5 * torch.ones(n, c, requires_grad=True)
print(y.shape)
target = torch.zeros(n, c, requires_grad=False)
print(target.shape)
loss = loss_func(y, target)
print(loss.item())
y = 2*torch.ones(n, c, requires_grad=True)
target = torch.zeros(n, c, requires_grad=False)
loss = loss_func(y, target)
print(loss.item())
# 我们将打印如下结果
# torch.Size([8,2])
# torch.Size([8,2])
# 2.0
# 24.0
#2. 下一步,我们定义优化器
from torch import optim
opt = optim.Adam(model.parameters(), lr=3e-4)
# 定义一个函数获取当前的学习率
def get_lr(opt):
for param_group in opt.param_groups:
return param_group["lr"]
current_lr=get_lr(opt)
print("current lr={}".format(current_lr))
# current lr=0.0003
#3. 下一步,我们定义一个学习率策略
from torch.optim.lr_scheduler import ReduceLROnPlateau
lr_scheduler = ReduceLROnPlateau(opt, mode="min", factor=0.5, patience=20, versbose=1)
#我们检验一下结果
for i in range(100):
lr_scheduler.step(1)
# Epoch 21: reducing learning rate of group 0 to 1.5000e-04.
# Epoch 42: reducing learning rate of group 0 to 7.5000e-05.
# Epoch 63: reducing learning rate of group 0 to 3.7500e-05.
# Epoch 84: reducing learning rate of group 0 to 1.8750e-05.
#4. 下一步,我们将计算小批量数据的IOU
# 定义一个将坐标转换为bbox的函数
def cxcy2bbox(cxcy,w=50./256, h=50./256):
w_tensor = torch.ones(cxcy.shape[0], 1, device=cxcy.device)*w
h_tensor = torch.ones(cxcy.shape[0], 1, device=cxcy.device)*h
cx = cxcy[:,0].unsqueeze(1)
cy = cxcy[:,1].unsqueeze(1)
boxes = torch.cat((cx,cy,w_tensor, h_tensor), -1) # cx, cy, w, h
# 返回 xmin, ymin, xmax,ymax
return torch.cat((boxes[:, :2]-boxes[:,2:]/2, boxes[:, :2]+boxes[:,2:]/2), 1)
#我们检验一下结果
torch.manual_seed(0)
cxcy=torch.rand(1,2)
print("center:", cxcy*256)
bb = cxcy2bbox(cxcy)
print("bounding box", bb*256)
# center: tensor([[127.0417, 196.6648]])
# bounding box tensor([[117.0417, 186.6648, 137.0417, 206.6648]])
# 定义度量函数
import torchvision
def metrics_batch(output, target):
output = cxcy2bbox(output)
target = cxcy2bbox(target)
iou = torchvision.ops.box_iou(output, target)
return torch.diagonal(iou, 0).sum().item()
# 我们检验一下结果
n,c=8,2
target = torch.rand(n,c,device=device)
target = cxcy2bbox(target)
metrics_batch(target,target)
# 8.0
#5.定义loss_batch函数
def loss_batch(loss_func, output, target, opt=None):
loss = loss_func(output, target)
with torch.no_grad():
metric_b = metrics_batch(output, target)
if opt is not None:
opt.zero_grad()
loss.backward()
opt.step()
return loss.item(), metric_b
# 我们检验一下loss_batch结果
for xb, label_b in train_dl:
label_b = torch.stack(label_b, 1)
label_b = label_b.type(torch.float32)
label_b = label_b.to(device)
l,m = loss_batch(loss_func, label_b,label_b)
print(l,m)
break
# 0.0 8.0
代码解析:
在步骤1中,我们首先从torch.nn包中定义smoothed-L1损失函数。注意,我们使用reduction="sum"返回每个小批处理的损失之和。然后用已知值计算损失值。利用已知的输入和输出对损失函数进行单元测试总是有益的。在本例中,我们将预测设置为0.5或1.5值,目标值设置为全零值。对于批次大小为8和2的预测,这导致打印2.0和16.0。稍后,我们将使用loss.backward()来计算相对于模型参数的损失梯度。
在步骤2中,我们从torch.optim包中定义了一个Adam优化器。将模型参数和学习率赋给优化器。稍后,我们将使用.step方法使用此优化器自动更新模型参数。此外,我们还定义了一个函数来读取学习率以进行监控。
在步骤3中,我们定义了一个学习率策略来降低学习率。在这里,我们希望在损失减少时监控它,因此我们设置mode=“min”。我们还希望容忍patience=20个epoch,然后再将学习率降低到0.5倍。然后,我们通过修复.step(1)中的监控指标进行单元测试。正如预期的那样,学习速率每20个epoch就减半。
在步骤4中,我们用几个步骤开发了IOU函数。首先,我们定义了一个函数来创建一个给定中心坐标的边界框(width=height=20)。函数以这种格式返回一个边界框:[x0, y0, x1, y1],其中x0, y0,和x1, y1分别是边界框的左上角坐标和右下角坐标。记住,之前我们缩放了[0,1]范围内的坐标,所以我们对包围框的宽度和高度也做了相同的处理,即将它们除以256。
接下来,我们定义了metrics_batch来计算每个批大小的IOU。我们使用torchvision.ops.box_iou从边界框计算IOU。box_iou函数期望边界框的格式为[x0,y0,x1,y1]。我们还在已知值上测试函数,以确保它按照预期工作。因为batch size被设置为8,所以在完全重叠的情况下,它将返回8.0。
在步骤5中,我们定义了loss_batch函数。此功能将在训练和评估期间使用。它将返回每批大小的损失和IOU。并且在训练阶段对模型参数进行更新。我们还通过传递已知值给函数来对函数进行单元测试。在理想情况下,损失和IOU分别为0.0和8.0。
始终使用已知输入对损失函数、度量函数和其他辅助函数进行单元测试,并将结果与预期输出进行比较。
模型训练与评估
在前面的教程中,我们学习了如何创建数据集、建立模型、定义损失函数、IOU度量和优化器。现在是时候训练我们的模型了。为了提高代码的可读性,我们将定义一些辅助函数。
#1.首先,定义loss_epoch辅助函数
def loss_epoch(model, loss_func, dataset_dl, sanity_check=False,opt=None):
running_loss=0.0
running_metric=0.0
len_data=len(dataset_dl.dataset)
for xb, yb in dataset_dl:
yb = torch.stack(yb,1)
yb = yb.type(torch.float32).to(device)
output=model(xb.to(device))
loss_b,metric_b=loss_batch(loss_func,output,yb,opt)
running_loss+=loss_b
if metric_b is not None:
running_metric+=metric_b
if sanity_check is True:
break
loss=running_loss/float(len_data)
metric=running_metric/float(len_data)
return loss, metric
#2. 我们定义train_val函数
import copy
def train_val(model, params):
num_epochs=param["num_epochs"]
loss_func=params["loss_func"]
opt=params["optimizer"]
train_dl=params["train_dl"]
val_dl=params["val_dl"]
sanity_check=params["sanity_check"]
lr_scheduler=params["lr_scheduler"]
path2weights=params["path2weights"]
# 定义两个字典来存储每个batch的loss和度量值
loss_history={
"train":[],
"val":[],
}
metric_history={
"train":[],
"val":[],
}
# 定义两个变量来存储最好的模型以及最好的损失
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = float("inf")
for epoch in range(num_epochs):
current_lr = get_lr(opt)
print("Epoch {}/{}, current lr={}".format(epoch, num_epochs-1, current_lr))
model.train()
train_loss, train_metric=loss_epoch(model, loss_func,train_dl,sanity_check,opt)
loss_history["train"].append(train_loss)
metric_history["train"].append(train_metric)
model.eval()
with torch.no_grad():
val_loss, val_metric=loss_epoch(model, loss_func,val_dl, sanity_check)
loss_history["val"].append(val_loss)
metric_history["val"].append(val_metric)
if val_loss < best_loss:
best_loss = val_loss
best_model_wts = copy.deepcopy(model.state_dict())
torch.save(model.state_dict(), path2weights)
print("Copied best model weights!")
lr_scheduler.step(val_loss)
if current_lr != get_lr(opt):
print("Loading best model weights!")
model.load_state_dict(best_model_wts)
print("Train loss: %.6f, accuracy: %.2f"%(train_loss, 100*train_metric))
print("Val loss: %.6f, accuracy:%.2f"%(val_loss, 100*val_metric))
print("-"*10)
model.load_state_dict(best_model_wts)
return model, loss_history, metric_history
#3. 通过调用train_val函数训练模型
loss_func=nn.SmoothL1Loss(reduction="sum")
opt=optim.Adam(model.parameters(),lr=1e-4)
lr_scheduler = ReduceLROnPlateau(opt, mode="min", factor=0.5, patience=20, verbose=1)
path2models="./models/"
if not os.path.exists(path2models):
os.mkdir(path2models)
params_train={
"num_epochs": 100,
"optimizer":opt,
"loss_func":loss_func,
"train_dl":train_dl,
"val_dl":val_dl,
"sanity_check":False,
"lr_scheduler":lr_scheduler,
"path2weights":path2models+"weights+smoothl1.pt",
}
model, loss_hist,metric_hist=train_val(model,params_train)
# Epoch 0/99, current lr=0.0001
# Copied best model weights!
# train loss: 0.073063, accuracy: 13.08
# val loss: 0.017105, accuracy: 24.20
# ----------
# Epoch 1/99, current lr=0.0001
# Copied best model weights!
# train loss: 0.014088, accuracy: 31.04
# val loss: 0.009260, accuracy: 52.49
#4. 相关图绘制
# 绘制训练集损失与验证集损失
num_epochs=params_train["num_epochs"]
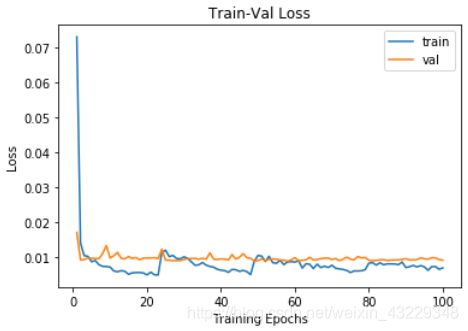
plt.title("Train-Val Loss")
plt.plot(range(1, num_epochs+1), loss_hist["train"], label="train")
plt.plot(range(1, num_epochs+1), loss_hist["val"], label="val")
plt.ylabel("Loss")
plt.xlabel("Training Epochs")
plt.legend()
plt.show()
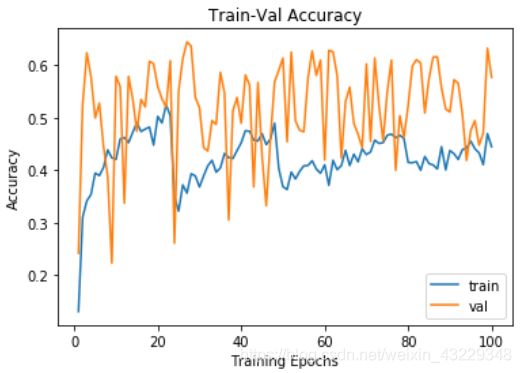
# 绘制IOU
plt.title("Train-Val Accuracy")
plt.plot(range(1, num_epochs+1), metric_hist["train"],label="train")
plt.plot(range(1, num_epochs+1), metric_hist["val"],label="val")
plt.ylabel("Accuracy")
plt.xlabel("Training Epochs")
plt.legend()
plt.show()
代码解析:
在步骤1中,我们定义了一个辅助函数来计算每个epoch的损失和IOU度量值。该函数将用于训练和验证数据集。对于验证数据集,如果将opt=None传递给函数,则不会执行任何优化。在函数中,循环从数据加载器中获得成批的数据。记住,我们需要把标签转换成张量。然后,获得模型输出并利用loss_batch函数计算每个小批的损失和IOU。
在步骤2中,为了提高代码的可读性, 我们用几步来定义train_val函数。函数的输入是模型和训练参数。我们从params中提取了相关参数。然后,我们定义了loss_history和metric_history来记录训练过程中的损失和度量值。在训练过程中,我们希望保存最好的模型参数。因此,我们定义了best_model_wts来存储最佳模型参数。为了能够跟踪模型的性能,我们需要保存最佳的损失值。对于第一个epoch,没有之前的损失值,所以我们将best_loss初始化为一个较大的数字或“inf”。然后,主循环开始,运行num_epochs迭代。我们在一开始就打印了当前的学习速率,以保持对它的关注。然后将模型设置为训练模式,对模型进行训练。这意味着计算损失值并使用优化器更新模型参数,所有这些都发生在前面描述的loss_epoch函数中。接下来,我们将模型设置为评估模式,并对验证数据进行评估。这一次,不需要梯度计算和优化。
不要忘记根据需要使用.train()和.eval()方法将模型设置为正确的模式。
每次评估后,我们将当前的验证损失与最佳损失值进行比较,如果观察到更好的损失,则存储模型参数。接下来,我们将验证损失传递给学习率计划。如果验证损失保持20个epoch不变,学习率策略将学习率降低到原来的1/2。同时,我们还打印了每个阶段的进度,以监控训练过程。最后,循环结束,我们返回最佳性能模型以及保存损失和度量值的字典。
不要忘记在模型评估过程中通过使用torch.no_grad():代码块来阻止autograd计算梯度。
在第3步中,我们使用train_val函数来训练模型。我们以pickle文件的形式存储模型参数。然后在params_train中定义训练参数。如果想快速执行函数并修复任何可能的错误,可以将sanity_check标志设置为True。这样在一个小批处理之后就会退出该epoch的训练,这意味着循环执行得更快。然后,您可以设置sanity_check=False。正如所观察到的,损失值和度量值被打印出来了。
在步骤4中,我们绘制了训练和验证损失值和IOU值。这些图显示了训练和评估的进展情况。
模型部署
在这个教程中,我们将部署模型。我们将考虑两种部署案例:部署在PyTorch数据集上,以及部署在本地存储的单个图像上。
由于没有可用的测试数据集,我们将在部署期间使用验证数据集。我们假设您希望将用于推理的模型部署在一个新脚本中,而不是训练脚本。在这种情况下,在内存中不存在数据集和模型。为了避免重复,我们将在本节跳过定义数据集和模型。按照创建自定义数据集和创建模型教程中的说明,在部署脚本中定义验证数据集和模型。在下面的脚本中,我们假设您已经为定义了Net模型,为验证数据集定义了val_ds和val_dl。
#1. 创建Net类对象
params_model={
"input_shape":(2, 256, 256),
"initial_filters":16,
"num_outputs":2,
}
model = Net(params_model)
model.eval()
# 将模型移到GPU设备上
if torch.cuda.is_available():
device = torch.device("cuda")
model = model.to(device)
#2. 导入模型权重
path2weights="./models/weights.pt"
model.load_state_dict(torch.load(path2weights))
#3. 在验证集上测试模型
loss_func=nn.SmoothL1Loss(reduction="sum")
with torch.no_grad():
loss,metric=loss_epoch(model,loss_func,val_dl)
print(loss, metric)
# 0.008903446095064282 0.5805782794952392
#4. 接下来,我们将在val_ds的图像示例上部署模型
from PIL import ImageDraw
import numpy as np
import torchvision.transforms.functional as tv_F
np.random.seed(0)
import matplotlib.pyplot as plt
# 我们将定义一个函数来显示一个具有两个标签作为边界框的张量:
def show_tensor_2labels(img, label1, label2, w_h=(50, 50)):
label1=rescale_label(label1, img.shape[1:])
label2=rescale_label(label2, img.shape[1:])
img = tv_F.to_pil_image(img)
w,h = w_h
cx,cy=label1
draw = ImageDraw.Draw(img)
draw.rectangle(((cx-w/2, cy-h/2), (cx+w/2, cy+h/2)), outline="green",width=2)
cx,cy=label2
draw.rectangle(((cx-w/2, cy-h/2), (cx+w/2, cy+h/2)), outline="red",width=2)
plt.imshow(np.asarray(img))
# 随机获取样本索引
rndInds = np.random.randint(len(val_ds), size=10)
print(rndInds)
# [44 47 64 67 67 9 21 36 70 12]
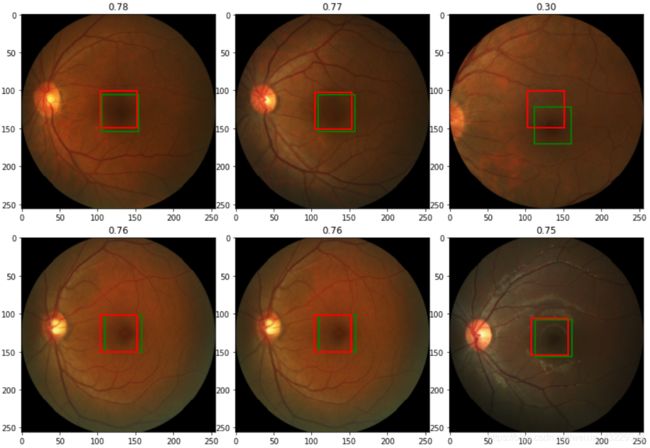
# 接下来,我们将在样本上部署模型,并将预测与ground truth一起显示
plt.rcParams["figure_figsize"] = (15, 10)
plt.subplots_adjust(wspace=0.0, hspace=0.15)
for i,rndi in enumerate(rndInds):
img,label=val_ds[rndi]
h,w=img.shape[1:]
with torch.no_grad():
label_pred=model(img.unsqueeze(0).to(device))[0].cpu()
plt.subplot(2,3,i+1)
show_tensor_2labels(img, label, label_pred)
#calculate IOU
label_bb = cxcy2bbox(torch.tensor(label).unsqueeze(0))
label_pred_bb=cxcy2bbox(label_pred.unsqueeze(0))
iou=torchvision.ops.box_iou(label_bb, label_pred_bb)
plt.title("%.2f"%iou.item())
if i>4:
break
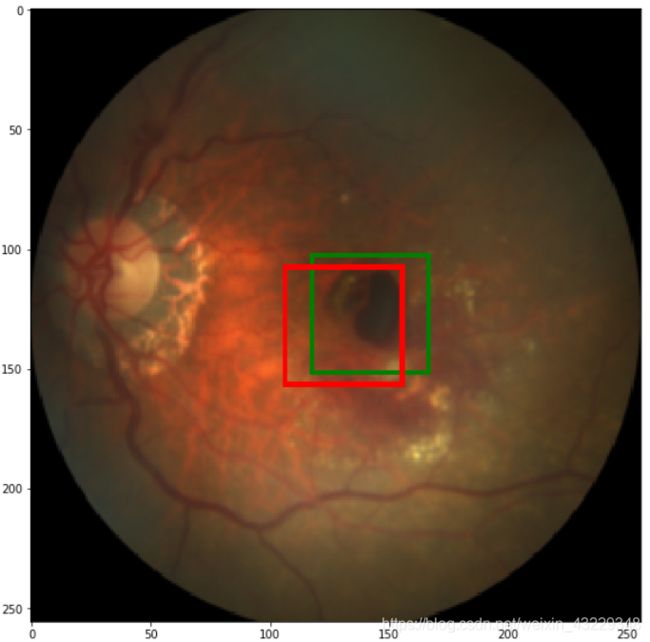
#5. 在单张样本上进行推理
path2labels=os.path.join(path2data, "Training400", "Fovea_location.xlsx")
labels_df = pd.read_excel(path2labels, index_col="ID")
img,label=load_img_label(labels_df,1)
print(img.size, label)
img,label=resize_img_label(img,label,target_size=(256,256))
print(img.size, label)
img=TF.to_tensor(img)
label=scale_label(label,(256,256))
print(img.shape)
with torch.no_grad():
label_pred=model(img.unsqueeze(0).to(device))[0].cpu()
show_tensor_2labels(img, label, label_pred)
#6. 计算推理时间
import time
elapsed_times=[]
with torch.no_grad():
for k in range(100):
start=time.time()
label_pred=model(img.unsqueeze(0).to(device))[0].cpu()
elapsed=time.time()-start
elapsed_times.append(elapsed)
print("inference time per image: %.4f s"%np.mean(elapsed_times))
# inference time per image: 0.0014 s
代码解析:
在步骤1中,我们创建了Net类的一个对象,并将其命名为model。我们假定您从创建模型教程中复制了Net类的脚本。注意,此时模型参数是随机初始化的。然后我们将模型转移到CUDA设备上进行加速处理。
在步骤2中,我们将模型参数从pickle文件加载到模型中。
在步骤3中,我们对模型在验证数据集上进行了评估,以验证前面的步骤。通常情况下,在模型权重的存储和加载过程中可能会出现错误。因此,在验证数据集上评估模型可以验证流程。这样做,你应该看到你在训练过程中观察到的相同的表现。这里,我们使用loss_epoch函数来获取验证数据集上的损失和度量。
在步骤4中,我们将模型部署到验证数据集上。不幸的是,我们没有测试数据集。我们定义了show_tensor_2labels函数在图像上显示预测值和真实值。该函数假定图像是一个PyTorch张量。我们使用torchvision的to_pill_image函数将张量转换为PIL图像。同样,记住,ground truth和预测被缩放到[0,1]的范围,所以我们将它们重新缩放到图像大小。然后,我们选取了一组随机索引。接下来,我们从val_ds中获得随机图像。当从val_ds中获得一个示例图像时,它将是3x256x256的形状,托管在CPU上。因此,我们使用unsqueeze(0)为其添加了一个新的维度,并在传递给模型之前将其移动到CUDA中。输出是预测的中心凹坐标。接下来,我们使用cxcy2bbox函数将坐标转换为边界框,以便能够计算IOU度量。计算出的IOU被打印在每张图像的顶部。
您可能还希望将模型部署在单张图像上。我们在第5步中演示了如何做到这一点。假设新图像存储在本地,我们将它作为PIL图像加载。然后,我们调整PIL图像为256*256。接下来,我们使用to_tensor方法将图像转换为PyTorch张量,并向其添加维度。最后将其传递到模型中,得到预测结果。
在步骤6中,我们想知道每个图像的推理时间。这是部署期间的一个重要因素。我们通过计算100次迭代中每张图像所消耗的平均时间来测量推理时间。在此提醒,结果显示的是使用GPU的推理时间。