Spark学习笔记(二)——分布式计算原理
Spark分布式计算原理
- Spark分布式计算原理
-
- 一、Spark WordCount运行原理
- 二、Stage
-
- 1、stage概念
- 2、为什么划分:
- 3、划分的好处
- 4、RDD之间的依赖关系
- 5、spark中如何划分stage
- 三、DAG工作原理
- 四、Spark Shuffle过程
- 五、RDD持久化
- 六、RDD共享变量
-
- 1、广播变量
- 2、累加器
- 七、RDD分区设计
-
- 1、设计概念
- 2、数据倾斜
- 八、数据源装载
-
- 1、装载CSV数据源
- 2、装载JSON数据源
- 九、基于RDD的Spark应用程序开发
-
- 1、演练一
Spark分布式计算原理
一、Spark WordCount运行原理
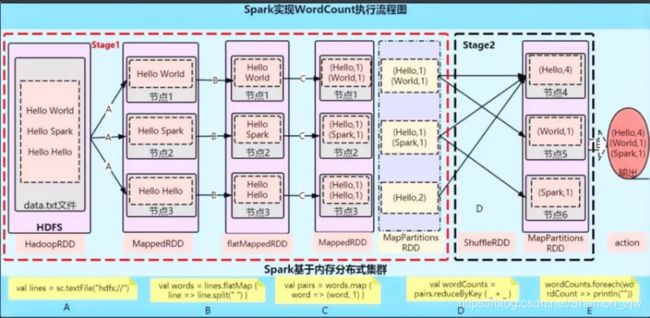
图中过程解析
A:val lines: RDD[String] = sc.textFile("hdfs"://)
//这行代码会生成两个RDD(HadoopRDD、MapPartitionsRDD)
//将内容分词后压平
B:val words: RDD[String] = lines.flatMap(.split(" "))
//这行代码通过flatMap生成一个新的RDD
//将单词和1组合到一起
C:val pairs: RDD[(String, Int)] = words.map((word, 1))
//通过map生成一个新的RDD
D:valwordCounts = pairs.reduceByKey(_+_)
//这时候就开始了一个ShuffedRDD,开始触发计算
E:wordCounts.foreach(wordCount=>println(""))
//输出结果
java API实现:
object ScalaWordCount {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf().setAppName("ScalaWordCount").setMaster("local")
//SparkContext,是Spark程序执行的入口
val sc = new SparkContext(conf)
//通过sc指定以后从哪里读取数据
//RDD弹性分布式数据集,一个神奇的大集合
val lines: RDD[String] = sc.textFile(args(0))
//将内容分词后压平
val words: RDD[String] = lines.flatMap(_.split(" "))
println(words.collect().toBuffer)
//将单词和1组合到一起
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))
//分组聚合
val reduce: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorted = reduce.sortBy(_._2, false)
/* //保存结果
sorted.saveAsTextFile(args(1))*/
println(sorted.collect().toBuffer)
//释放资源
sc.stop()
}
}
val reduce: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
**形成了一个新的RDD MapPartitionsRDD**
sorted.saveAsTextFile(args(1))*/
1.在这个过程中,生成两种类型的RDD,一种是shufferMapTask,另一种是resultTask 。
2.这个代码中生成了四个RDD,有两个阶段,
(1)一个是Shuffer前的相当与MapTask对中间数据进行计算(局部聚合)
(2)一个是Shuffer后的相当于ReduceTask进行计算写入到HDFS.(全局聚合)
(3)每个阶段又有最少两种RDD(map、flatMap、map可以合并),一个是a.txt文件的,另一个是b.txt文件的,所以这个过程生成了四个RDD
二、Stage
1、stage概念
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。Stage的划分,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。
比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;
如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage.
会根据RDD之间的依赖关系将DAG图划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中
2、为什么划分:
- 数据本地化
- 移动计算,而不是移动数据
- 保证一个Stage内不会发生数据移动
3、划分的好处
将窄依赖关系的尽量划分到一个Stage里面,来实现流水线计算提高效率。
4、RDD之间的依赖关系
-
Lineage:血统、遗传
- RDD最重要的特性之一,保存了RDD的依赖关系
- RDD实现了基于Lineage的容错机制
-
依赖关系
-
宽依赖(一对多)
宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)
- groupByKey,
- join(有shuffle过程)
- partitionBy
-
窄依赖(一对一)
窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
- map,
- filter,
- union,
- join(无shuffle过程)
- mapPartitions,
- mapValues
-
宽依赖和窄依赖的区别:
首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。
第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
相比于宽依赖,窄依赖对优化很有利 ,主要基于以下两点:
1.宽依赖往往对应着shuffle操作(多对一,汇总,多节点),需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
2.当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
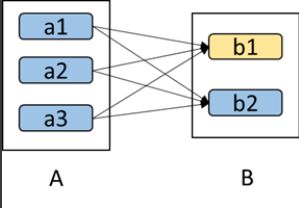
a. 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的; b. 对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。 c. 如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
5、spark中如何划分stage
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为
- 一个父RDD的分区对应于一个子RDD的分区
- 两个父RDD的分区对应于一个子RDD 的分区。
宽依赖指子RDD的每个分区都要依赖于父RDD的所有分区,这是shuffle类操作
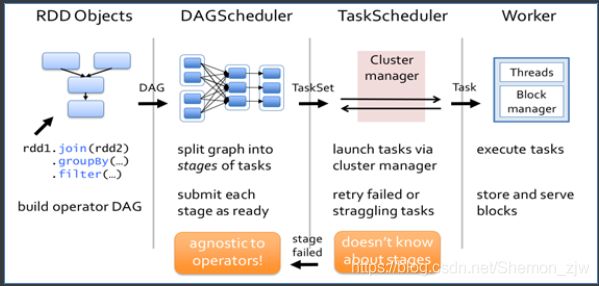
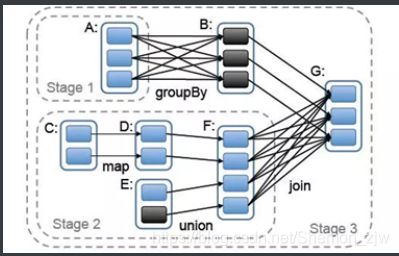
三、DAG工作原理
- 根据RDD之间的依赖关系,形成一个DAG(有向无环图)
- DAGScheduler将DAG划分为多个Stage
- 划分依据:是否发生宽依赖(Shuffle)
- 划分规则:从后往前,遇到宽依赖切割为新的Stage
- 每个Stage由一组并行的Task组成

四、Spark Shuffle过程
- 在分区之间重新分配数据
- 父RDD中同一分区中的数据按照算子要求重新进入子RDD的不同分区中
- 中间结果写入磁盘
- 由子RDD拉取数据,而不是由父RDD推送
- 默认情况下,Shuffle不会改变分区数量
五、RDD持久化
-
RDD缓存机制:缓存数据至内存/磁盘,可大幅度提升Spark应用性能
- cache=persist(MEMORY)
- persist
-
缓存策略StorageLevel
- MEMORY_ONLY(默认)
- MEMORY_AND_DISK
- DISK_ONLY
-
缓存应用场景
- 从文件加载数据之后,因为重新获取文件成本较高
- 经过较多的算子变换之后,重新计算成本较高
- 单个非常消耗资源的算子之后
-
使用注意事项
- cache()或persist()后不能再有其他算子
- cache()或persist()遇到Action算子完成后才生效
-
检查点:类似于快照
sc.setCheckpointDir("hdfs:/checkpoint0918")
val rdd=sc.parallelize(List(('a',1), ('a',2), ('b',3), ('c',4)))
rdd.checkpoint
rdd.collect //生成快照
rdd.isCheckpointed
rdd.getCheckpointFile
- 检查点与缓存的区别
- 检查点会删除RDD lineage,而缓存不会
- SparkContext被销毁后,检查点数据不会被删除
六、RDD共享变量
共享变量出现的原因:
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。Spark 的两个共享变量,累加器与广播变量,分别为结果聚合与广播这两种常见的通信模式突破了这一限制。
1、广播变量
广播变量:
允许开发者将一个只读变量(Driver端)缓存到每个节点(Executor)上,而不是每个任务传递一个副本,Spark 会自动把闭包中所有引用到的变量发送到工作节点上。虽然这很方便,但也很低效。原因有二:首先,默认的任务发射机制是专门为小任务进行优化的;其次,事实上你可能会在多个并行操作中使用同一个变量,但是 Spark 会为每个操作分别发送。
val broadcastVar=sc.broadcast(Array(1,2,3)) //定义广播变量
broadcastVar.value //访问方式
注意事项:
1、Driver端变量在每个Executor每个Task保存一个变量副本
2、Driver端广播变量在每个Executor只保存一个变量副本
2、累加器
累加器:只允许added操作,常用于实现计数,调试时对作业执行过程中的事件进行计数
用法:
(1)通过在driver中调用 SparkContext.accumulator(initialValue) 方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值initialValue 的类型。
(2)Spark闭包(函数序列化)里的excutor代码可以使用累加器的 += 方法(在Java中是 add )增加累加器的值。
(3)driver程序可以调用累加器的 value 属性(在 Java 中使用 value() 或 setValue() )来访问累加器的值。
object AccumulatorTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
val accumulator = sc.accumulator(0); //创建accumulator并初始化为0
val linesRDD = sc.textFile("src/data/hello.txt")
val result = linesRDD.map(s => {
accumulator.add(1) //有一条数据就增加1
s
})
result.collect();
println("words lines is :" + accumulator.value)
sc.stop()
}
}
//输出结果
words lines is :3
七、RDD分区设计
1、设计概念
- 分区大小限制为2GB
- 分区太少
- 不利于并发
- 更容易受数据倾斜影响
- groupBy, reduceByKey, sortByKey等内存压力增大
- 分区过多
- Shuffle开销越大
- 创建任务开销越大
- 经验
- 每个分区大约128MB
- 如果分区小于但接近2000,则设置为大于2000
2、数据倾斜
-
指分区中的数据分配不均匀,数据集中在少数分区中
- 严重影响性能
- 通常发生在groupBy,join等之后
-
解决方案
- 使用新的Hash值(如对key加盐)重新分区
八、数据源装载
1、装载CSV数据源
- 使用SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.csv")
val fields = lines.mapPartitionsWithIndex((idx, iter) => if (idx == 0) iter.drop(1) else iter).map(l => l.split(","))
val fields = lines.filter(l=>l.startsWith("user_id")==false).map(l=>l.split(",")) //移除首行,效果与上一行相同
- 使用SparkSession
val df = spark.read.format("csv").option("header", "true").load("file:///home/kgc/data/users.csv")
2、装载JSON数据源
- 使用SparkContext
val lines = sc.textFile("file:///home/kgc/data/users.json")
//scala内置的JSON库
import scala.util.parsing.json.JSON
val result=lines.map(l=>JSON.parseFull(l))
- 使用SparkSession
val df = spark.read.format("json").load("file:///home/kgc/data/users.json")
九、基于RDD的Spark应用程序开发
-
典型开发步骤
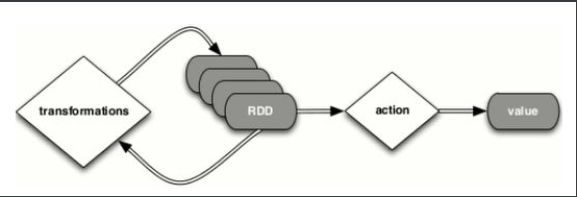
-
开发环境
- IDEA+MAVEN+Scala
- pom.xml
1、演练一
- 词频计数
- 需求:统计HDFS上的某个文件的词频
- 数据格式:制表符作为分隔符
- 实现思路
- 首先需要将文本文件中的每一行转化成单词数组
- 其次是对每一个出现的单词进行计数
- 最后把所有相同单词的计数相加
//提交运行
spark-submit
--class com.kgc.bigdata.spark.core.WordCount
--master spark://hadoop000:7077
/home/hadoop/lib/spark-1.0.SNAPSHOT.jar /data/wordcount