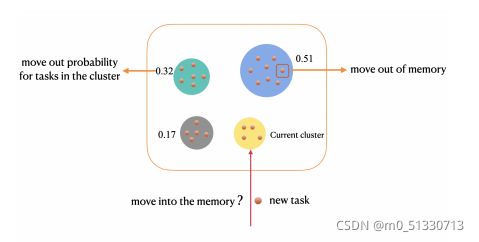
在元训练期间,从记忆中抽取一小批任务,并与当前任务联合训练,以减轻灾难性遗忘(这与神经网络之中也有异曲同工之妙)。来自记忆的直接均匀抽样任务会产生高方差,并导致不稳定的训练。另一方面,我们的直觉非统一的任务抽样机制是,任务对于保留先前领域的知识并不同等重要。携带更多信息的任务更有利于模型记住以前的域,并且应该更频繁地进行采样。为了实现这一目标,作者在记忆中提出了一种有效的自适应任务抽样方案,该方案可以加速训练并减少梯度估计方差。
上图是一个简单的统一任务采样示例和自适应内存任务采样方法,用于在元训练期间从内存缓冲区中采样任务。
Meta Learning:
Meta learning [
50
] focuses on rapidly adapting to unseen tasks by learning on a large number of
similar tasks. Representative works include [
57
,
52
,
20
,
21
,
23
,
49
,
7
,
42
,
6
,
41
,
37
,
61
,
66
,
46
,
53
,
65
], etc. All of
these methods work on the simplified setting where task dis
tributions are stationary during meta training. Completely
different from these works, we focus on the more challeng
ing setting where task distributions are non-stationary and imbalanced.
Online meta learning [
22
] stores all previous tasks in
online setting to avoid forgetting with small number of tasks.
[
28
] use Dirichlet process mixtures (DPM) to model the
latent tasks structure and expand network. By contrast, ours
focuses on mitigating catastrophic forgetting with single
model when meta learning on imbalanced domain sequences
with only limited access to previous domains.
Multi-domain meta learning [
54
,
55
,
59
] assume tasks
from all domains are available during meta training. We
focus on the case that each domain in an imbalanced domain sequence sequentially arrives
接下来作者介绍了相关工作:
元学习:元学习专注于快速学习通过大量学习来适应看不见的任务类似的任务。代表性作品包括以下所有内容:这些方法适用于元训练期间任务分布固定的简化环境。与这些工作彻底地不同,作者们将重点放在更具挑战性的环境中,其中任务分布是非平稳的,并且不平衡。在线元学习将以前的所有任务存储在在线设置,避免忘记少量任务。使用Dirichlet过程混合物(DPM)对潜在任务构建和扩展网络。相比之下,作者们专注于缓解单因素的灾难性遗忘基于不平衡域序列的元学习模型对以前的域只有有限的访问权限。多领域元学习承担任务在元训练期间,所有域都可用。作者们所关注的是每个域处于不平衡域中的情况序列下的依次到达。
下面介绍的是持续学习与增量和持续的少数镜头学习。
Continual Learning:
Continual learning (CL) aims to maintain previous knowledge when learning on sequentially
arriving data with distribution shift. Many works focus on
mitigating catastrophic forgetting during the learning pro
cess. Representative works include [
39
,
14
,
48
,
63
,
34
,
43
,
19
,
2
,
11
,
4
], etc.
Continual few-shot learning
[
8
] (CFSL) focuses on remembering previously learned few-shot tasks
in a single domain. To our best knowledge, the replay-based
approach to imbalanced streaming setting of continual learn
ing has been only considered in [
5
,
17
,
33
]. Different from
these works, which focus on learning on
a small number
of tasks
and aim to generalize to previous tasks, our work
focuses on the setting where the model learns on
a large
number of tasks
with domain shift and imbalance, and aims to generalize to the
unseen tasks
from previous domains
without catastrophic forgetting instead of remembering on a
specific task.
Incremental and Continual Few-shot Learning:
Incremental few-shot learning [
24
,
47
,
64
] aim to learn new cate
gories while retaining knowledge on old categories within
a single domain and assume access to the base categories is
unlimited. This paper, by contrast, requires good generaliza
tion to
unseen
categories in previous domains and access to
previous domains is limited.
Continual-MAML [
12
] aims for online fast adaptation to
new tasks while accumulating knowledge on old tasks and
assume previous tasks can be unlimited revisited. MOCA
[
27
] works in online learning and learns the experiences
from previous data to improve sequential prediction. In
contrast, ours focuses on generalizing to previous domain
when learning on a large number of tasks with sequential
domain shift and limited access to previous domains.
持续学习(CL)旨在按顺序学习时保留以前的带有分布移位的知识所到达的数据。许多作品关注的是缓解学习过程中的灾难性遗忘。连续少数镜头学习[8](CFSL)重点是在单个域中记住以前学过的一些射击任务。
与以上两种不同的是作者们的任务和目标是概括以前的任务,作者的工作重点关注模型在大范围内学习的设置具有域转移和不平衡的任务数,以及目标从以前的域中泛化到看不见的任务时没有灾难性的遗忘,而不是一天的记忆具体任务。
最重要的便是实验验证了:
Our method is orthogonal to specific meta learning models and can be integrated into them seamlessly. For illustra
tion, we evaluate our method on representative meta learning
models including (1) gradient-based meta learning
ANIL[
44
], which is a simplified model of MAML [
21
]; (2) metric
based meta learning
Prototypical Network
(
PNet
) [
52
]. Ex
tension to other meta learning models is straightforward.
Baselines
: (1)
sequential training
, which learns the
latent domains sequentially without any external mechanism and demonstrates the model forgetting behavior; (2)
reservoir sampling (RS)
[
58
]; (3)
joint offline training
,
which learns all the domains jointly in a multi-domain meta
learning setting; (4)
independent training
, which trains
each domain independently. Among them,
joint offline
training
and
independent training
serve as the perfor
mance upper bound. In addition, since continual learning
(CL) methods only apply to a small number of tasks, directly
applying CL methods to our setting with large number of
tasks (more than 40K) is infeasible. Instead, we combine
several representative CL methods with meta learning base
model. We modify and adapt
GSS
[
5
],
MIR
[
3
],
AGEM
[
14
] and
MER
[
48
] to our setting and combine them with
meta learning base models to serve as strong baselines. We
denote these baselines as PNet-GSS, ANIL-GSS, etc.
Proposed benchmark
To simulate realistic imbalanced
domain sequences, we construct a new benchmark and col
lect 6 domains with varying degree of similarity and difficulty, including
Quickdraw
[
29
],
AIRCRAFT
[
40
],
CUB
[
62
],
Miniimagenet
[
57
],
Omniglot
[
35
],
Necessities
from
Logo-2K+ [
60
]. We resize all images into the same size of 84
×
84
. All the methods are compared for 5-way 1-shot and
5-way 5-shot learning. All the datasets are publicly available
with more details provided in Appendix
A
. We calculate the average accuracy on unseen testing tasks from all the
domains for evaluation purpose.
Implementation details
For ANIL-based [
44
] baselines,
following [
7
], we use a four-layer CNN with 48 filters and
one fully-connected layer as the meta learner. For PNet
based [
52
] baselines, we use a five-layer CNN with 64 filters
of kernel size being 3 for meta learning. Following [
52
], we
do not use any fully connected layers for PNet-based models.
Similar architecture is commonly used in existing meta learn
ing literature. We do not use any pre-trained network feature
extractors which may contain prior knowledge on many pre
trained image classes, as this violates our problem setting
that future domain knowledge is completely unknown. We
perform experiments on different domain orderings, with the
default ordering being Quickdraw, MiniImagenet, Omniglot,
CUB, Aircraft and Necessities. To simulate imbalanced do
mains in streaming setting, each domain on this sequence
is trained on 5000, 2000, 6000, 2000, 2000, 24000 steps
respectively. In this setup, reservoir sampling will under
represent most domains. All experiments are averaged over
three independent runs. More implementation details are
given in Appendix
B
.
实验结果的展示大家可以自行去查看。至于GitHub上的代码现在好像访问不了了,可以过一段时间再去看看。
最后,总而言之,这篇顶会论文研究了元认知时的遗忘问题当元学习处在非平稳和不平衡的任务分布中。为了解决这个问题,作者提出了一种新的内存管理机制来平衡内存中每个域的内存缓冲区比例。此外,作者还介绍了一种有效的自适应算法减少任务梯度的记忆任务抽样方法。方差实验证明了该方法的提议的有效性。对于未来的工作,这将会是非常有趣的。