线性代数学习之特征值与特征向量
什么是特征值和特征向量:
在上一次线性代数学习之行列式学习了行列式相关的一些概念,其中也多次提到学好行列式是为了学习“特征值和特征向量”的基础,所以此次就正式进入这块内容的学习,也是线性代数中非常重要的概念,因为它又是线性代数其它重要概念的基石比如矩阵的相似性等等,当然这一块的学习也是比较抽象的,得耐住性子一点点来挼,也是就一定得要慢!!!
也是方阵的一个属性:
在正式学习特征值和特征向量之前,先站在一个更高的角度来看一下它们是一个什么?在上一次学习行列式时就说它是方阵的一个属性:
同样,对于特征值和特征向量也是方阵的一个属性,其实它们描述的是方阵的“特征”,而对于一个矩阵既可把它理解成变换又可以把它理解成一个空间,而对于特征值和特征向量更主要是用变换这个视角来看待方阵,当把方阵理解成一个变换的时候,这个变换就拥有一些特征,这些特征就被特征值和特征向量所表示,也就是说它是把方阵当成变换的时候的一个“特征”。
下面具体来看一个矩阵:
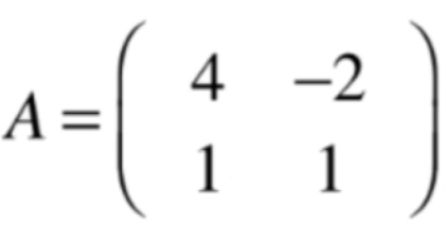
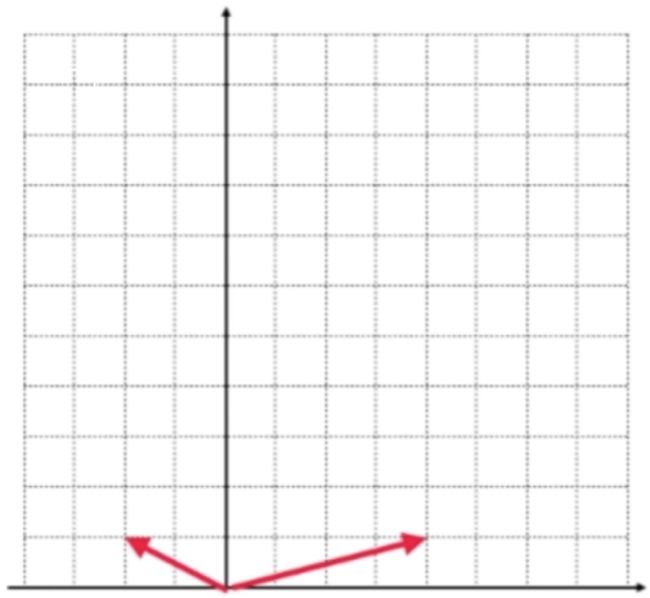
我们可以把它理解是二维空间的一组基,如下:
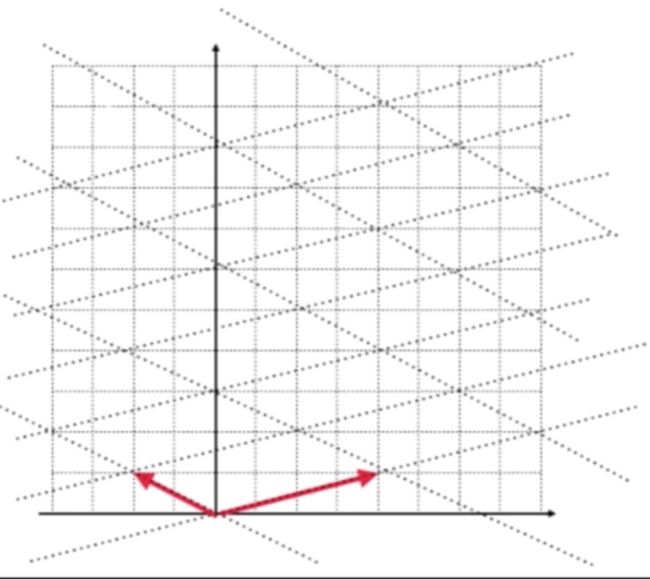
同时它也可以表示这个基所对应的坐标系相应的一个坐标转换矩阵,所以如下:
而这个矩阵可以任意一个点转换到另外一个位置,比如:
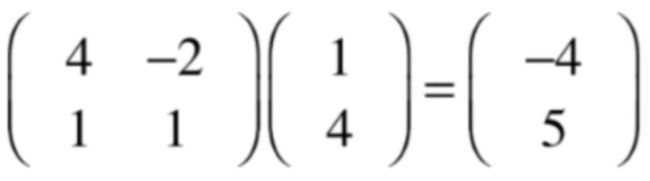
可以把(1,4)这个蓝色的点转换成(-4,5)绿色的点,如下:
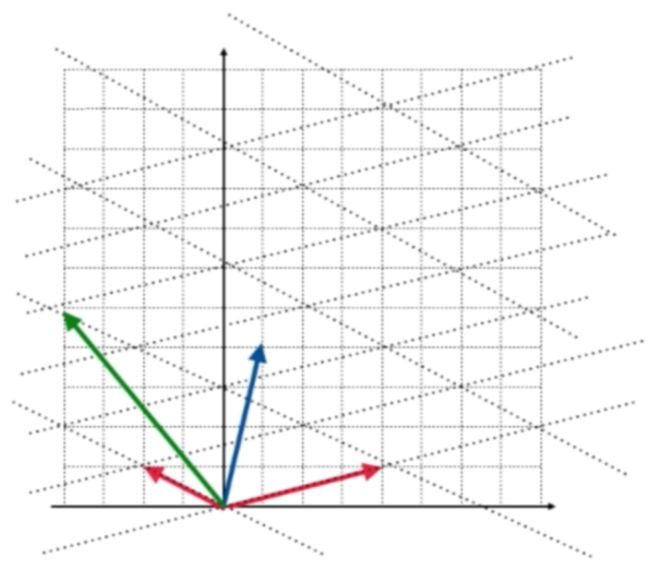
当然这个转换可以理解是这个基和标准基之间的坐标转换,不管怎样,矩阵A是可以做到变换的,它可以把二维坐标中的任意一点通过一个固定的规则转换到另外一点,而在这个变换的过程中比较关心一些“特殊”的向量,比如说(2,2)这个向量,经转换的结果为:
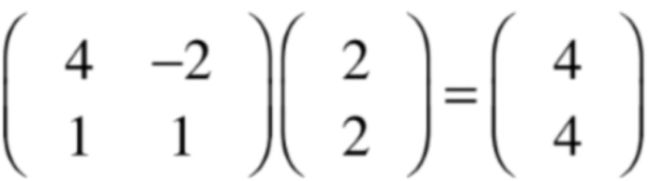
回到坐标系上来观察也就是对于蓝色的这根向量:
经过矩阵A的转换之后则为(4,4)了,如绿色所示向量:
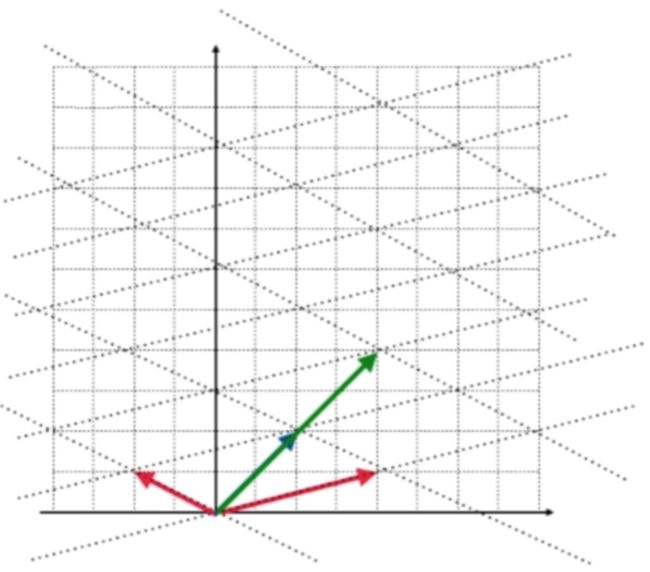
这个转换有啥特点呢?原来的向量经过转换之后方向并没有变,区别只是转换后的这个向量是原来向量的常数倍而已,同理再来看一个转换:

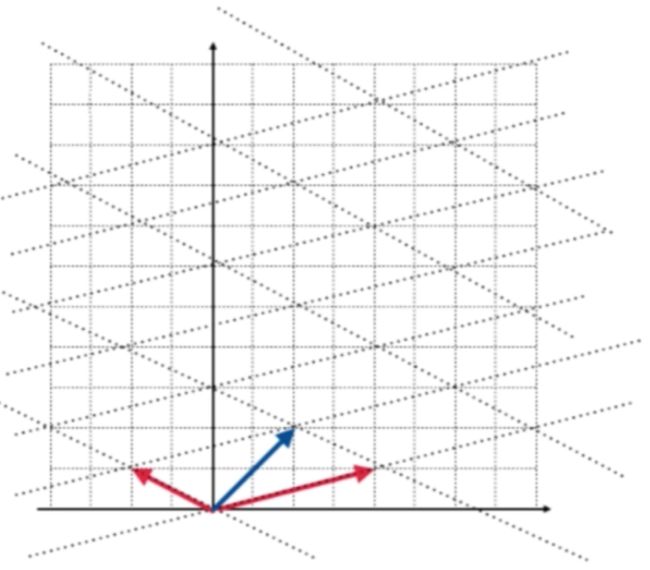
在坐标平面上看就是(2,1)这根蓝色的向量:
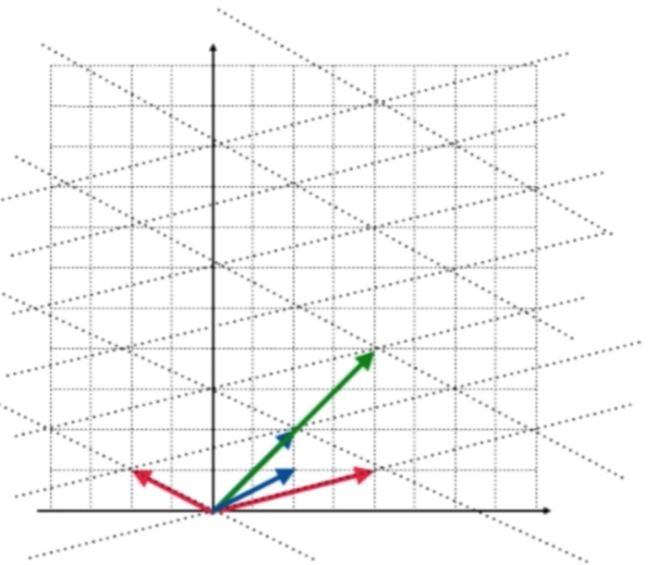
经过矩阵A转换之后就变成了(6,3):
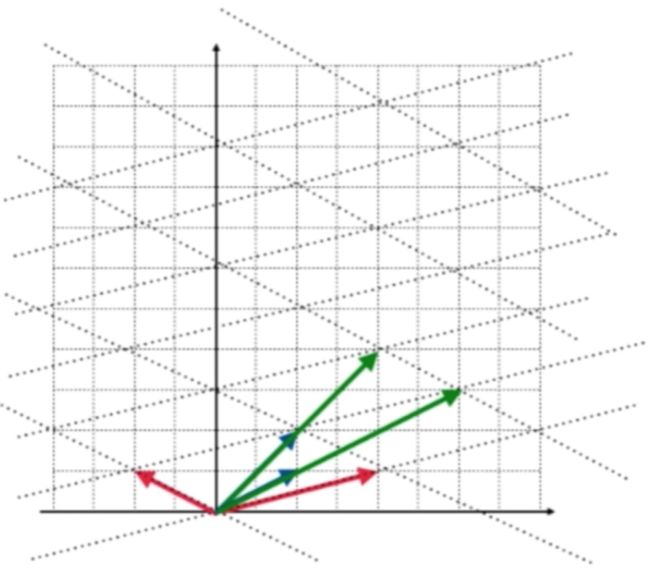
同样是方向没有变, 只是过结果向量是原来向量的常数倍。
也就是说对于一个矩阵A来说,我们对这样的向量比较感兴趣:在矩阵A的转换下得到的结果向量其方向并没有发生改变,只不过结果向量变为某一个向量的的常数倍了,用数学式子来表达这样的一个特点的话就是:
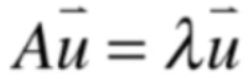
其中“λ”读作“lambda兰姆达”,代表一个常数,其中它可为负数的,好,接下来就可以概念定义啦:
其中λ称为A的特征值(eigenvalue);
而u向量称为A对应于λ的特征向量(eigenvector);
这概念还是挺难理解的,可以多多记一下。
关于它们的用处,之后再见分晓,先有个概念上的理解。
求解特征徝和特征向量:
那对于
这么个式子,特征值和特征向量具体是怎么求的呢?对于这个式子很显然我们关心2个未知数,一个是u特征向量,一个是λ这个特征值,所以要求解还是不容易的,不过这里先从最简单的情况看起。
情况一:零向量平凡解:
很显然,零向量肯定是满足上面等式的,把它叫做平凡解,但是很显然它不能反应A的特征呀,因为A不管是谁u向量是零向量都是解,所以,特征向量不考虑零向量。
那如果λ这个特征值为0呢?是不是也是平凡解?答案不是的!!!此时的式子就会为:
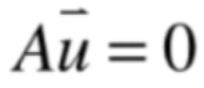
而由于u向量不能为零向量,所以此式子就变成了一个齐次线性方程组了, 而对于它肯定存在非零解的,显然对于这种情况A是比较特殊的,如果A可逆的话,则这个齐次线性方程组只有零解,而由于u向量期望不是零解,很显然A是不可逆的,那么当λ=0是矩阵A的特征值,就意味着A不可逆,也就是λ这个特征值反映了矩阵A的特征了,所以:特征值可以为0。
所以要知道上述标红的:“特征向量不考虑零向量;特征值可以为0。”
情况二:非零量的非平凡解【需瞪大眼睛】:
除了情况一,当然就是正常的求解过程了,下面来看一下如何推演出整个式子的特征值和特征向量的求解,对于这个式子:
1、全挪到左边就为:
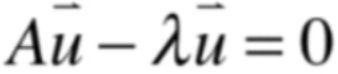
2、将u向量提出来:
对于等号左边的其实是可以将u向量提出来,但是一提出来,发现是一个矩阵A和一个常数λ,很明显不能做减法,所以此时在提之前需要先做一下变形,如下:
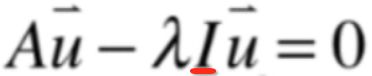
因为单位矩阵可以充当数字1的作用嘛,所以此时就要提一把了,如下:

3、找到方程的关键求解点:求行列式
接下来就是对于上面变形的这个式子求非零解了:
因为对于u向量来说不希望为零向量,因为特征向量是不考虑这种零向量的情况的,那怎么求这个非零解呢?此时又得将方阵的各种等价命题拿出来了,其中有一条:

标红的这个命题,对于Ax=0如果只有唯一解,那么x=0,但是!!!我们期望的是Ax=0不只有唯一解,所以很显然我们要用的命题是这个标红命题的逆命题,而对于上述这么多方阵等价命题来说,就只有一个不是叙述性的命题,那就是:

所以此时可以利用它的逆命题为我们推导解提供方便,也就是:"det(A)=0,A的行列式为0", 所以按照这个等价命题来看,是不是对于式子的求解又可以变成:
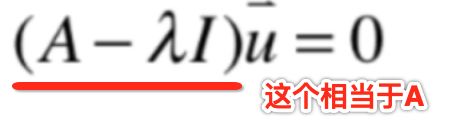
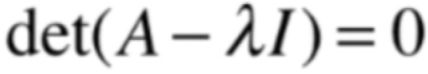
此时也就是将特征值和特征向量的求解问题转化到上一次咱们学习的行列式上的求解上来了,这也就是为啥说行列式是进一步学习特征值和特征向量非常重要的基础的原因之所在了,而此时这个行列式的求解方程就只有一个未知数λ就可以进行方程的求解了,而且这个方程对于任意的一个A都是适用的,所以管这个A叫做“特征方程”,因为通过这个特征方程就可以求解出λ这个特征值了,而进一步将这个λ特征值就可以代入Au=λu求出特征向量u了。
4、求特征向量进而最终求解特征值和特征向量:
特征值:
这里以这么一个方阵为例:
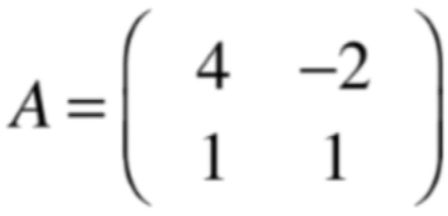
对于这个行列式子:
可以变为:
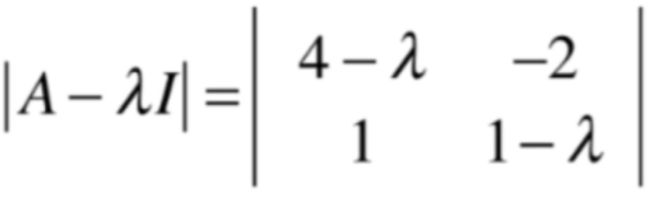
对于上述变换不太清楚的可以回忆一下矩阵的乘法,一下就能明白了,这里不做过多解释,而回忆一下行列式的求解公式 :
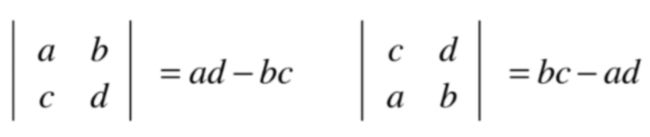
所以式子可以演变为:
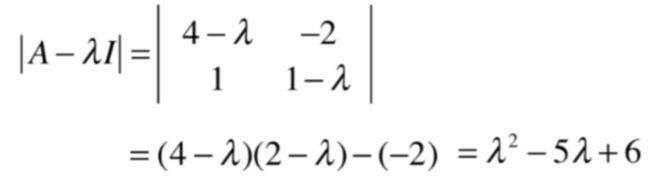
再根据因式分解,又可能变为:

特征向量:
知道了特征值之后,再代入这个式子就可以求得对应的特征向量:
很显然有两个,具体如下:
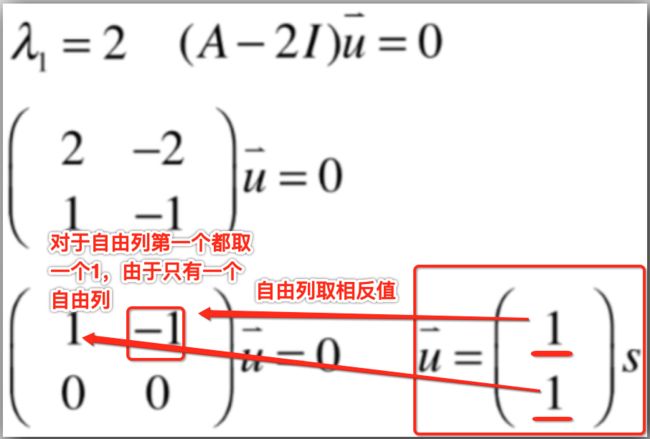
1、当λ1=2,就有:
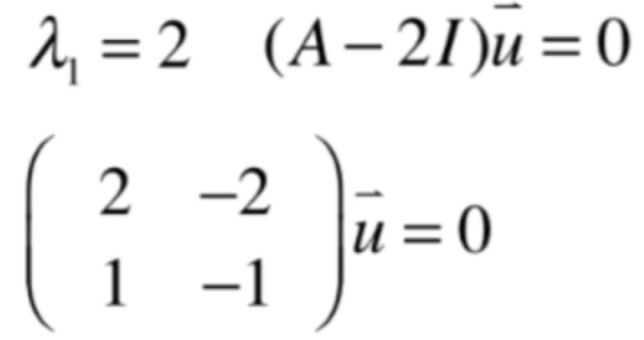
此时就是来求解这个线性系统了,先将它进行高斯约旦消元法为:
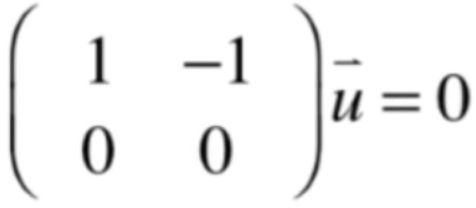
那这个u的非零解是啥呢?这里可以回忆一下之前线性代数学习之向量空间,维度,和四大子空间 - cexo - 博客园求解矩阵的零空间的方法,提到零空间的基有这么一个规律:

很显然此时的u的特征向量就可以求解如下了:
2、当λ1=3,就有:
类似的,其特征向量为:

所以对于矩阵:

它的特征值有两个:

而它所对应的特征向量也有对应的两个:

其中对于这两个特征向量,其实都是有无数个,因为有一个系数s对吧。
特征值和特征向量的相关概念:
1、对应一个λ的特征向量不唯一,有无数个:
在上面求解特征值与特征向量也能看出这个特性:
因为向量u有一个系数,可以随便取无数个值,对应的向量也就有无数个了。
2、如果u是A对应于λ的一个特征向量,则ku也是一个特征向量。
啥意思?也就是说一旦一个向量是特征向量了,那么给这个特征向量前面乘以一个系数,相应得到的结果向量还是一个特征向量, 当然此时需要限定一下:
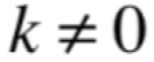
因为特征向量不能包括零向量,下面来证明一下:
由于u已经是A对应于λ的一个特征向量了,所以此式子肯定是满足了:
那下面就是来看一下它是否也满足:
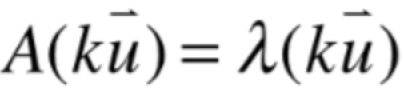
如果满足,那咱们这个特性也就得证了,下面来看一下其实很容易证明:

这也证明了,一旦知道了λ是A的一个特征值的话,它所对应的特征向量一定是有无数个的。
3、特征向量组成了A-λI零空间:特征空间
其实关于“λ是A的一个特征值的话,它所对应的特征向量一定是有无数个的”还可以有另外一个思考的角度,如之前所示,当求解出了λ之后,再求解这个齐次线性系统所对应的非零解:
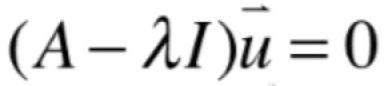
很显然如果这个方程有唯一解的话肯定u就是零解,而由于u不能为零解,所以肯定此方程就不唯一,解肯定也就有无数个,另外也可以从之前学习的零空间的角度来看待这个问题,其实特征向量组成了A-λI零空间,回忆一下零空间的定义:

而对于零空间,它是一个空间,并且对于这个空间不可能只含有0那一个元素,所以空间中一定就含有无数个元素,这是因为对于一个空间肯定能找到它的一组基,而一旦找到了一组基那么这组基下的所有线性组合都在这个空间中,而一组基对应的线性组合有无数个,也就是一旦λ确定了,相应的特征向量就有无数个,实际上这无数个特征向量就组成了(A-λI)的零空间,但是!!!这话说得不够严谨,因为任何一个空间都包含零空间,所以!!!这个零空间是需要刨除零向量的,所以:
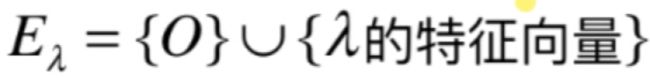
0向量以及λ对应的所有的特征向量并起来,就构成了A-λI的零空间了,接下来新概念就来了:

也就是一个特征值所对应的所有的特征向量所组成的空间,然后再加上零向量本身形成的向量空间就是特征空间,简单来说就是(A-λI)的零空间。
4、更多特征值
简单特征值:
在我们求解特征值和特征向量的时候,其实特征值是一个取决定性作用的一个属性,因为一旦特征值确定的话,相应的特征空间就确认了,在这个特征空间中有无数个特征向量,而这些特征向量都是这一个特征值所对应的特征向量,那下面就来看一下对于特征值它对应有哪些可能性。
回忆一下在之前求解特征值和特征向量时,首先就是求出特征值λ,其求解办法就是转到求行列式上来:
而它本身是一个关于λ的n次方程,其中n就是矩阵A的阶数,如果A是一个n阶方阵的话,那么λ有n个解【注意是在复数空间中】,下面还是拿之前求特征值和向量相关的矩阵为例子看一下,“λ有n个解”的含义:
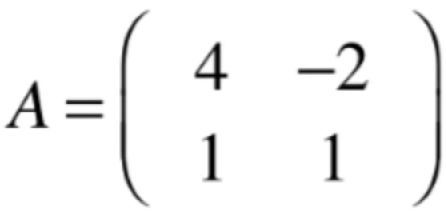
它是一个2【突出它是为了看之的特征值的解的个数也是为2】阶方阵对吧,而它所对应的特征方程为:

此时就求得λ的解了,有2个解,分别为:
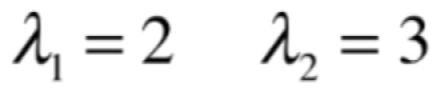
这两个解均为实数,且各不相同,称之为简单特征值,那这个“简单”表现在哪在之后再来看,目前先有一个概念就是如果对于一个方阵来说,它的特征值都是实数且各不相同的话, 这种情况是最简单的。
多重特征值:
除了上面的简单特征值,还有其它两个非简单的特征值,首先第一种是特征值中有相同的情况,比如:

看到木有,有2个特征值,但是呢是一样的值,而具体重复了几次有时也把它叫做重数,而对于咱们这个例子,如果一个矩阵A对应的特征方程求解出来两个解相同,值为1,我们就可以说这个矩阵A的特征值为1,而它的重数为2。
复数特征值:
有可能特征方程可能在实数范围里没有解,比如特征方程是一个关于λ的n次方程:
当然有可能是这个样子的呀:

也就是λ^2+1 = 0,很明显在实数范围里是无解的,但是!!!如果扩展到复数的范围就有解了,关于实数和复数的区别可以参考实数、虚数和复数_Never Limit-CSDN博客_实数和虚数,这个特征值也是有2个,为:
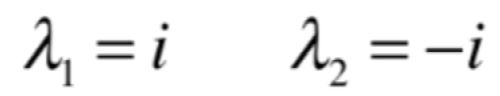
关于复数特征值这里不会讨论,而对于多重特征值的情况也只是点到为止,也就是这俩特征值不重点讨论,是因为可以通过一些技巧使得在真正使用特征值和特征向量的时候规避掉这两种情况,而只去应用简单的特征值,这块之后再说,总之在实际使用时都会想尽办法来使用简单特征值,而去避免使用多重和复数特征值。
特征值与特征向量的性质:
性质一:矩阵不可逆
关于这个性质其实在之前学习特征值和特征向量时已经有学过了,当复习, 对于式子:

当λ=0时,就有:
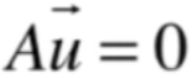
需要让这个线性系统不仅有零解,还需要有其它的解,那就是0这个特征值所对应的特征向量,根据方阵的等价命题就可以知道:

反过来,如果λ=0不是A的一个特征值的话,则A是可逆的。所以,对于方阵的等价命题中就可以被充最后一个命题了,如下:

至此,关于矩阵的所有等价命题就已经学完了。
性质二:
上三角矩阵的特征值是其对角线上的元素:
下面来看一些特殊的方阵的特征值和特征向量的求法,目前我们所知的求解方阵的特征值和特征向量的步骤是先求解特征值,然后再求解特征方程,而求解特征方程就是让矩阵的行列式等于0:
一说到行列式,是不是就可以联想到当时学习的一些特殊的矩阵了,简单回忆一下:
对角矩阵:
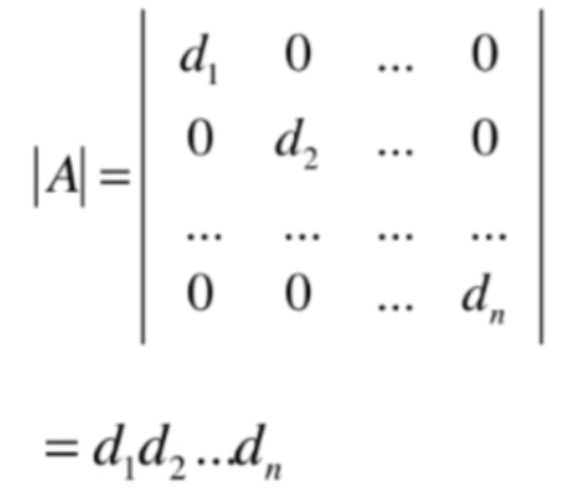
也就是这种对角矩阵的行列式就是对角线元素的乘积,那它对应的特征值是咋样的呢?其实也就是:
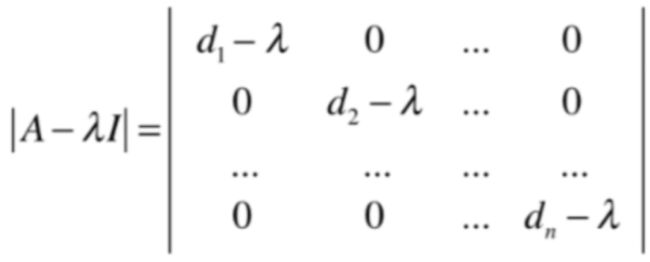
它也是一个对角线,很显然它的行列式的值也是等于对角线元素的乘积对吧?
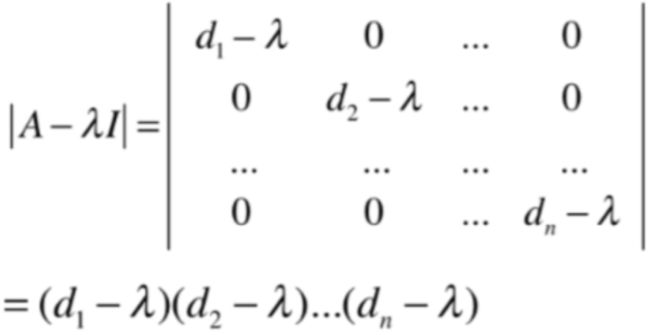
而要求解特征值就是让上面这个式子为0,所以此时这个特殊方阵的特征值就有如下解了:
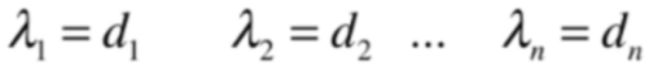
此时针对对角方阵求它的特征值就变得极其简单了,不需要再求线性系统的解了,其实就是各个对角线上的元素。
下三角矩阵的特征值是其对角线上的元素:
有了上面上三角矩阵的性质,类似的对于下三角矩阵也是一样的,求解它的特征值也非常的简单,因为对于下三角矩阵来说它的行列式也是对角元素的乘积:
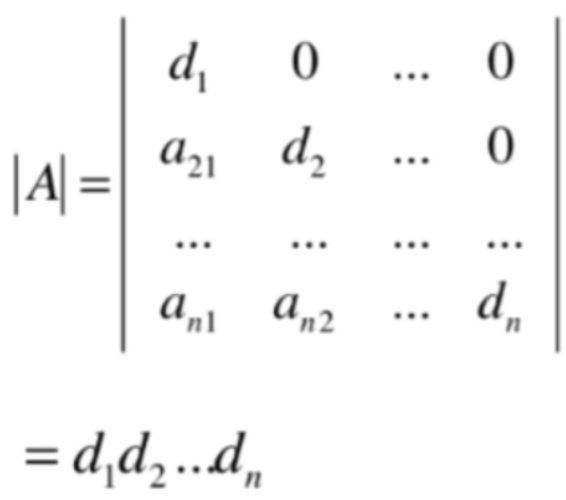
相应的下三角矩阵的特征值的求法如同上三角矩阵一样:
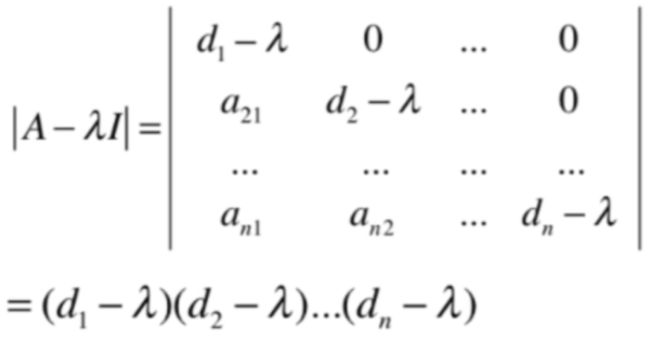
同样的特征值也为:
性质三:

关于这个矩阵的幂,在很多应用中都会对它感兴趣的,所以有必要研究一下特征值跟矩阵幂的关系,由于这个m木有定,所以下面用数学归纳法来对上面的这个性质进行一个论证:
1、当m=1时,很显然成立,所以就有如下式子:

2、假设m=k成立,很显然就有如下等价的式子成立:
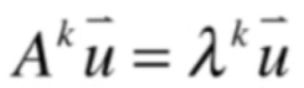
3、当m=k+1时,就有:
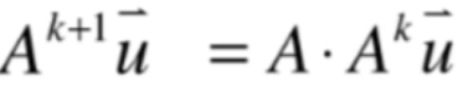
而由于:
所以等号右侧就可以写为:
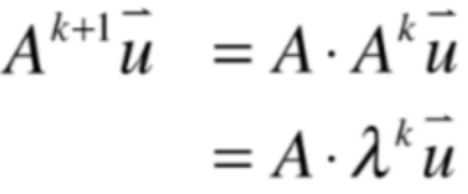
再将右侧进行变换:
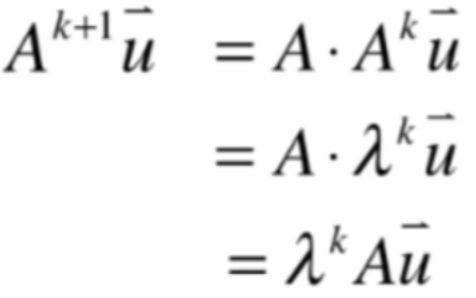
而:
所以此时又可以化为:
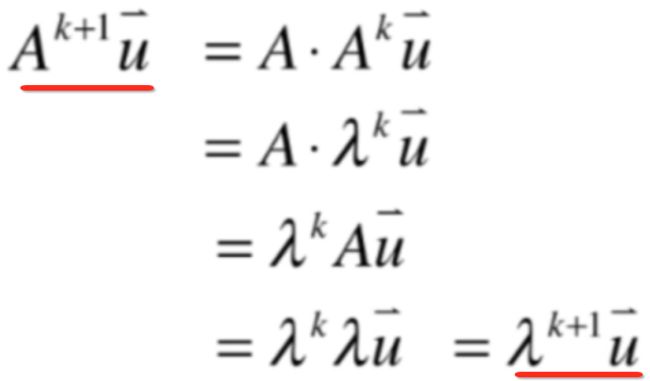
那是不是就可以说:
所以得证。不过要注意!!!这里的m是>=1,对于<0的情况是不满足这种性质的,这点一定要清楚。其实也是成立的,下面就来证明一下为-1的情况。
性质四:
![]()
下面来证明一下,由于λ是A的特征值,所以就有:
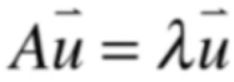
然后两边都乘以A的逆,如下:
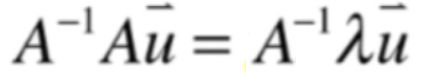
此时就又可以化为:

再做转换,其结果就证明出来了:
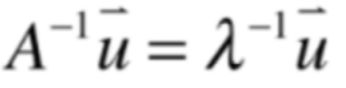
所以核心就是要理解,如果λ是A的特征值,就有这个等式:
直观理解特征值与特征向量:
简单特征值:
在上面咱们都是以代表的角度来学习特征值与特征向量的,接下来则回到几何角度直观的理解一下特征值与特征向量。
示例一:投影变换
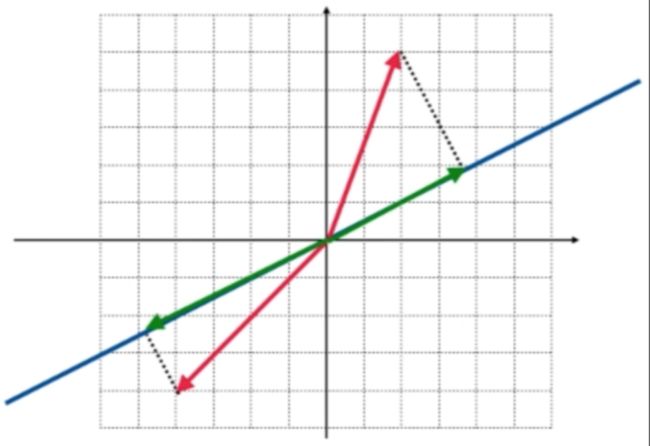
这里还是回到二维空间中,假设研究的投影变换是指把任何向量投影到(2,1)所在的直线,如蓝色直线所示:
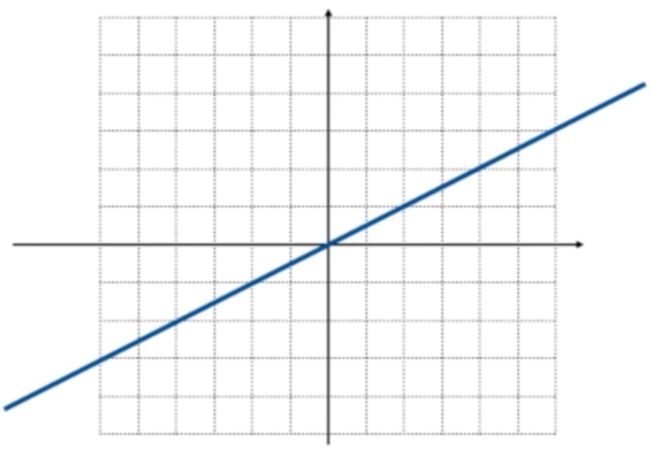
然后把二维空间中的任何一个向量都投影到(2,1)这根蓝色的直线上,比如:
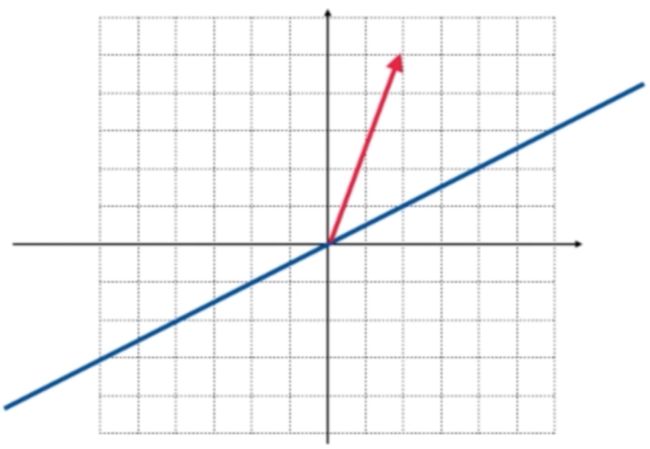
然后向蓝色直线引垂线,其中绿色所示的则为投影向量:
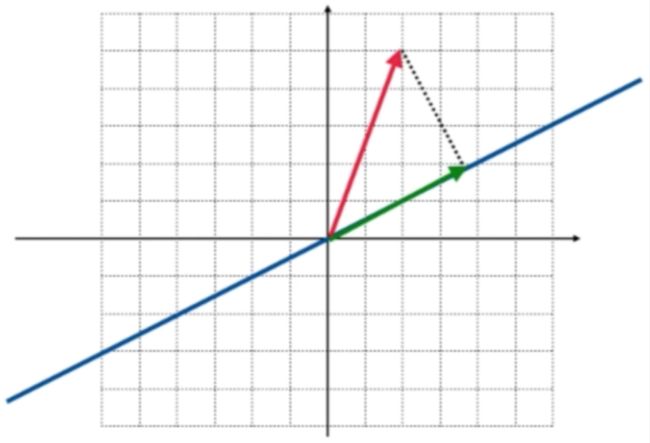
再在空间中随便弄一个向量:
往蓝色直线进行投影,得到的向量既为投影向量:
接下来研究一下投影变换所对应的矩阵的特征值和特征向量是多少,不过在正式求解之前,先来复习一下之前的知识,就是看这个变换是否是真的对应一个矩阵,因为变换这个词是非常广的,并非随便给一个变换就能求出特征值和特征向量的,需要保证这个变换对应的是一个矩阵才行,此时就需要看投影变换是不是一种线性变换,关于这块可以参考线性代数学习之坐标转换和线性变换 - cexo - 博客园,其中回忆这么一句话:
那根据线性变化的两个性质:
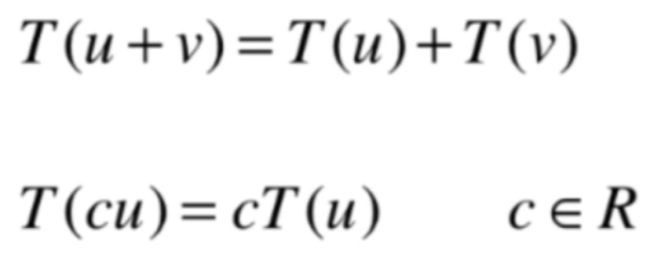
很明显投影变换是完全满足这两条的,对于第一条是说对uv两个向量相加的变换等于u和v分别进行变换之和,从二维坐标就可以看出来肯定满足,而另一条是对cu进行变换它就等于先对u进行变换,然后再乘以c倍,从二维坐标上也能看出来,所以对于投影变换肯定是线性变换的,而线性变换肯定是对应一个矩阵的,而咱们这个例子中就是二维空间向二维空间的变换,所以它是一个(2x2)的方阵,所以就可以来看一下它的特征值和特征向量了。
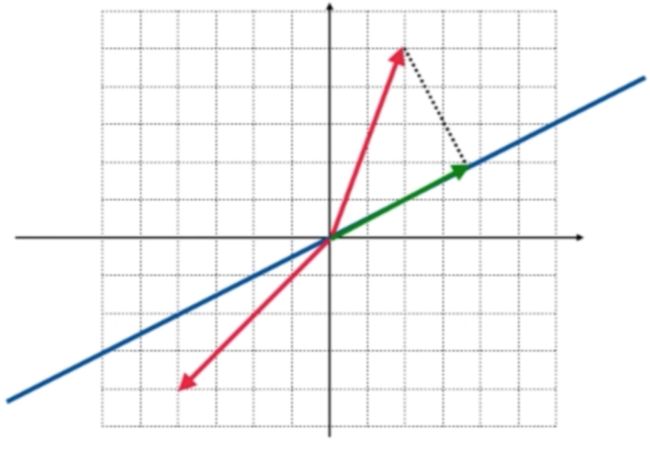
而用几何的视角来看特征值和特征向量,其先研究特征向量是比较方便的【从代表的角度是先研究特征值】,先来回忆一下特征向量的定义:经过这样的变换之后所得到的结果向量和原向量还是在一条直线上,它们之间只相差某一个常数倍,常数就是特征值,那回到咱们这个二维空间中的变换,哪些向量是经过投影之后所得到的结果向量和原向量还在同一根直线上呢?很显然就是在这根蓝色向量上经过投影之后得到的结果还是蓝色的直线上,如下:
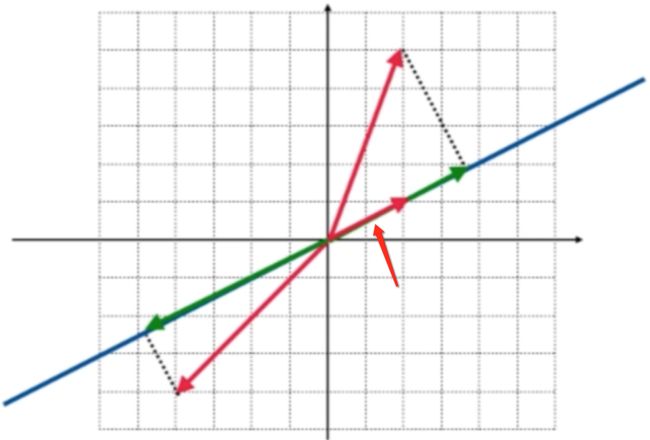
所以这根蓝色直线上的所有向量经过投影之后的结果还是它本身,还在蓝色直线上,所以在这蓝色直线上的所有向量都是特征向量,那它们对应的特征值是多少呢?其实是:
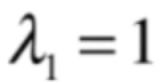
为啥呢?因为经过投影在蓝色直线上后的向量还是它自身,这里看一下,是不是在这个过程压根不知道投影变换所对应的矩阵是谁,只通过几何含义就推导出了一组特征向量和特征值。
那在这二维空间中还有木有其它的向量也满足投影到这根蓝色直线上所得到的结果和原来的向量在同样一根直线上呢?这第二组特征向量就稍微有点难想了,其实就是和蓝色直线相垂直的向量,如下:
把它投影到蓝色的直线上,结果向量是零向量,也就是投影到蓝色直线上之后的结果向量是原来向量的0倍,所以和蓝色直线垂直的这根直线上的所有向量也是投影变换的特征向量, 它所对应的特征值为0:
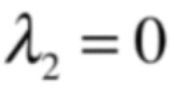
这样就通过几何的角度就求解出了投影变换所对应矩阵的特征值和特征向量了,另外还可以找到这两个特征值所对应的特征空间,一个就是投影变换要投影到蓝色直线上,这个直线是一上空间,这个空间中的所有向量则是投影变换对于λ=1的特征向量,另外一个特征空间则是和蓝色直线相垂直的那根直线,它形成了一个空间,也称之为特征空间,这个空间中的所有向量则是投影变换对于λ=0的特征向量。
示例二:矩阵A
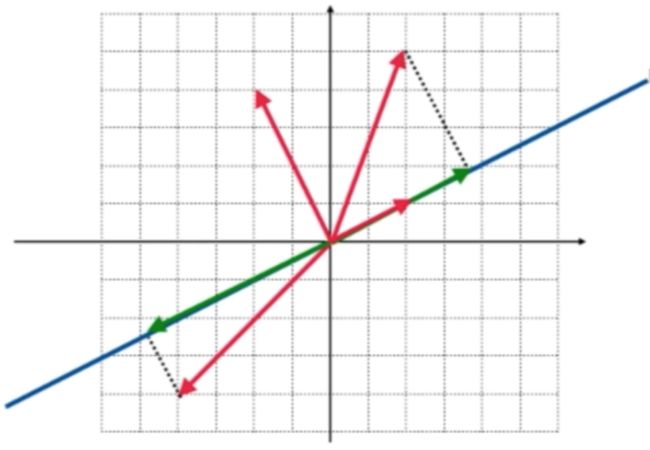
接下来再来看这么一个矩阵在几何意义上的特征值和特征空间:
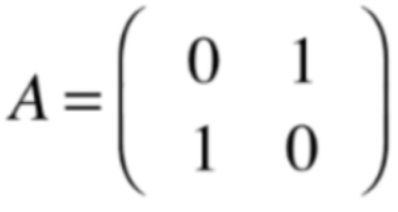
如果矩阵A表示一个变换,它其实就是单位矩阵做了一下行交换,所以是一个初等矩阵,相当于这个矩阵就可以将所有的(x,y)坐标进行一个变换(y,x),回到坐标系来看,其实这个A所表示的变换就是将所有的向量沿y=x这根蓝色的直线,做一次翻转:
比如说这根向量:
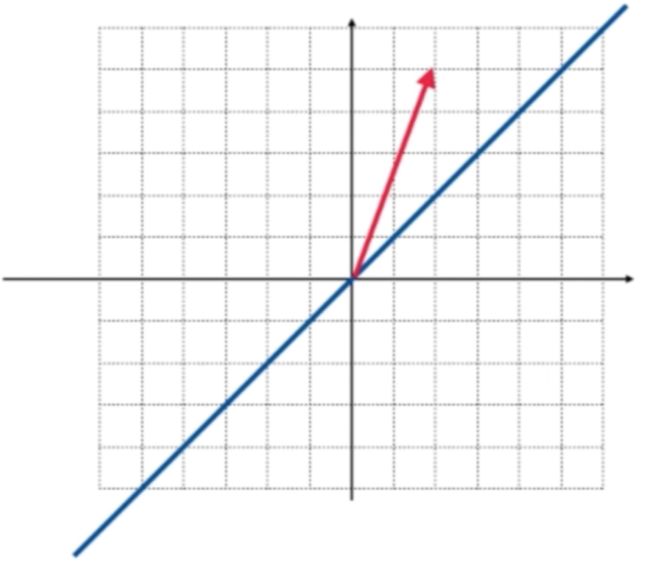
经过这个矩阵的变换之后,就会沿这条蓝色直线进行翻转了,如蓝色向量下:
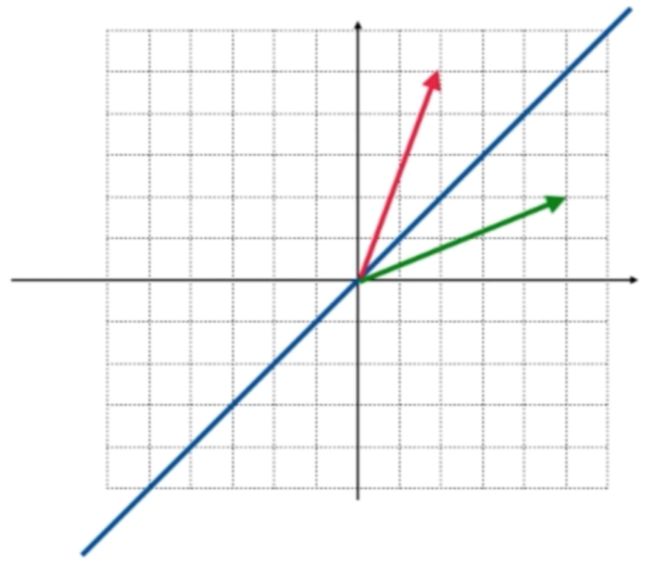
而这俩向量是关于这根蓝色直线对称的:

这就是这个矩阵所对应的变换的几何含义是什么,那知道了它的几何含义了是不是就可以找到了它的特征值和特征向量了呢? 那就要看经过这个变换之后得到的结果向量还在向量原来的方向,很显然在y=x这根直线上的所有的向量经过翻转之后依然还在这根直线上,如:

而所对应的特征值为:
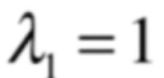
同样的和这根直线垂直的向量:
而它们只差一个常数倍,很显然这个常数为-1,所以另一个特征值为:
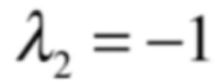
同样也找到了对应的特征空间,分别是y=x这根直线形成了一个空间和该直线垂直的直线所形成的一个空间,好,以上是针对这个矩阵从几何意义上的分析,由于这是一个具体代数,所以咱们具体求解一下看是否如几何角度分析所示:
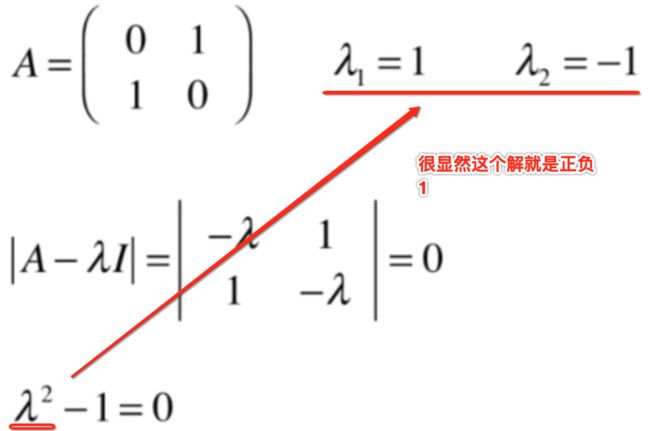
重要性质:
对于目前所举的例子来看特征值和特征空间都是两种,再回忆一下之前所举的也是一样的:

其中有一个特点,就是这两个特征值所对应的特征向量它们不会重合,所以一个重要的性质要出来了:
“如果矩阵A含有两个不同的特征值,则他们对应的特征向量线性无关。”
下面来证明一下,假设:

现在就是要证明u和v是线性无关的了,这里可以用反证法:
假设线性相关,就有:
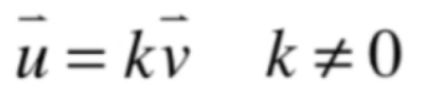
所以就有:
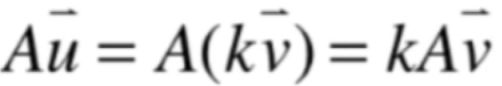
然后再来替换就有:

就有:
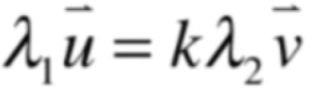
而由于:
所以这个等式左右都可以乘以λ1为:
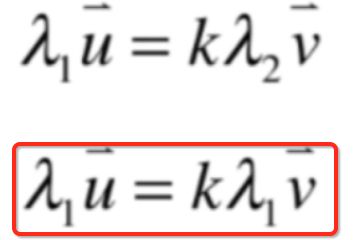
然后两个式子相减就有:
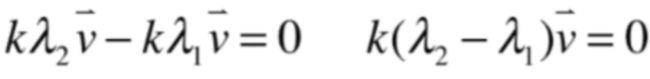
其中k!=0了,而λ2-λ1肯定也不等于0,因为它们是两个不同的特征值,那么对于最后化的这个方程:

只有v向量为0了,但是!!!v是一个特征向量,不可能为零向量呀,很显然矛盾了,咱们的假设就是错误的,也就反证了两个不同的特征值所对应的特征向量肯定是线性无关的。
“不简单”的特征值:
在上面直观理解特征值与特征向量举的都是“简单特征值”,也证明一个非常重要的结论就是两个不同的特征值所对应的特征向量肯定是线性无关的,还记得关于特征值还有另外两种类型么,回忆一下:

也就是还有“不简单”的特征值,那怎么个“不简单”法呢?下面也是通用直观的角度来简直一下:
示例一:旋转矩阵【复数特征值】
关于旋转矩阵的例子在之前已经举过n次了,长这样:

也就是正的F逆时针旋转90,其对应的旋转矩阵为:
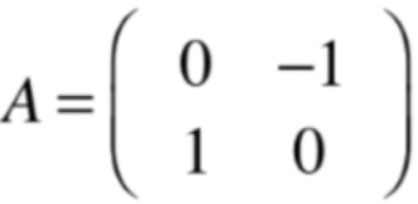
也就是旋转的F就是y轴为(0,1),而轴为(-1,0),下面则来从几何的角度来看一下这个矩阵所对应的特征值和特征向量,同样还是先从特征向量看起,也就是通过旋转之后哪些向量在旋转以后它和这个向量原来的这个向量处在同一个直线上,用大脑一想貌似没有这样的向量吧,因为任何向量一旋转肯定就没有跟原来的向量在同一直线上了呀,所以从几何角度来看没有任何一个向量满足这个矩阵的特征向量,为啥会这样呢?下面来求一下这个矩阵的特征方程:
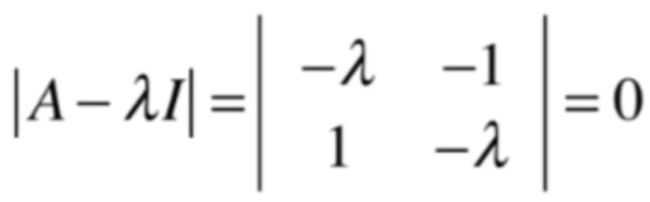
它是一个二阶行列式,为主对角线元素的乘积-非主对角线元素的乘积,所以最终方程就变为了:
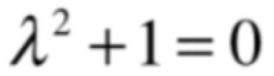
很显然在实数范围内肯定这个方程是没有解的呀,但是!!!在复数范围内是有解的,为i和-i,也就是说对于复数特征值的几何含义已经消失了,因为在几何角度已经无法直观的理解特征值和特征向量了。
示例二:单位矩阵【多重特征值】
下面再来看另外一个"不简单"特征值,先来看这么一个单位矩阵:
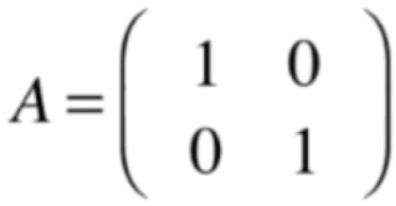
那看一下这个单位矩阵所对应的特征值和特征向量,想一下对于单位矩阵其实就是把原来的向量还转换为自己,向量根本不动,那从几何的含义来看一下什么样的向量在单位矩阵的转换下还在原来这个向量自己的方向上呢?很显然在二维平面上所有的向量经过单位矩阵的变换之后还是它自己,所以也还在它自己所在的直线上,并且相应的特征值为1,虽说特征值只有1个,但是呢特征向量在二维平面上的任意方向,怎么会出现这样的情况呢?还是用代表的角度来看一下,其实在之前也已经看过了:
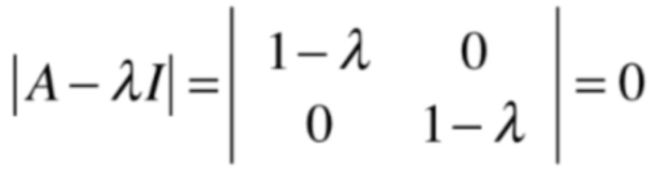
就是求下面这个方程:
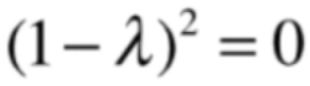
而λ很显然就是:
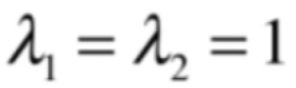
然后此时再来求一下它所对应的特征向量,将λ代入如下方程:
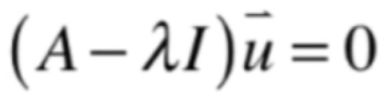
为:

也就是求解矩阵的零空间了,很明显这个矩阵压根就木有主元列,有2个自由列,所以这个向量u有两个维度,两个维度都任意取,也就是二维平面上所有向量都是特征向量,当然也可以找到二维平面上的一组基,用这组基可以更加好的描述特征向量,也就是需要求λ=1所对应的特征空间,其实也就是特征空间中对应的一组基,这组基为:

这里需要注意了:当λ是多重特征值时,λ它所对应的特征空间不一定是一根直线了,有可能是一个高维空间,比如这个λ所对应的空间是一个二维空间,在二维空间中可以找到一组基,由这组基的线性组合所表示的所有向量都是λ=1所对应的特征向量,貌似这结果挺好的呀,对于之前的简单特征值都是2个不同的,所对应的特征向量一定是线性无关的,现在虽说λ是相同的2个特征值,特征空间是一个平面,又找到了两组基是线性无关的,貌似挺不错的,但是关键在于对于多重特征值来说是不能保证重数为2,相应的特征空间就是2维的,就能找到2个基向量,下面再来看这么个矩阵:
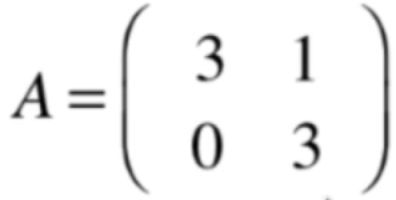
很显然此时的特征值也是相同的值,为:
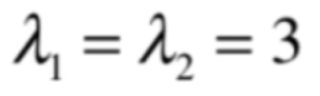
那此时看好了,对于它的特征向量看一下:

很显然此时没有2个自由列了,而是只有一个,当然对应的零空间的维度一定为1,也就是u对应的向量为:
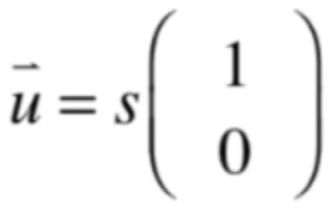
是不是对于这样的矩阵它有二重的特征值,但是呢它对应线性无关的相向只有1个,也就是λ=3虽说是2重特征值,可以这个2重特征值所对应的特征空间是一维的,我们找不到两个线性无关的特征向量,这就是多重特征值复杂的地方,也就是对于多重特征值所对应的特征向量也是多重的,但是也有可以数目会更少。
重要性质:
实际上,从数学的角度是存在这么一个非常重要的性质的:
如果矩阵A的某个特征值的重数=k,则对应的特征空间的维度<=k。
而通常又把这两处重数用两个专有名词定义如下:

所以一个非常重要的数学定理就出来了:
几何重数不大于代数重数,若重数为1,则很简单,其特征空间维度为1。
当重数一旦不为1的话,事情会复杂,这个复杂的点其实就在于相应的特征向量所处的维度,也就是这个维度变得不固定了,可能<=代数重数的任意一个值,这就为进一步研究特征值和特征向量的性质制造了麻烦,也就是为啥在之前说更喜欢"简单"特征值的原因,因为对于简单特征值来说重数为1所对应的特征向量一定是在1维空间中,这个特征空间就一定是1维的。
最后再对三种特征值总结一下:
1、复数特征值它的几何意义丢失了,因为在几何意义上无法直观的理解特征值和特征向量了。
2、多重特征值之所以复杂, 是因为特征值所对应的特征空间的维度不固定。
3、简单的特征值每一个特征值对应于一个特征空间,这个特征空间一定是一维的,相应的特征向量可以随意的缩放,而且不同的特征值对应的特征向量还是线性无关的,这也是喜欢它的原因。
实践Numpy中求解特征值和特征向量:
接下来则回到python的世界中实现对一个矩阵的特征值和特征向量的求解, 先回忆一下整个的求解过程:

由于咱们现在为止手动编写的线性库中并木有涉及到n次方程的求解,所以这里采用Numpy数学库来实现。
新建文件:

示例一:
先来对之前学习的这个矩阵进行一下求解:
具体求解也非常简单,直接调用一个函数既可:
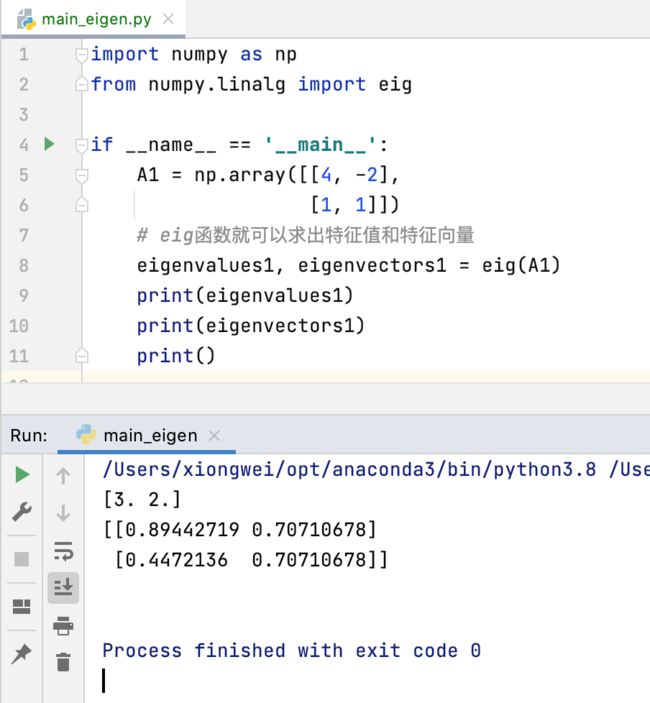
其中可以看到对于求出来的特征值eig函数对其进行了一个排序。另外对于特征向量它是一列列进行组合的:
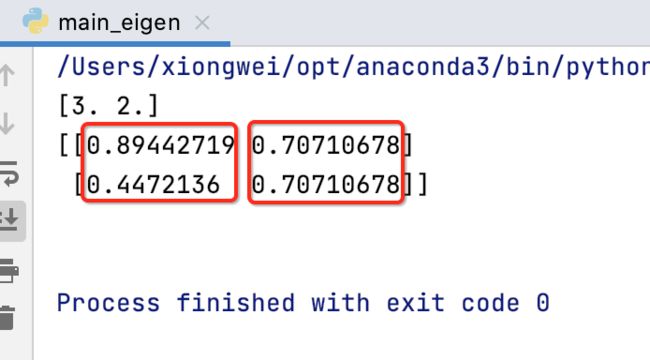
呃,为啥跟我们之前理论描述的特征向量不一致呢?这是(4,-2)向量和(1,1)向量经过规一化处理了,而这种规一化本身是很有意义的,在后续的学习中也能看到,就会将所有的特征向量这样一列列排起来形成一个特征向量矩阵,用这个特征向量矩阵作为空间的基将会看到很多重要的性质,而这组基要想得到它的单位基的话【也就是每一个向量所对应的模为1】,则每一个向量需进行规一化的处理。
示例二:关于y=x翻转
接下来再来验证一下之前所举的y=x翻转变换矩阵的情况:
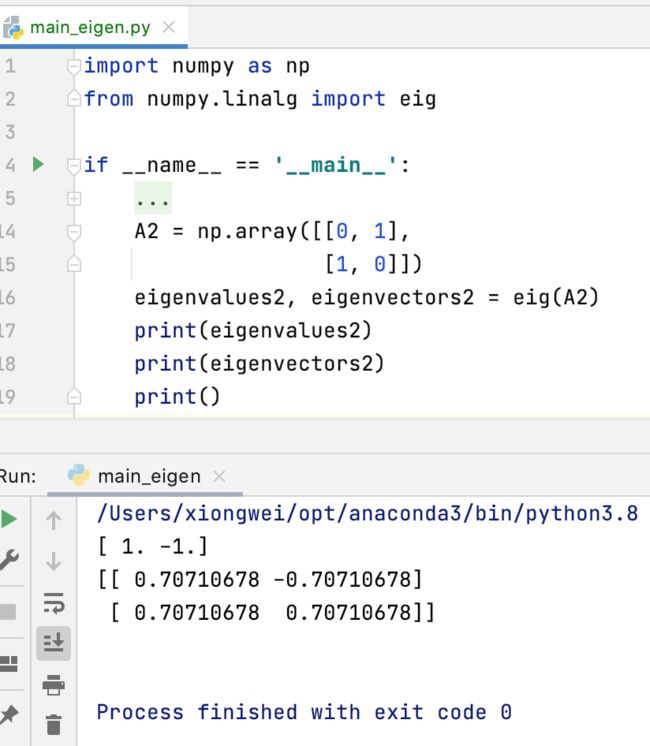
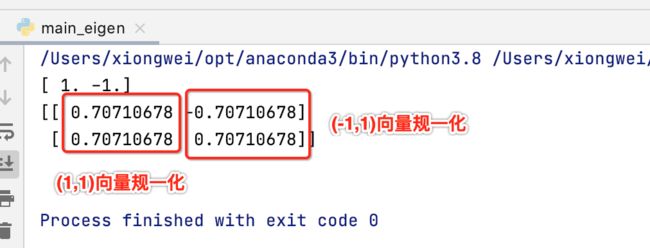
示例三:旋转90度
接下来看一下复数特征值的情况:

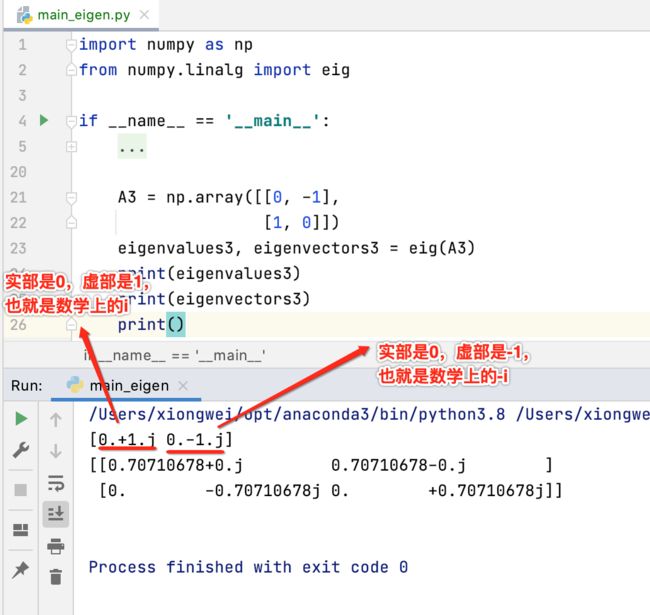
示例三:单位矩阵
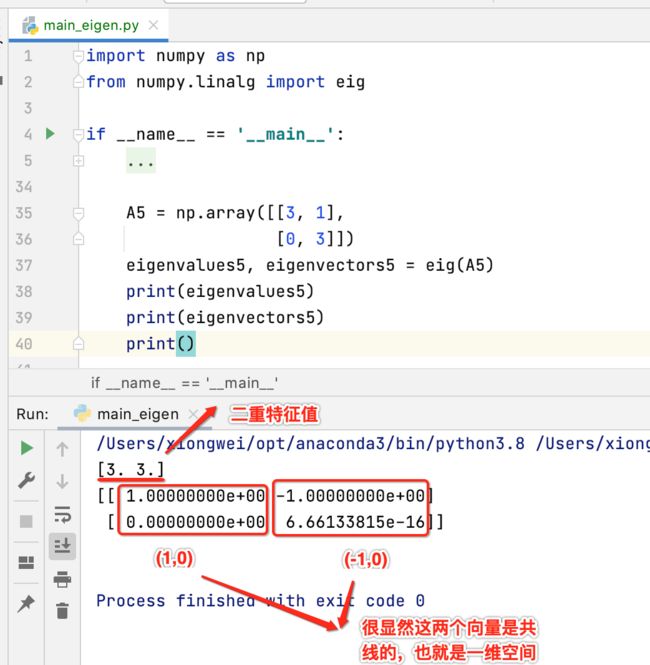
接下来再来看一下多重特征值的情况:

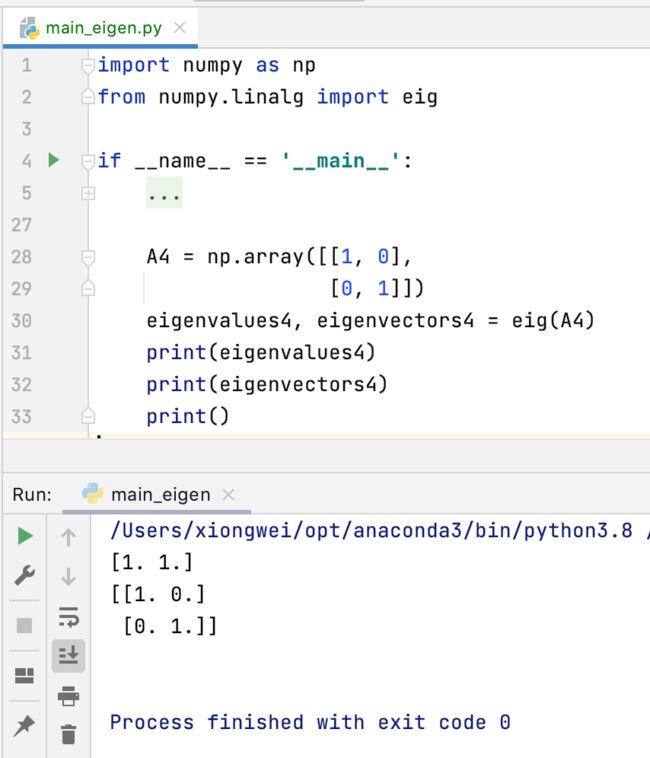
示例四:代数重数为2,几何重数为1
矩阵相似和背后的重要含义:
接下来则来揭示一下学习特征值和特征向量具体有啥用,既然是“特征”值和“特征”向量,那到底反应了矩阵的什么特征呢?
矩阵相似型:
为了搞清楚这个问题,首先得来理解矩阵的相似性,相似矩阵,先来看一下它的定义:
如果矩阵A,B满足:
则称A和B矩阵相似。
说实话看到这个定义还是非常抽象的,其实从几何的角度还是比较容易理解的,这里先来回忆一下初中几何的相似三角形的数学知识,怎么判断两个三角形相似呢?

课本的定义是对于三角形的三个内角如果都相同则就可以说这俩三角形是相似的,直观的来看就是两个三角形的大小是不一样而形状是一样的,怎么理解?其实可以以这样的视角来理解:“不同的视角观察相同的内容”,也就是说可以想象成这两个三角形就是一个三角形,只是观察它的视角可能是远近不一样就造成了所看到的大小不同但是它们的形状却是一样的,此时就可以说这两个三角形是相似的,同样的视角也可以用来理解什么是矩阵的相似,两个矩阵相似其实本质也是我们从不同的视角去观察相同的内容,由于视角不同看到的矩阵也不同,其实本质是一样的,此时就可以说A,B是相似的,具体怎样通过不同的视角来观察相同的内容,这个视角就藏在矩阵P当中,我们如果将P当成是一个坐标转换矩阵的话,而矩阵A和B对应两个线性变换的矩阵,这个式子其实在反应这样的一个事实:
P是一个坐标系,则A变换是在P坐标系下观察的B变换。
换句话说就是这个式子所反应的意思是A和B两个矩阵所表示的变换是同一个变换,只不过观察它所在的坐标系是不同的,我们观察B这个变换就是在我们通常所在的那个标准坐标系下,而我们观察A的坐标系则是在P这个矩阵所定义的坐标系下,在两个不同的坐标系下观察同一个变换得到的结果不同的,结果就是矩阵A和矩阵B,但是本质是同一个变换,此时就可以称A和B是相似的。接下来咱们来证明一下这个结论,此时就需要用到之前线性代数学习之坐标转换和线性变换 - cexo - 博客园所学的坐标转换的知识了,照这样的理论用式子可以这样表示:
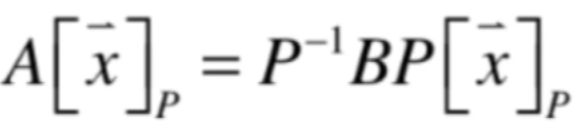
下面具体来看一下式子,先来看等式左边:
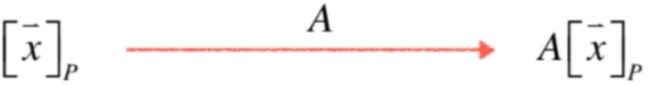
等式左边表示在p坐标系下的向量x进行A变换,而等式右边:

其实就是x在标准坐标系下的坐标:
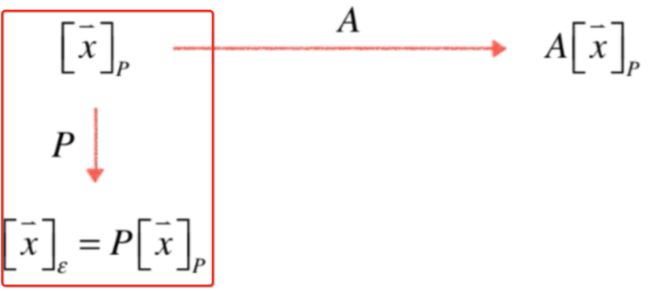
接下来:
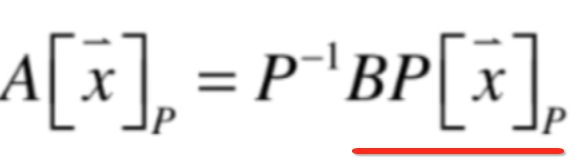
其实就是再进行一个B变换,如下:
也就是x坐标在标准坐标系下经过B变换得到的坐标,该坐标依然在标准坐标系下,那如果想要将这个坐标转换到P坐标系下呢?根据当时学习任意坐标系下的转换:
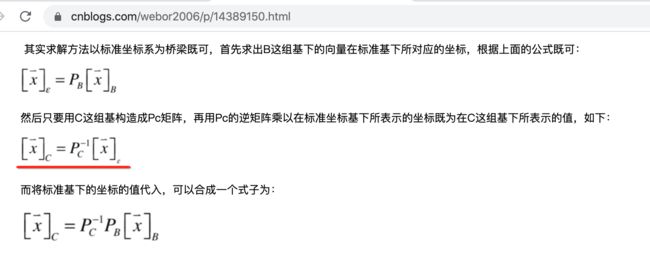
只需要用P的逆矩阵乘以在标准坐标基下所表示的坐标既为在p坐标系下的向量x进行A变换,如下:
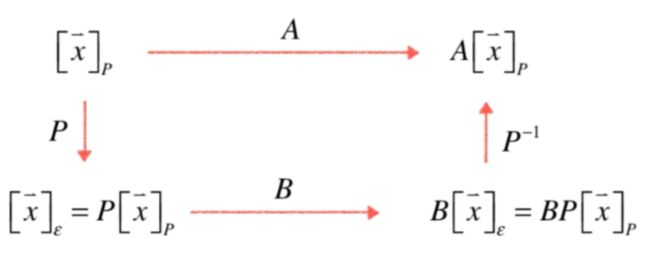
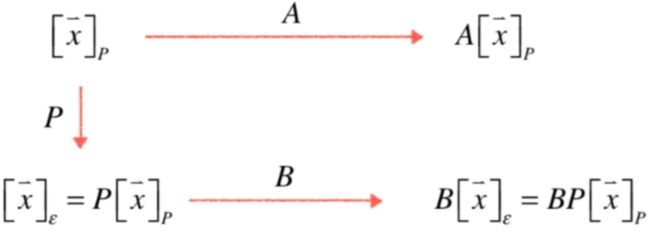
这图说明了一个p坐标系下的坐标先转换到标准坐标系:
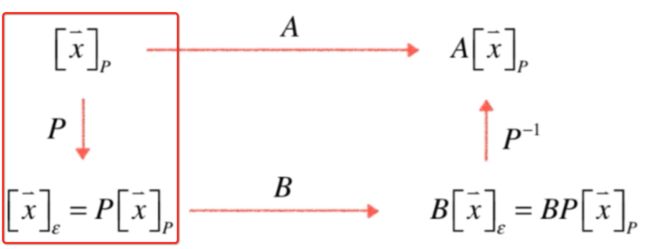
再进行B变换之后还是在标准坐标系下:

此时再转回p这个坐标系下:

这个结果其实在p这个坐标系下直接对坐标x进行A变换得到的结果是一致的:
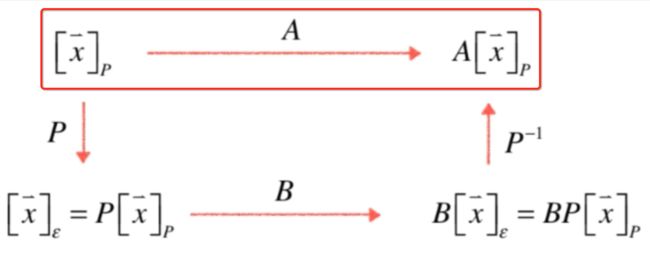
也就说明了A和B这两个变换本质是一个变换,只不过我们所观察的坐标系不同,上面我们观察A变换是在P这个坐标系下,而下面B变换是在标准坐标系下:
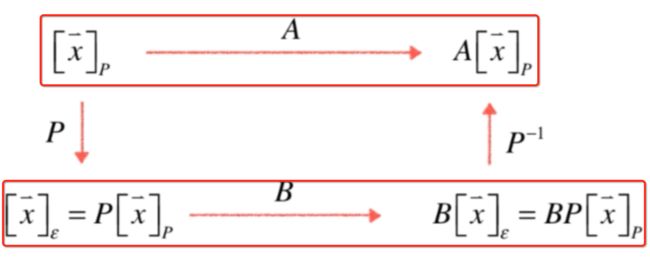
所以上面这个图要记住这个结论:
A和B本质是一个变换,只是观察的坐标系不同!
有了这个结论之后,接下来就可以对式子进行一下变换了:

变形的方法很简单:
1、等号两边都左乘一个P;
2、等号两边都右乘一个P逆;
所以对于这个变换式子,在阐述“A变换是在P坐标系下观察的B变换”是不是这样来理解更加的顺畅,因为A这个变换是在P坐标系下观察的,所以将P这个坐标系下的项都放到等号右边,而将B单独拿出来,因为B这个变换就是在标准坐标系下看的,所以就有了同在所看到在标准坐标系下变换的B到了P这个坐标系下看和等号中的A这个变换是一样的,这里要注意!!!当我们说矩阵相似的时候,A和B相似,B和A也相似,此时用这两个式子都是可以的;
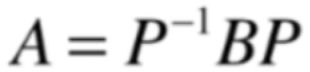
在这种情况下,P逆和P谁在前谁在后其实不重要:

但是!!!一旦有了几何解释的时候就得非常注意啦,P逆和P谁在前谁在后决定了到底把哪个变换放在P坐标系下观察,P逆在前P在后:
我们是把夹在P之外的那个变换,也就是A变换放在P坐标系下观察,而如果P在前P逆在后:
我们是把夹在P之内的那个变换,也就是A变换放在P坐标系下观察,对于这个结论不需要背,而是要理解,那怎么理解呢?其实可以这样理解:
等号的两边同时乘以一个坐标,关键是在有几何解释的时候乘以哪个坐标系下的坐标有意义,像P在最后的话肯定要乘以在P坐标系下的坐标才有意义,所以:
A这个变换是在P坐标系下进行的,相应的B这个变换就是在标准坐标系下进行的;同样的像P逆在最后的话肯定要乘以在标准坐标系下的坐标才有意义,所以:
B这个变换是在标准坐标系下进行的,相应的A这个变换就是在P坐标系下进行的;同样的像P逆在最后的话肯定要乘以在标准坐标系下的坐标才有意义。
上面这个理解说实话有点绕,记住关键的结论是:“A和B本质是一个变换,只是观察的坐标系不同!!”,另外一定要注意小陷阱,怎么写式子代表哪个坐标系下来观察A和B两个变换,其实这个跟之前学习坐标变换是一样的,一定要知道是谁变到谁,关于坐标变换这块不太清楚的一定得要提前打好基础把这一个知识理解透了再来对这里进行理解就会容易很多。
那这个矩阵的相似型跟我们此次学习的特征有啥关系呢?下面就准备要跟它牵扯上联系了,既然A和B本质是一个变换,它们肯定有一些东西是相同的,就像两个三角形相似,相似背后它们的角肯定是相同的,那么A和B相似本质是一个变换,它们是什么相同呢?其实是A和B的特征方程相同,特征值相同!!!这也是为啥管之前的特征值和特征向量叫“特征”的原因之所在,这是因为这些特征是永远不会变的,不管我们是在哪个坐标系下来观察A和B矩阵的样子可能已经变了,但是它们的特征方程是相同的,既然特征方程相同了其特征值也就相同啦,所以在之后会学习特征值的作用了:完全可以使用特征值构造出一个矩阵,这个矩阵就来表示A和B所对应的那个变换,只不过需要从一个特殊的坐标系中来看。
下面则来证明一下此观点:
如果矩阵A,B满足:
则称A和B相似,A和B的特征方程相同!特征值相同!!
证明:
A的特征方程为:
而为了能跟P逆BP进行结合,可以把I写为:
然后它又可能变为:
而根据行列式的矩阵相乘就又可变为:
再进一步:
看到木有,也就是A和B的特征方程是相同的,前提是矩阵A,B满足:
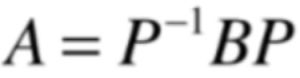
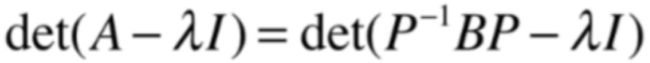
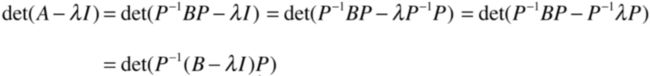
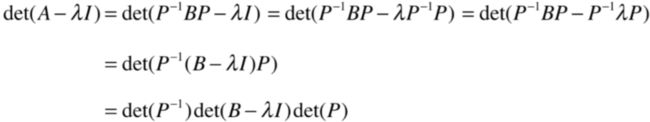
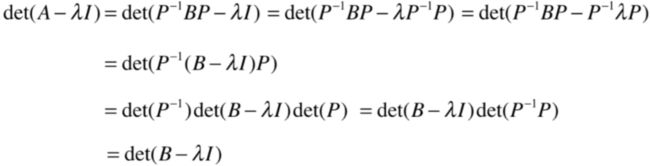
这也就是特征值和特征向量所真正表达的特征,当我们把矩阵当作是一个变换的时候,这个变换不管从哪个角度去看,不管从哪个坐标系下去看,它们都拥有相同的特征,这些相同的特征都被特征值表达了出来,那么有个问题就来了,既然我们已经知道了对于一个变换我们可以从不同的角度去看它,肯定就希望找到一个最好的角度去看它让变换的理解是最为容易的,那这个“最好的角度”其实也隐藏在特征值和特征向量中,具体往下学习便知。
矩阵对角化:
先来再阐述一下上面所述的结论:
如果矩阵A,B满足:
则称A和B相似,也可以表达成:
P是一个坐标系,则A变换是在P坐标系下观察的B变换【这也就是几何含义,表示在P这个坐标系下观察B变换观察到的结果其实就是A这个矩阵所表示的样子 】,A和B本质是一个变换,只是观察的坐标系不同!

那既然式子:
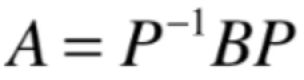
表达的是“在P这个坐标系下观察B变换观察到的结果其实就是A这个矩阵所表示的样子”,那就可以变换坐标系P,相应的A这个矩阵的样子就会发生变换,我们想找一个最好的A,使得B这个变换非常之简单,其实就是矩阵对角化所做的任务,其实矩阵对角化是指可能把A写成是:
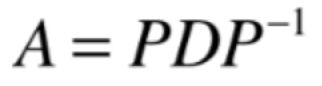
表达的意思就是对于A这个变换我们在P这个坐标系下观察,观察到的结果是D,在这里要注意在P的坐标系下观察谁得到谁不要搞淆,根据之前所述:

所以A的变换是在标准基下的变换,在P这个坐标系下观察A这个变换, 得到的是结果是D变换的样子,其中A、D本质是一个变换,只是观察的坐标系不同而已,那为啥这里用了一个D矩阵呢?因为它代表一个对角矩阵:
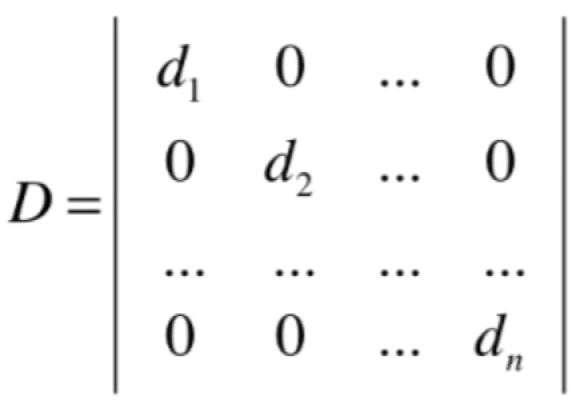
而对角矩阵代表啥呢?其实它就代表对于一个向量x每一个维度的向量伸缩di倍就好了,不牵扯到和其它维度的向量进行线性组合,换言之,就是在D这个变换下,对向量(x1,x2,x3...,xn)进行变换,结果就是(d1x1,d2x2,...,dnxn),所以对角矩阵所表示的变换是最简单的,而矩阵的对角化所做的事情就是对于任意一个变换A,试图找到一个合适的坐标系P,在这个坐标系下观察A变换变成了一个对角矩阵的样子,这个样子是非常方便我们进行很多操作的,那么问题的关健就是对于方阵A能不能在某一个坐标系P下观察看到的结果是一个对角矩阵的样子呢?不一样!!!因为需要有如下条件:
如果A有n个线性无关的特征向量,则A和某个D【对角矩阵】相似。
也就是可以写成这个形式:
这个式子就叫做把A这个矩阵进行了对角化,所以对于矩阵的对角化也可以理解是矩阵的分解的一种形式,把矩阵A分解成了三部分:

它表示D变换是P坐标系下观察到的A,而A怎么能分解成这种形式呢?答案就隐藏在特征值和特征向量当中,下面直接给结论,也就是如果矩阵A可以进行对角化的话,其中D对角矩阵就是主对角元素是矩阵A对应的所有的特征值,如下:

而P这个坐标系就是把这些特征值所对应的特征向量依次按列排列出来的结果就是P这个矩阵,如下:
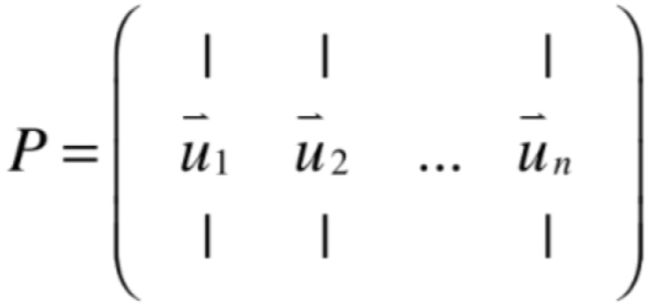
由于P是由所有的特征向量组成的矩阵,所以也叫特征向量矩阵,换言之,如果矩阵A可以被对角化的话,A这个矩阵和对角矩阵D相似,就可以在这个特征向量矩阵所代表的坐标系才能看到这个结果,而我们看到的这个结果对角矩阵D的主对角线上就全都是特征值,通过这个结论现在就明白为啥有这么一个前提了:

这是因为这n个线性无关的特征向量要组成特征向量矩阵,而这个特征向量矩阵中所有的列元素构成了一个空间的基,它是我们观察A另外的一个坐标系,如果A木有n个线性无关的特征向量的话,就不能构成矩阵P,A对应的也就不能对角化。我们也可以从另外一个视角来思考,由于P需要使用逆矩阵:
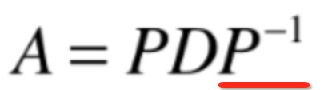
所以对于P这个矩阵的列元素一定是线性无关的,这是矩阵N个命题中的一条,回忆一下:

接下来证明一下为啥有n个线性无关的向量的矩阵A满足这个式子:
先左右乘以一个P,如下:
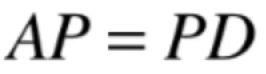
此时则左右两边进行变换,看最终左右两边是否相等那么也就论证了此式子了,如下:
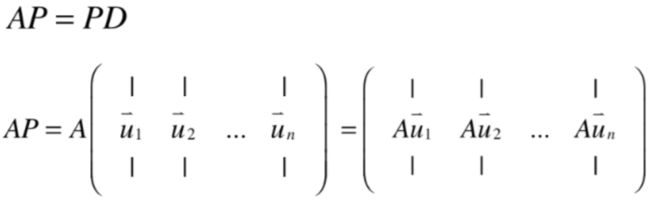
而由于所有的u都是矩阵A的特征向量,所以Au等于λu,回忆一下:

所以:
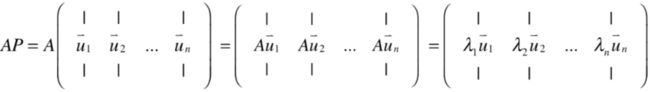
接下来再来看一下等式右侧,如下:
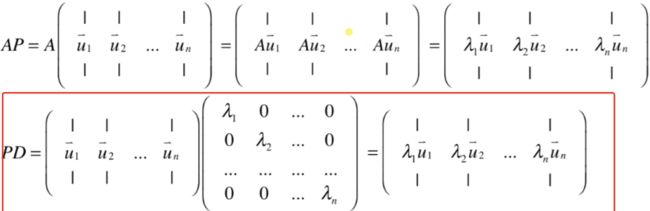
所以:
就成立了,所以它也成立:
此时就可以称A可以被对角化。
另外回忆一下上面的一个结论:
如果矩阵A含有两个不同的特征值,则他们对应的特征向量线性无关,而回到对角化的概念就可以进一步推导出:如果A有n个不相同的特征值,则A可以被对角化,但是要注意:如果A没有n个不相同的特征值,A不一定不能被对角化。比如说:

再来看一个:

这也是当特征值存在重数的时候,事情变得复杂的原因,这是因为所有的特征值重数为1,矩阵A只含有简单特征值的话,它一定可以对角化,因为A就可以从P的视角:
来看是一个对角矩阵所代表的那个变换,这也是为啥叫它简单值的原因,但是如果含有重数的特征值,它能不能对角化我们就不知道了,至少我们不能一眼就看出来而是需要具体的求一求对于有重复的特征值它所对应的特征空间的维度是多少,不管怎样,如果A能找到n个无关的特征向量,A就一定能够被对角化。最后再来总结一下:

实现属于自己的矩阵对角化:
接下来编程来实现一下矩阵的对角化。
新建文件:
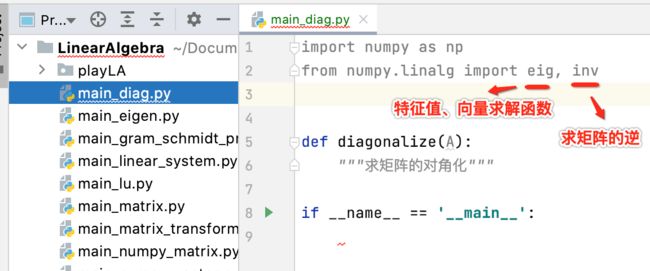
断言A为方阵:
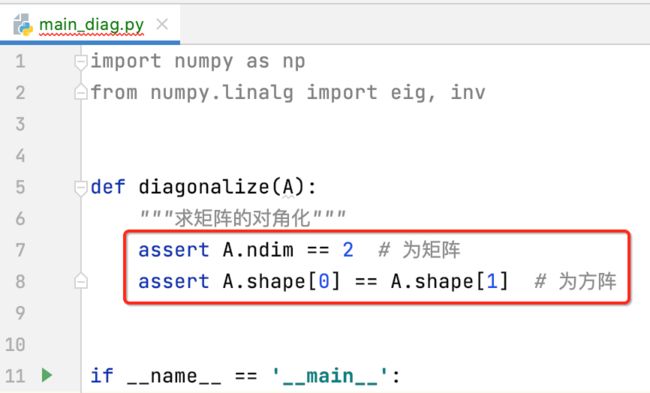
求出A的特征值和特征向量:
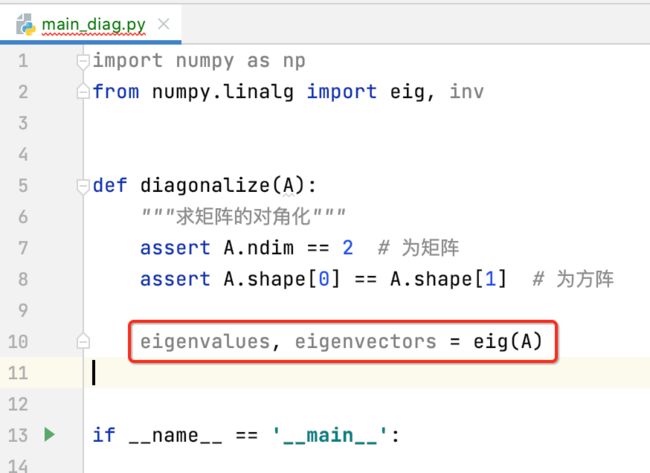
求出矩阵对角化:
对角化的式子为:

测试:
用例一:

为了验证其求解的对角化是正确的,就可以把三个相乘,如下:
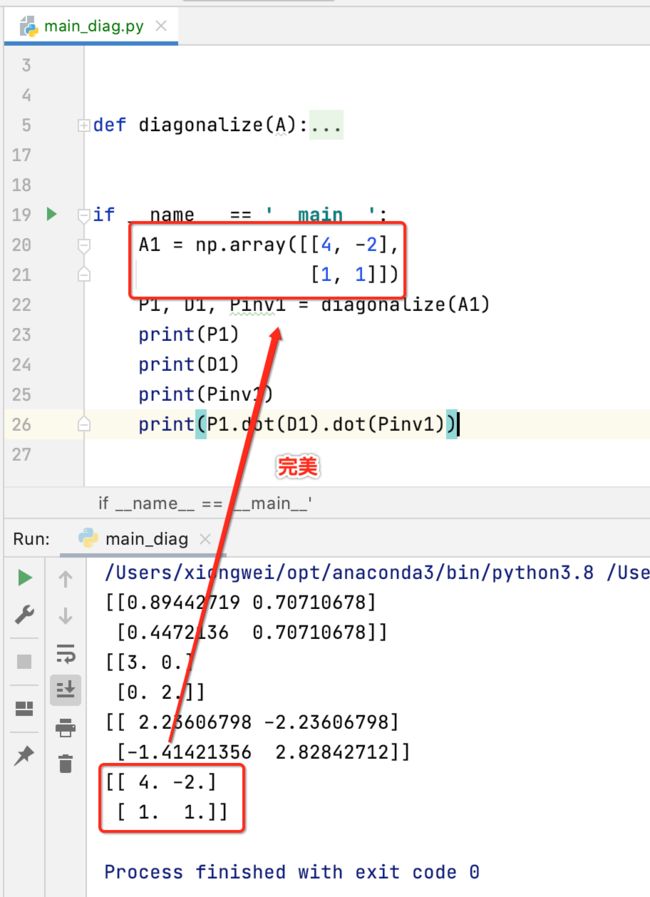
用例二:

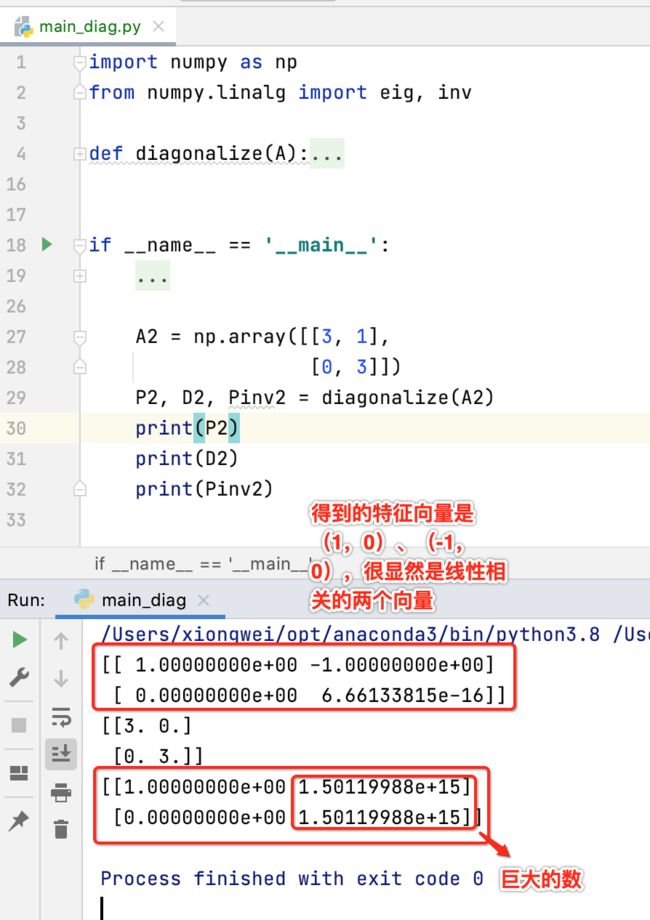
由于该矩阵不能被对角化,所以照道理P的逆应该不存在,但是nmpy也对其进行了一个逆的计算,只是计算出来的结果比较离普而已。
增加是否可对角化的判断:
对于用例二来说,很显然矩阵是不能被对角化的,但是呢其结论我们看不出来,所以有必要增加一个矩阵是否可逆的状态输出,如下:
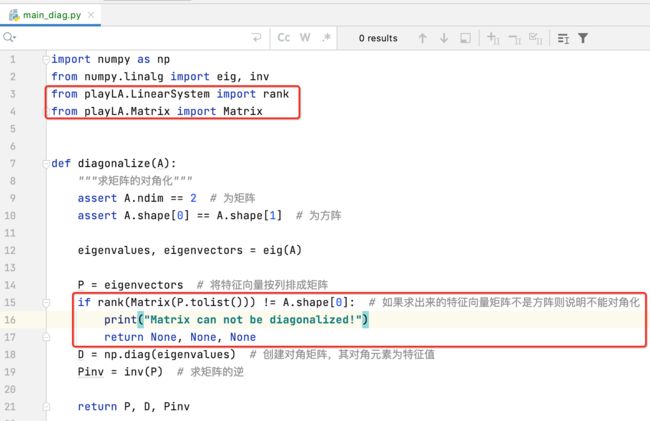
再运行:

矩阵对角化的应用:求解矩阵的幂和动态系统【了解】:
最后再来探讨一下矩阵的对角化,先来回忆一下相关定义:
如果A有n个线性无关的特征向量,则A可以被对角化,就有如下式了:
其中可以说D变换是P坐标系下观察到的A。也就是D变换和A变换本质是一个变换,只不过观察的坐标系不同,而由于D是一个对角矩阵,所以这个变换是非常简单的,只不过是在每一个维度上伸缩对角矩阵对角线上元素那么多倍。
而如果把D变换看作是A变换,很多时候就会变得非常简单,下面举相应的一些例子:
求解矩阵的幂:
比如要求矩阵A的平方:

当然直接用A*A既可,但是如果将A以对角化视角来看待的话:
此时就可以变换为:
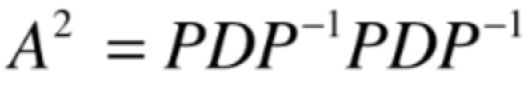
再变换就为:

以对角化视角下面再来看一下A的立方就如下:
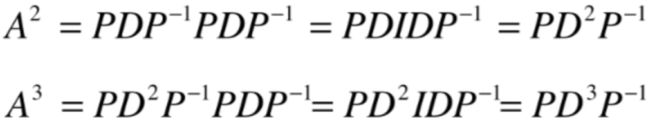
进而可以得到矩阵求幂的新视角:
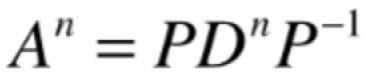
也就是把A的n次方问题转换成了D的n次方问题,而其中D是一个对角矩阵,下面来看一下为啥把A的变换看成D的话会很方便了,比如对于一个对角矩阵D:

而它的平方为:

也就是对于对角矩阵求它的幂也就是对角元素的幂再放回到对角矩阵上,推到n次晕就有如下式子:
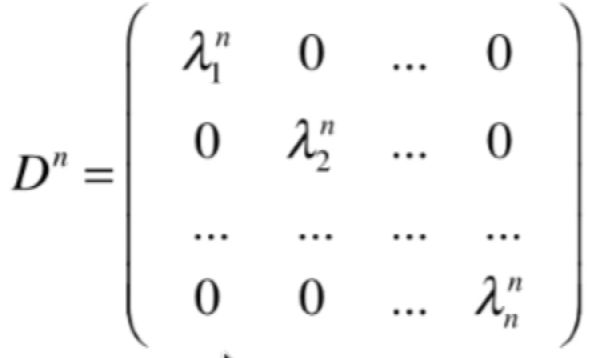
也就是对于对角矩阵的幂的求法根本不需要进行矩阵的乘法操作,直接对数字进行n次幂的运算既可,很显然相对矩阵的乘法就大大的化简了,相应的,如果求解A的n次冪就为:
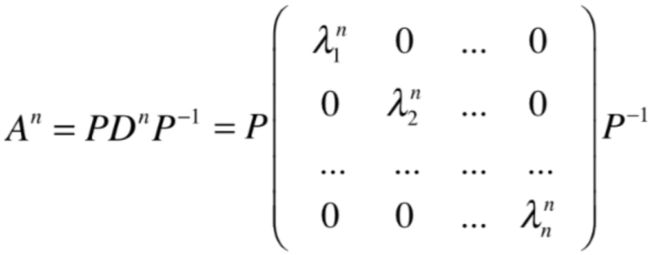
这样通过矩阵的对角化对于整个矩阵的幂计算时间复杂度也大大的降低,
求解矩阵的动态系统:
我们为啥要关心矩阵的幂呢?实际上矩阵的幂在大量的实际应用中都有着非常重要的作用,因为大量问题的形式都是:
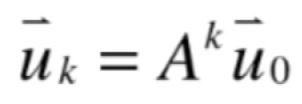
为啥向量有一个下标呢?这是因为处理的是动态系统,也就是随着时间的变换u这个向量所表示的状态也在不断的变化,这个变化是被A所表示的,比如第一个时间点【一个时间点在经济系统中有可能是一年,一个月之类的,而在生物学观察细胞时是以秒或分钟为单位】表示u这个状态就变成了Au,而到了第二个时间点u这个状态又变成了A方u,第三个时间点就变成了A的立方u...以此类推。
而动态系统这个方程的形式被用于很多的领域,比如说:
经济系统:
比如u这个向量表示的是各个不同的行业不同的领域所对应的经济的生态值,而这个经济的生态值随着时间的推移,会产生变化,这个变化就可以被矩阵A所表示,这个A矩阵可能就表示一种经济策略,我们要想看这个经济策略在若干时间后所起到的效果是怎样的,我们就可以使用这个式子。
粒子系统:
比如在物理学中,很多粒子系统也都满足这样的式子,粒子运动具有一定的规律,而这个规律被矩阵A所表示,相应的某一个粒子在若干时间后它所对应的状态是怎样的,就可以用这么一个方程所表示。
生态系统:
在生态系统中也是如此,生态系统中无论是动植物的数量还是各种环境的参数,比如氧气,二氧化碳,氮气等等它们都是互相制约的,而在生态系统中这些参数会怎样变化也可以被一个矩阵A来表示,而若干时间后生态系统这些参数会怎样变化也可以被矩阵A所表示,而若干时间后生态系统会变成什么样子也可以被这样的一个方程所表示。
而对于这么一个式子:
核心就是求A的k次幂,根据这个式子:
此时就可以变换为:
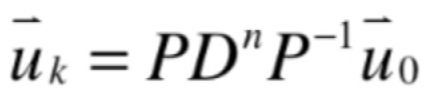
更重要的是,一旦有了对角化视角,其实对于想研究的系统还可以有一个更深刻的认识,这是因为A这个变化本质就是D这个变化,只不过需要在P这个坐标系下观察而已,而D这个矩阵表示的就是对于u这个向量各个维度它随着时间的推移每走一个时间点相应怎样变化,那么D这个矩阵对角线上的元素又都是A这个矩阵的特征值,所以特征值反应系统的各个分量的变化速率!只不过这个变化是发生在P这个坐标系下的,这也是特征值隐藏的另一层含义,就会对动态系统有更加深刻的认识,延生出稳定的系统、不稳定的系统等相应的概念。
但是!!!上面所说的得具备一个前提条件,如下:
如果A有n个线性无关的特征向量,则A可以被对角化。
而目前对于A只是对方阵有作用,而实际生活中经常要处理非方阵或长方阵,那对于这种情况的探讨下次再来。
关注个人公众号,获得实时推送
