文章简要阐述了论文的目的:元学习目前的典型背景算法在执行过程中假设任务分布是一种固定的训练。而为了提高对于真实世界的泛化能力,本文实现了具有困难意识的一系列不平衡领域的元学习,为此,作者通过探索了一种更实际、更具挑战性,其中任务分布会发生变化的环境。为此作者们做了以下几件事情:
1、提出了一个新的具有挑战性的基准,包括不平衡域序列。
2、提出了一种新的机制,“具有域分布和困难感知的内存管理”,以最大限度地保留以前的知识内存缓冲区中的域。
3、提出了一种高效的自适应任务抽样方法。此方法的作用在元训练期间,在理论保证的情况下,显著降低了总体估计方差,使元训练过程更加稳定,提高模型性能。
4、而作者所给出的方法特定元学习是正交的方法,并且可以与它们无缝集成。
对于问题的解决呢作者通过一系列小批量培训任务进行了简要的说明,读者可以自行阅读以下:
A series of mini-batch training tasks
T
1
,
T
2
, . . . ,
T
N
arrive sequentially, with possible domain shift occurring in the
stream, i.e., the task stream can be segmented by continual la
tent domains,
D
1
,
D
2
, . . . ,
D
L
.
T
t
denotes the mini-batch of
tasks arrived at time
t
. The domain identity associated with
each task remains unavailable during both meta training and
testing. Domain boundaries, i.e., indicating current domain
has finished and the next domain is about to start, are un
known. This is a more practical and general setup. Each task
T
is divided into training and testing data
{T
train
,
T
test
}
.
Suppose
T
t train
consists of
K
examples,
{
(
x
k
,
y
k
)
}
K
k
=1
,where in object recognition,
x
k
is the image data and
y
k
is
the corresponding object label. We assume the agent stays
within each domain for some consecutive time. Also, we
consider a simplified setting where the agent will not re
turn back to previous domains and put the contrary case
into future work. Our proposed learning system maintains a
memory buffer
M
to store a small number of training tasks
from previous domains for replay to avoid forgetting of pre
vious knowledge. Old tasks are not revisited during training unless they are stored in the memory
M
. The total num
ber of tasks processed is much larger than memory capacity.
At the end of meta training, we randomly sample a large
number of
unseen few-shot tasks
from each latent domain,
D
1
,
D
2
, . . . ,
D
L
for meta testing. The model performance is the average accuracy on all the sampled tasks.

作者所认为元学习所面对的挑战包括:
(1)任务分布在不同领域之间的变化;
(2) 以前域中的任务通常是在新域上进行培训时不可用;
(3) 号码每个领域的任务数量可能高度不平衡;
(4) 不同领域的难度在性质上可能存在显著差异域序列。
而上图从作者给出的实例中可以看出D1,D2,D3到DL我们将他们分成很多域,而他们之间的域的不同使得所训练的不再适应其他场景,但又需要适应新的环境。基于此,作者在这项工作中,考虑一个更现实的问题设置来应对这些挑战,即:
(1) 在网上学习结构域序列;
(2) 任务流包含重要的域名大小不平衡;
(3) 域标签和边界在培训和测试期间仍然不可用;
(4) 主要困难在于跨域序列的非均匀性。
这种问题设置为序列上的元学习具有不同难度的不平衡域(MLSID)。MLSID需要元学习模型,以适应一个新的领域,并保留识别来自以前的域对象的能力。这也是上图中无法做到的,各个域之间我们称之为域差异。
而作者们的贡献也就显得极为巨大了:
•这是meta的第一项工作学习一系列不平衡的领域。建议对不同的模型进行方便的评估一个新的具有挑战性的基准,包括不平衡域序列。
•提出了一种新的机制,“具有域分布和困难感知的内存管理”,以最大限度地保留以前的知识内存缓冲区中的域。
•提出了一种高效的自适应任务抽样方法在元训练期间,在理论保证的情况下,显著降低了总体估计方差,使元训练过程更加稳定,提高模型性能。
•方法与特定元学习是正交的方法,并且可以与它们无缝集成。
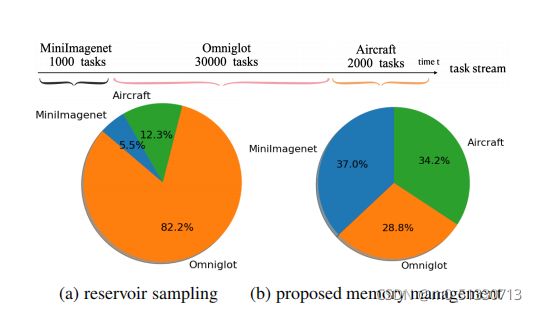
简要地说就是创造了一个新的内存管理机制并在其中进行训练如上图所示,在此管理机制中,经过训练后最大程度地保留了其中的域并实现了高效的自适应性。
接下来呢作者介绍了一种随机取样方法:水库取样(RS)。
Reservoir sampling (RS) [
58
,
15
] is a random samplingmethod for choosing
k
samples from a data stream in a
single pass without knowing the actual value of total number
of items in advance. Straightforward adoption of RS here
is to maintain a fixed memory and uniformly sample tasks
from the task stream. Each task in the stream is assigned equal probability n
/N
of being moved into the memory buffer,
where
n
is the memory capacity size and
N
is the total
number of tasks seen so far. However, it is not suitable for
the practical scenarios previously described, with two major
shortcomings: (1) the task distribution in memory can be
skewed when the input task stream is highly imbalanced
in our setting. This leads to under-representation of the
minority domains; (2) the importance of each task varies as
some domains are more difficult to learn than others. This
factor is also not taken into account with RS.
但RS并不适用于此前场景,作者给出了如上的两条原因。
如上图即为水库取样和提出的一种联合考虑的内存管理方法。此内存管理方法较为复杂,我下次再进行论述。接下来作者提出了在线变化域检测。对于域与域之间,
(1) 很少有射击任务在同一时间内具有高度多样性领域
(2) 在域中存在不同程度的变化跨越层序的边界。
在作者在研究中发现设置更改阈值是不够的用于检测域更改的小批量任务丢失值。因此作者接下来构造了一个低维投影空间和在此共享空间上执行联机域更改检测。
Projected space
Tasks
Tt are mapped into a commonspace
 where K
is the number of training data and
f
θ
t
is the CNN embed
ding network. The task embedding could be further re
fined by incorporating the image labels, e.g., concatenating
the word embedding of the image categories with image embedding. We leave this direction as interesting future
work. To reduce the variance across different few shot tasks
and capture the general domain information, we compute the exponential moving average of task embedding
O
t
as
O
t
=
α
o
t
+ (1
−
α
)
O
t
−
1
, where the constant
α
is the
weighting multiplier which encodes the relative importance
between current task embedding and past moving average.
A sliding window stores the past
m
(
m
is a small number)steps moving average,
O
t
−
1
,
O
t
−
2
,
· · ·
,
O
t
−
m
, which are
where K
is the number of training data and
f
θ
t
is the CNN embed
ding network. The task embedding could be further re
fined by incorporating the image labels, e.g., concatenating
the word embedding of the image categories with image embedding. We leave this direction as interesting future
work. To reduce the variance across different few shot tasks
and capture the general domain information, we compute the exponential moving average of task embedding
O
t
as
O
t
=
α
o
t
+ (1
−
α
)
O
t
−
1
, where the constant
α
is the
weighting multiplier which encodes the relative importance
between current task embedding and past moving average.
A sliding window stores the past
m
(
m
is a small number)steps moving average,
O
t
−
1
,
O
t
−
2
,
· · ·
,
O
t
−
m
, which are
used to form the low dimensional projection vector
z
t
, where
the
i
-th dimensional element of
z
t
is the distance between
o
t
and
O
t
−
i
,
d
(
o
t
,
O
t
−
i
)
. The projected
m
dimensional vector z
t
captures longer context similarity information spanning across multiple consecutive tasks.
Online domain change detection
At each time
t
, we utilize the above constructed projected space for online
domain change detection. Assume we have two win dows of projected embedding of previous tasks
U
B
={
z
t
−
2
B
,
z
t
−
2
B
+1
,
· · ·
,
z
t
−
B
−
1
}
with distribution
Q
and
V
B
=
{
z
t
−
B
,
z
t
−
B
+1
,
· · ·
,
z
t
}
with distribution
R
, where
B
is the window size. In other words,
V
B
represents the most recent window of projection space (test window) and
U
B
represents the projection space of previous window (ref
erence window).
U
B
and
V
B
are non-overlapping windows.For notation clarity and presentation convenience, we use
another notation to denote the
U
B
=
{
u
1
,
u
2
,
· · ·
,
u
B
}
and
V
B
=
{
v
1
,
v
2
,
· · ·
,
v
B
}
, i.e.,
u
i
=
z
t
−
2
B
+
i
−
1
and v
i
=
z
t
−
B
+
i
−
1
. Our general framework is to first measure
the distance between the two distributions
Q
and
R
,
d
(
Q, R
)
;
then, by setting a threshold
b
, the domain change is detected
when
d
(
Q, R
)
> b
. Here, we use Maximum Mean Discrep
ancy (MMD) to measure the distribution distance. Following
[
38
], the MMD distance between
Q
and
R
is defined as:

感兴趣的读者可以去阅读以上作者如何利用自己构建的投影空间进行在线域更改检测。
where
k
(
·
,
·
)
is RKHS kernel. In this paper, we assume RBF kernel
k
(
x, x
′
) =
exp
(
−||
x
−
x
′
||
2
/
2
σ
2
)
is used.
The detection statistics at time
t
is
W
tB
. If
Q
and
R
are
close,
W
tB
is expected to be small, implying small proba
bility of existence of domain change. If
Q
and
R
are significantly different distributions,
W
tB
is expected to be large,implying higher chance of domain shift. Thus,
W
tB
char
acterizes the chance of domain shift at time
t
. We then test
on the condition of
W
tB
> b
to determine whether domain
change occurs, where
b
is a threshold. Each task
T
t
is asso
ciated with a latent domain label
L
t
,
L
0
= 0
. If
W
tB
> b
,
L
t
=
L
t
−
1
+ 1
, i.e., a new domain arrives (Note that the
actual domain changes could happen a few steps ago, but for
simplicity, we could assume domain changes occur at time
t
); otherwise,
L
t
=
L
t
−
1
, i.e., the current domain continues.
We leave the more general case with domain revisiting as
future work. How to set the threshold is a non-trivial task
and is described in the following.
Setting the threshold
Clearly, setting the threshold
b
involves a trade-off between two aspects: (1) the probability of
W
tB
> b
when there is no domain change; (2) the probability
of
W
tB
> b
when there is domain change. As a result, if the
domain similarity and difficulty vary significantly, simply
setting a fixed threshold across the entire training process is
highly insufficient. In other words, adaptive threshold of
b
is
necessary. Before we present the adaptive threshold method,
we first show the theorem which characterizes the property of detection statistics
W
tB
in the following.
作者对于阈值的设定也是极为巧妙:
如上文中对于时间t的检测统计是WtB。WtB的预计值如果较小,这意味着存在域更改的可能性很小,若是较大,意味着域转移的可能性更高。因此,WtB特征化了在时间t时域转移的机会。然后我们进行测试,在WtB>b的条件下判断域发生变化,其中b是阈值。如何设置阈值是一项非常重要的任务明确设定阈值,将阈值b设定为两个方面之间的权衡:
(1)没有域更改时WtB>b;
(2)当域发生更改时概率WtB>b的值。因此,如果领域相似性和难度显著不同,只是在整个训练过程中设置一个固定阈值是远远不够的。换句话说,b的自适应阈值是必需在介绍自适应阈值方法之前调节的。
因晚上闲来无趣而重拾博客