智能计算系统实验(3) 综合实验-文本识别OCR-EAST
3.1 Split+Sub+Concat合并算子的BCL实现
3.1.1 需求分析
要实现这个算子,首先要知道这个算子具体要做什么。首先尝试读论文《EAST: An Efficient and Accurate Scene Text Detector》和《PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection》,从论文中大致读懂了算法的框架,如下图,但是并没有什么用:
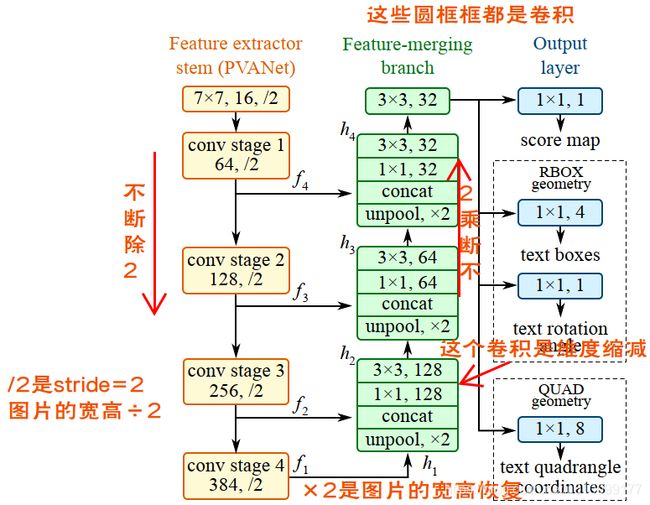
图3-1 算法框架
之后从eval Python脚本中查找相关信息,其中某处引用了model.py中的model(images, weight_decay, is_training)函数,然后逐渐发现mean_image_subtraction(images, means)就是我要找的函数:
代码3-1 Split-Sub-Concat算子的Python实现
def mean_image_subtraction(images, means=[123.68, 116.78, 103.94]):
'''
image normalization
:param images:
:param means:
:return:
'''
num_channels = images.get_shape().as_list()[-1] # 获取最后一个维度
if len(means) != num_channels:
raise ValueError('len(means) must match the number of channels')
# 在channel维度上拆分
channels = tf.split(axis=3, num_or_size_splits=num_channels, value=images)
for i in range(num_channels):
channels[i] -= means[i] # 每个通道减不同的数字
return tf.concat(axis=3, values=channels)
从上述代码中可以看出,算子首先需要在通道上拆分,然后3个通道分别减去means的3个值,最后再拼接。
然后要计算means值:对每一张图片求平均,还是一个常数?从Python代码中发现是常数,所以这个means值应该是一个图片数据集所有图片的平均,不能自己计算。
另外还需要知道图像的batch、宽、高和通道分别在哪个维度上。从channels = tf.split(axis=3,...)中可以看出通道在第3个维度,另外按照习惯,第0个维度是batch_size,第1个维度是宽度,第2个维度是高度。从main.cpp中得知,图像的宽度是1280,高度是672。
3.1.2 算子设计
由于图像数据的排列方式,means的3个数字是交错的。而MLU处理连续的数据比较迅速,所以简单的对每个位置求余数,根据余数减去相应的值,耗时一定会比较长。

图3-2 图像数据和平均值的位置关系
所以需要在nram上构造一些数据块,以便进行整体的减法。这样的话需要(1)决定每个块的大小,(2)如何对块赋值。
对于问题(1),根据MLU的要求,块的大小需要是16的倍数;其次,为了让每次迭代,图像都减去相同的数据块,块大小需要是3的倍数;最后,在taskdim为16的情况下,nram块的大小不能超过512。因此我决定设置块大小为384=128×3。
对于问题(2),最简单的思路是用for循环,如下所示:
代码3-2 用for循环对减数赋值
__nram__ minuse[384];
for(int i = 0; i < 384; ++i) {
switch(i % 3) {
case 0: minuse[i] = VALUE1; break;
case 1: minuse[i] = VALUE2; break;
case 2: minuse[i] = VALUE3; break;
}
}
但是经过测试,这样的延迟比较高。所以我考虑不用计算的方式,而是直接赋值。所以我用下面的代码来生成代码,粘贴到mlu文件中。
代码3-3 用于生成代码的Python脚本
values = ["(half)123.68", "(half)116.78", "(half)103.94"]
for i in range(384):
print("minused_nram[%d] = %s;" % (i, values[i%3]))
代码3-4 生成的部分代码
minused_nram[0] = (half)123.68;
minused_nram[1] = (half)116.78;
minused_nram[2] = (half)103.94;
minused_nram[3] = (half)123.68;
minused_nram[4] = (half)116.78;
minused_nram[5] = (half)103.94;
......
接下来要对这种方法的速度进行测试,首先在使用这种方法的情况下,查看运行时间,然后把这些赋值的代码全部注释掉,再查看运行时间。经过比较得到结论:这种方法的速度是比较快的。
数据块构造完成之后如何做减法。BANGC提供了__bang_cycle_sub,其功能是,假设有长度 m × n m×n m×n的被减数数组和长度为 n n n的减数数组,则将被减数数组拆分成 m m m份,分别减去减数数组。同时为了减少拷贝次数,我将块大小乘了64倍,但是减数minused_nram保持不变。运行结果见图3-2。
代码3-5 用__bang_cycle_sub做减法
#define ONELINE 384
#define MUCH_DOUBLE 64
int quotient = batch_num_ * 1280 * 672 * 3 / ONELINE;
__nram__ half input_nram[ONELINE * MUCH_DOUBLE];
quotient = quotient / MUCH_DOUBLE;
for (int32_t i = taskId; i < quotient; i += taskDim) {
offset = i * ONELINE * MUCH_DOUBLE;
// 查看是否遍历了所有数据
// __bang_printf("loop1 %d\t%d\t%d\n", taskId, i, offset);
__memcpy(input_nram, input_data_ + offset,
MUCH_DOUBLE * ONELINE * sizeof(half), GDRAM2NRAM);
__bang_cycle_sub(input_nram, input_nram, minused_nram,
ONELINE * MUCH_DOUBLE, ONELINE);
__memcpy(output_data_ + offset, input_nram,
MUCH_DOUBLE * ONELINE * sizeof(half), NRAM2GDRAM);
}
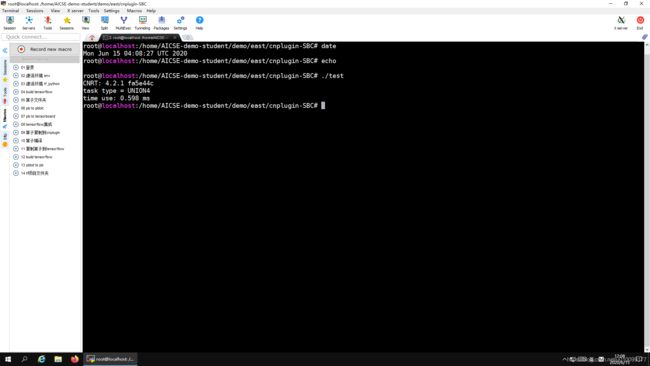
图3-2 算子测试
3.2 算子集成
算子集成分为两步,用BCL将上述算子集成到CNPlugin中,和通过CNPlugin接口集成到TensorFlow框架中。
3.2.1 集成到CNPlugin框架
补全plugin_sbc_op.cc文件:
对于cnmlCreatePluginSBCOp函数,首先获得Kernel的ParamsBuffer,然后根据算子的函数声明,将第一个参数标记为Input,将第二个参数标记为Output,然后传入第三个参数batch_num_。然后用cnmlCreatePluginOp创建算子。
代码3-6 cnmlCreatePluginSBCOp函数
// 补全cnmlCreatePluginSBCOp
cnrtKernelParamsBuffer_t params;
cnrtGetKernelParamsBuffer(¶ms);
cnrtKernelParamsBufferMarkInput(params);
cnrtKernelParamsBufferMarkOutput(params);
cnrtKernelParamsBufferAddParam(params, &batch_num_, sizeof(int));
// 由于main.cpp中只添加了3个参数,所以core_num_应该是不用添加的
cnmlCreatePluginOp(
op, "SBC",
reinterpret_cast<void **>(&SBCKernel), params,
SBC_input_tensors, 1,
SBC_output_tensors, 1,
nullptr, 0
);
cnrtDestroyKernelParamsBuffer(params);
对于cnmlComputePluginSBCOpForward函数,调用cnmlComputePluginOpForward_V4即可。
代码3-7 cnmlComputePluginSBCOpForward函数
// 补全cnmlComputePluginSBCOpForward
cnmlComputePluginOpForward_V4(
op,
nullptr, inputs, input_num,
nullptr, outputs, output_num,
queue, nullptr
);
补全cnplugin.h文件:
定义cnmlPluginSBCOpParam_t结构体,如下
代码3-8 cnmlPluginSBCOpParam结构体定义
struct cnmlPluginSBCOpParam {
int batch_num_;
cnmlCoreVersion_t core_version;
};
typedef cnmlPluginSBCOpParam *cnmlPluginSBCOpParam_t;
添加函数声明,如下
代码3-9 cnml函数声明
cnmlStatus_t cnmlCreatPluginSBCOpParam(
cnmlPluginSBCOpParam_t *param,
int batch_num_);
cnmlStatus_t cnmlDestroyPluginSBCOpParam(
cnmlPluginSBCOpParam_t *param);
cnmlStatus_t cnmlCreatePluginSBCOp(
cnmlBaseOp_t *op,
//cnmlPluginSBCOpParam_t param,
cnmlTensor_t *SBC_input_tensors,
cnmlTensor_t *SBC_output_tensors,
int batch_num_);
cnmlStatus_t cnmlComputePluginSBCOpForward(
cnmlBaseOp_t op,
void **inputs,
int input_num, // == 1
void **outputs,
int output_num, // == 1
cnrtQueue_t queue);
然后将算子的文件拷贝到相关文件夹中,进行算子编译。在编译中出现了错误:tensorflow/stream_executor/mlu/mlu_api/lib_ops/mlu_lib_ops.cc:1926:96: error: 'cnmlCreatePluginPowerDifferenceOp' was not declared in this scope
过思考后发现,这个错误应该是mlu_lib_ops.cc调用了PowerDifference算子,而cnplugin.h中没有PowerDifference算子的信息。所以我将实验一中PowerDifference算子的声明也添加到了cnplugin.h中,顺利解决了此问题。
3.2.2 集成到TensorFlow框架
将CNPlugin的libcnplugin.so文件、cnplugin.h文件以及tf-SBC文件夹中的文件复制到TensorFlow的相关目录中,对TensorFlow进行编译即可。
3.3 PB模型修改
用实验提供的工具,将PB模型转换成TF Events文件,然后用TensorBoard打开。
 |
 |
|---|---|
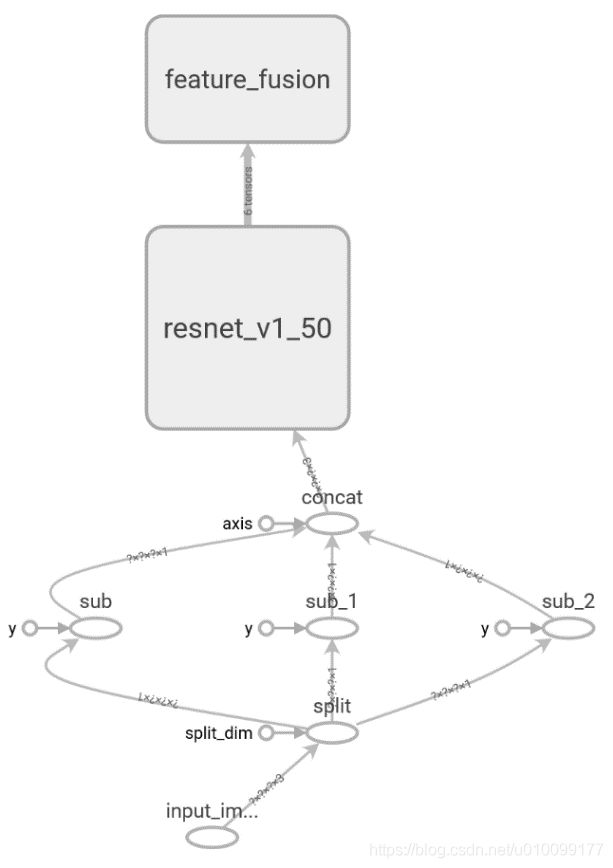
| 图3-3 修改前的PB模型 | 图3-4 修改后的PB模型 |
从图3-3中可以看出,split节点、3个sub节点和concat节点都要被删除,然后添加SBC节点。由于eval.py的第177行concat = tf.get_default_graph().get_tensor_by_name("concat:0")对concat节点进行了引用,所以不得不把新添加的节点命名为concat。
然后把PB模型转换为pbtxt文件,从节点(name:"split/split_dim")开始注释,直到节点(name:"concat")结束。然后添加新节点:
代码3-10 PB模型的SBC节点
node {
name: "concat"
op: "SBC"
input: "input_images"
attr {
key: "T"
value {
type: DT_FLOAT
}
}
}
添加完之后再用TensorBoard进行展示,见图3-4。可以看到替换成功了。刚开始我用Sublime编辑器进行修改,运行会报错,后来换成vim,问题解决。
关于上面的节点具体内容,比如op是大写还是小写、attr中key-value分别填什么,我是通过写一个简单模型(代码3-11)导出PB模型、转换成pbtxt格式知道的。
代码3-11 能够输出SBC节点的Python脚本
import tensorflow as tf
from tensorflow.python.framework import graph_util
v1=tf.Variable(tf.constant(1.0,shape=[1]),name='v1')
v2=tf.sbc(v1, name='sbc')
init_op=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init_op)
graph_def=tf.get_default_graph().as_graph_def()
output_graph_def=graph_util.convert_variables_to_constants(sess, graph_def, ['sbc'])
with tf.gfile.GFile('model/model.pb','wb') as f:
f.write(output_graph_def.SerializeToString())
3.4 框架推理测试
按照视频的说明,对run.sh中模型路径进行修改,然后对run_aicse.sh的核数进行修改。

图3-5 运行推理测试
上图中添加了grep -E 'fps|recall',所以图3-6中输出被简化了。下表是新旧模型的比较。所有误差都在0.1%以内。
表3-1 模型的比较
| 原始模型 单核 | SBC 单核 | SBC 16核 | |
|---|---|---|---|
| Net FPS | 6.067 | 7.661 | 12.858 |
| Net 延时 | 164.8 ms | 130.5 ms | 77.8 ms |
| End2End FPS | 4.812 | 5.468 | 8.444 |
| End2End 延时 | 207.8 ms | 182.9 ms | 118.4 ms |
| 召回率 | 0.767453 | 0.767453 | 0.767935 |
| 精度 | 0.836306 | 0.836306 | 0.836392 |
| hmean | 0.800402 | 0.800402 | 0.800703 |

图3-6 运行结果