Hadoop + Hive 数据仓库原理与架构
1. Hive简介
Hive是什么
Hive 构建在 Hadoop 之上,提供以下功能:
-
通过类 SQL 指令轻松访问数据的工具,从而实现数据仓库任务,例如:提取/转换/加载(ETL),报告和数据分析。
-
一种将结构强加于各种数据格式的机制。
-
直接访问存储在 HDFS 或其他数据存储系统(例如:HBase)中的文件。
-
通过Tez, Spark, MapReduce执行查询。
-
HPL-SQL的过程语言。
-
通过Hive LLAP, YARN, Slider进行亚秒级查询检索。
Hive 提供标准的 SQL 功能,Hive 的 SQL 也可以通过用户定义的函数(UDF),用户定义的集合(UDAF)和用户定义的表函数(UDTF)扩展为用户代码。
换句话来说,Hive 是基于 Hadoop 的一个数据仓库工具,是用来管理数据仓库的。可以将结构化的数据文件映射为一张数据库表,并提供类 sql 的查询功能。
从如下 Hadoop 生态圈图中可以看出 Hive 所扮演的角色。
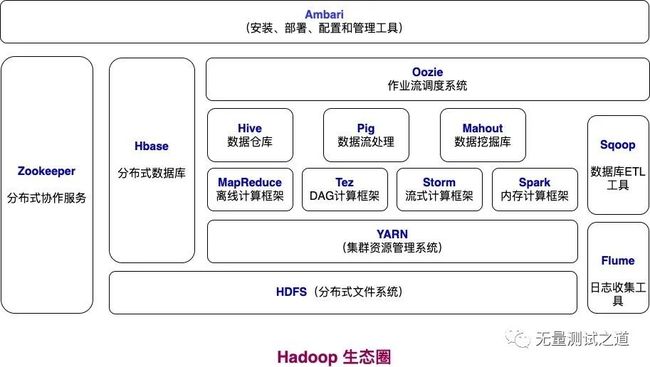
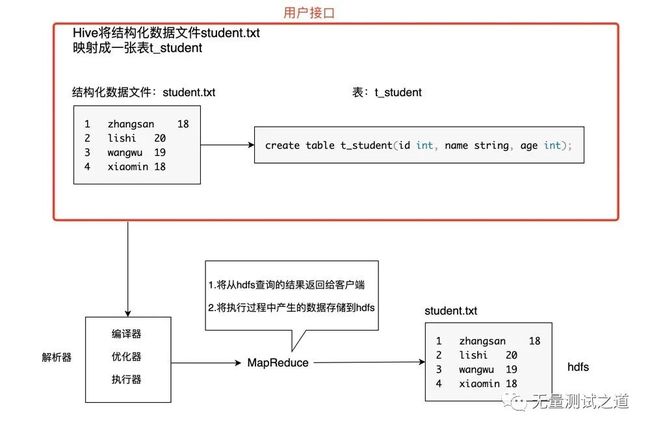
Hive如何将结构化的数据文件映射成一张表
结构化的数据文件如何理解?
-
数据文件中有固定的字段
-
字段之间有固定的分隔符
满足以上2个条件即可称为结构化的数据文件,例如:student.txt 文件的内容存储的是学生基本信息,包含:学生id,学生姓名,学生年龄。具体内容如下:
1 zhangsan 18
2 lishi 20
3 wangwu 19
4 xiaomin 18
该 student.txt 文件中,固定的字段有3个,分别是:学生id,学生姓名,学生年龄。字段之间固定的分隔符为'\t'(Tab键),那么可以认为 student.txt 文件就是结构化的数据文件。
假定在 HDFS 里创建一张表 t_student, 建表语句如下:
create table t_student(id int, name string, age int);
此时通过 Hive 元数据信息可以将数据文件 student.txt 与表 t_student 形成映射关系。
Hive 元数据信息一般会存储在 mysql 或 derby 数据库中,其中会记录:
-
表和数据文件之间的对应关系
-
表字段和文件字段之间的关系
元数据存放的路径在 hive-site.xml 文件里配置,找到对应存储的 mysql 库可以查询到表的元数据信息。
hive-site.xml 配置元数据所在的 mysql 信息的位置如下:
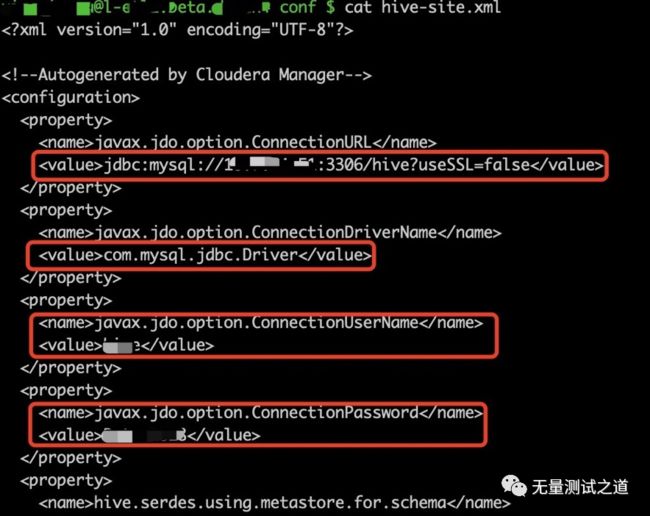
mysql 中元数据信息如下(以其中一张表 tbls 截图说明):
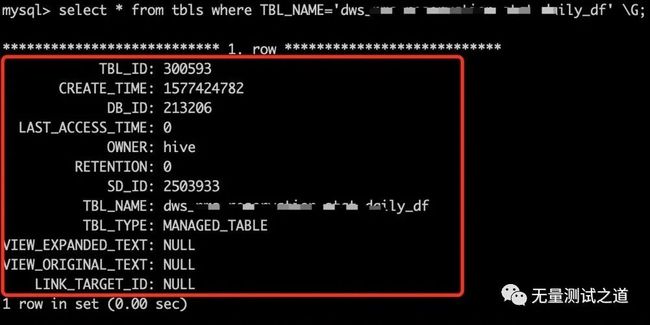
从以上截图中可以看出 tbls 表存储的元数据包含:
TBL_ID,CREATE_TIME,DB_ID,OWNER,TBL_NAME,TBL_TYPE等关键信息。
Hive可以使用类SQL指令对结构化数据文件进行分组查询
# 通过age分组,查询t_student表以age为维度对应的学生总人数之和
select age, count(*) from t_student group by age;这个 sql 语句与常见的 mysql 语句是十分类似的,hive 里的 sql 语句也可称为 HQL,这里的 HQL 语句通过 hive 将查询语句转换为底层的 MapReduce 进行运算。
Hive 的本质是将 Client 端提交的 sql 指令转换为 MapReduce 任务进行运算,在运算过程中会产生一些结果数据,这些结果数据在底层是使用 hdfs 来进行存储的。
换句话来说,Hive可以认为是将 SQL 转换为 MapReduce 任务的一个工具,甚至可以说 hive 就是 MapReduce 的客户端。
Hive的优点
-
通过使用类 SQL 语法操作数据,提高开发效率;
-
避免开发人员写底层的 MapReduce,降低开发人员的学习成本;
-
具有十分强的扩展功能;
2. Hive架构
先来看下Hive的架构图,如下图所示。
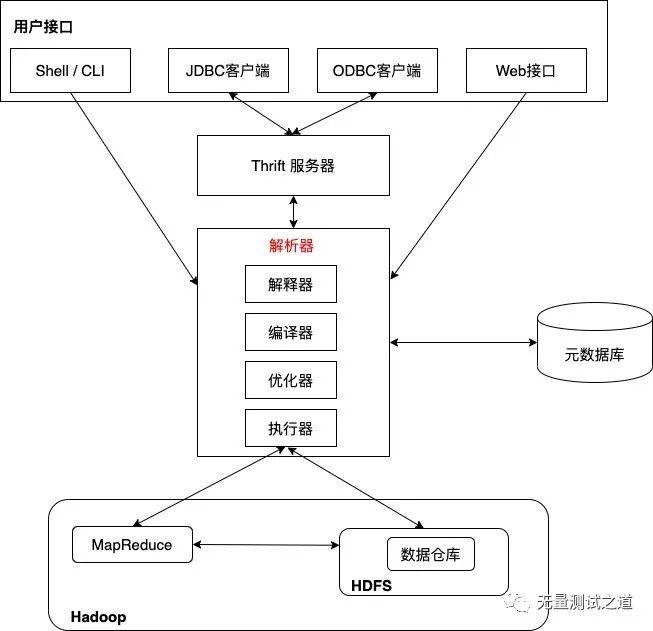
为了更好地理解 Hive 的架构图,下图以一个实际的例子作为讲解。
总结:
今天分享的内容包含:Hive是什么,Hive所具有的功能和优点,在 Hadoop 大数据生态圈中所饰演的角色,Hive架构等内容。
了解了 Hive 的基本内容和架构后,后续文章会持续更新 Hive 的相关操作和注意事项,以及在大数据测试过程中关于 Hive 的使用。敬请关注~
欢迎关注【无量测试之道】公众号,回复【领取资源】
Python+Unittest框架API自动化、
Python+Unittest框架API自动化、
Python+Pytest框架API自动化、
Python+Pandas+Pyecharts大数据分析、
Python+Selenium框架Web的UI自动化、
Python+Appium框架APP的UI自动化、
Python编程学习资源干货、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
备注:我的个人公众号已正式开通,致力于IT互联网技术的分享。
包含:数据分析、大数据、机器学习、测试开发、API接口自动化、测试运维、UI自动化、性能测试、代码检测、编程技术等。
微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,让我们一起共同成长!