智能反欺诈算法概览及典型应用案例
从上个世纪90年代开始,由于反欺诈领域大数据量和高时效性需求,机器学习技术得到逐步应用:
Kokkinaki(1997)提出一种基于决策树逻辑的模型,其中子节点代表不同的变量,分叉路经代表满足不同的条件;
Bentley(2000)运用基因算法来搭建一套逻辑规则,可以根据最大发生概率将交易行为划分为可疑和非可疑;
Bolton和Hand(2002)利用对等组分析和断点分析,从账户和个体的角度判断行为链上的欺诈;
此外,Dorronsoro(1997)基于神经网络算法设计了一套在线欺诈跟踪系统;
Maes(2002)将贝叶斯网络应用到信用卡领域。
上述技术都是有监督学习方法论,需要大量欺诈样本来训练模型或者系统。银行在实际应用中往往面临缺少足够欺诈样本的问题,因此目前业内传统的反欺诈手段还是利用专家规则,通过吸取业务专家经验以及过去发生的欺诈案例来创建规则库。专家规则具有更新不及时、误报率高、维护费用昂贵等问题,因此有必要应用先进技术构建智能反欺诈模型。
❶
反欺诈算法库
通过查阅国内外文献,总结出以下几个适用于银行反欺诈领域的机器学习和深度学习算法,包括无监督和有监督两方面:
1、SKM:种子k均值聚类算法(Seeded k-means Clustering Algorithm),简称SKM,利用好坏客户人群区分度高的特点,将所有客户分为两个聚类,同一聚类中的客户相似度较高,而不同聚类间的客户相似度较低。
选取客户数目少的聚类作为异常客户,每个异常客户到正常客户聚类中心的距离即为客户异常评分,评分越高越异常。
聚类分析擅长从多维度整体考虑客户之间的差异性,极值两端分布的变量对模型结果影响大,运算效率高,结果可解释性好;但是容易忽略单个指标的决定性作用,且划分结果不够精确。
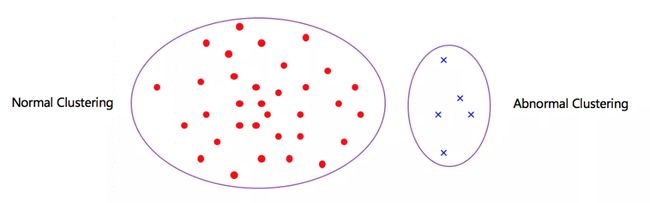
图1 SKM算法原理图
2、Isolation Forest:孤立森林(Isolation Forest),运用于挖掘异常数据的无监督模型,利用坏客户与规律相比的差异性来划分。
每次随机选取一定数量的样本客户训练一棵iTree树,特征顺序与分割值任选;重复多次后得到iForest森林。将全量客户沿着每棵iTree到达叶子节点,每个客户在iForest中距离根节点的平均路径长度作为客户异常评分,路径长度越短越异常。
孤立森林擅长考虑每个维度对于异常客户划分的影响,极值单侧分布的变量更容易区分出异常客户,且结果更为精确;然而无法从整体上考虑好坏客户的差异,并且算法复杂度高,结果解释性一般。

图2 Isolation Forest算法原理图
3、Auto Encoder:自编码网络(Auto Encoder)是一种适用于无监督场景下的深度学习网络模型,其主要用途是将数据进行压缩,然后再在需要的时候用损失尽量小的方式将数据恢复出来。
自编码网络中,输出层的神经元数量完全等于输入层的神经元数量,通过控制隐藏层神经元的数量来达到数据压缩的目的。
在反欺诈场景中,由于欺诈客户与正常客户在交易行为上存在较大差异,对于整个数据集来说是冗余信息,因而自编码网络通过学习发现并通过压缩和解压缩的方法去掉这些冗余信息。自编码网络目前还没有在银行反欺诈领域中有过大规模应用,其对数据量和计算环境的高要求还有待进一步探索。
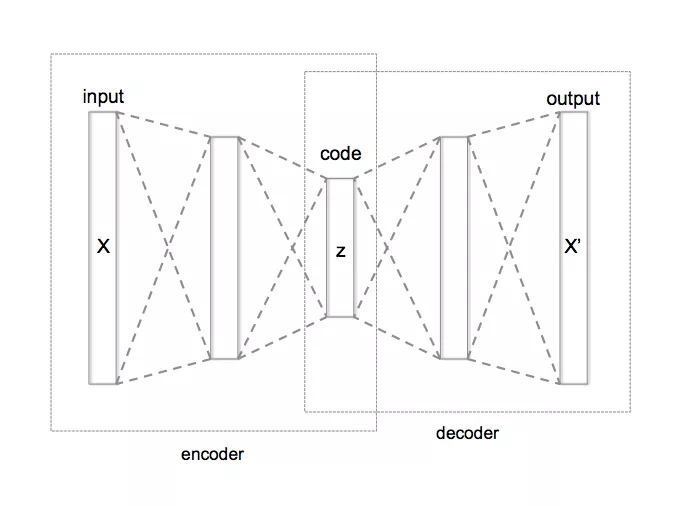
图3 Auto Encoder算法原理图
4、CNN:卷积神经网络(Convolutional Neural Network)最早被用于图像处理和识别的场景中,主要由卷积层和池化层构成。
卷积层是卷积神经网络的核心,通过固定大小的卷积核的移动构造局部连接,利用参数共享大大减小网络模型计算的复杂度;池化层通常夹杂在卷积层之间或者之后,通过池化操作提取变量特征,提高计算效率的同时防止过拟合。
在客户交易分析中,由于交易链与图像类似都具有相关性,并且距离越近相关性越大,因此可以通过选取相关交易行为的办法,将某一时刻的1D交易链转化为2D交易链图像,再利用卷积神经网络训练并且找出异常客户行为。
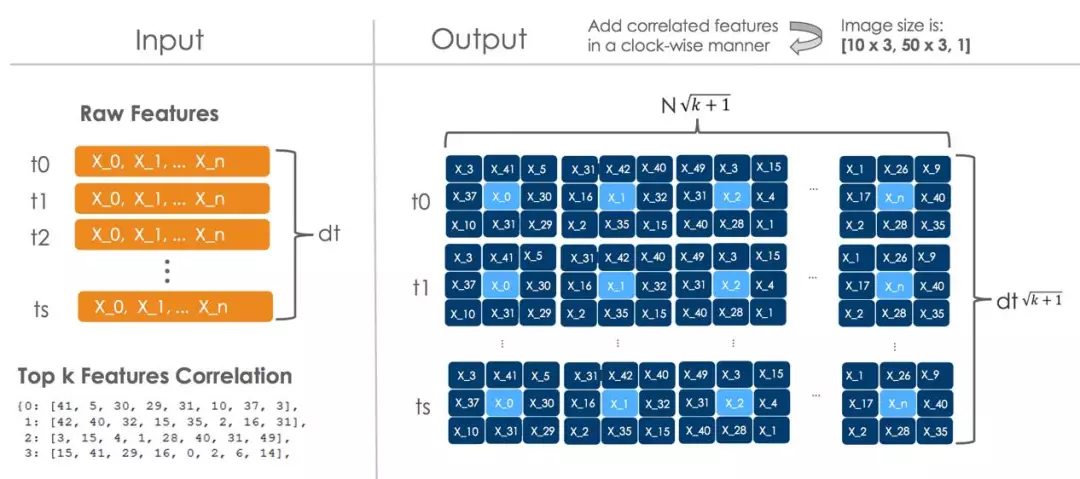
图4 CNN中交易链数据转化
5、LSTM:长短期记忆网络(Long Short Term Memory,LSTM)是基于RNN基础上的一种优化神经网络模型,其优势是可以处理现实生活中的一些需要长期依赖历史记忆的场景,而传统的RNN模型不具备学习如此远信息的能力。
长短期记忆网络的核心是在RNN算法中加入了一个判断信息是否有用的“处理器”,包括输入门、遗忘门和输出门,其中只有符合模型条件的信息才会被留下,其余信息会通过遗忘门被省去。
将长短期记忆网络应用到交易链场景中,可以更好地处理和记录交易行为在时间轴上的关联关系,而对于一些异常的交易行为进行区分。
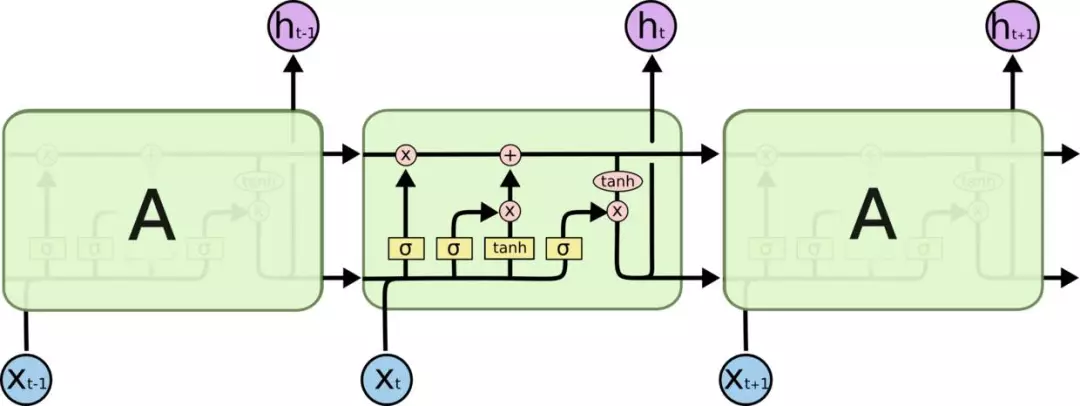
图5 LSTM算法原理图
❷
两个实际应用案例
1
CBiForest反欺诈算法
通过前期数据和需求调研,针对数据特性提出一套基于聚类的孤立森林模型算法(CBiForest)。在无监督的条件下,结合SKM和iForest两者优势,全方面、多层次地判断和追踪欺诈客户。整体建模流程可以分为以下几个步骤:
-
第一步:对于行内交易流水和登录日志数据进行挖掘分析,从交易金额、笔数、时间、类型、地址等多方面构造反欺诈模型特征;
-
第二步:基于关联矩阵、模型验证、业务经验等方法,筛选出重要变量23个,其中按照变量分布特性,将15个U型变量运用到SKM模型,8个长尾型变量运用到iForest模型;
-
第三步:首先利用SKM将所有客户聚成两类,其中数量较少的类被标记为异常客户群体,定义每个点到正常类中心的距离作为SKM异常分数,距离越大越异常;
-
第四步:对于两类客户群体,再分别训练iForest模型,每个点到iTree根结点的平均距离作为iForest异常分数,平均距离越近越异常;
-
第五步:对于每个点,将SKM和iForest模型计算得到的异常分数加权相加,得到聚合模型CBiForest的最终结果。
根据CBiForest模型的计算结果,客户根据异常分数由高到低排列,分数越高,存在欺诈的可能性越大。
2
深度学习技术应用案例
目前国内利用深度学习技术进行银行反欺诈探索的案例还相对较少,这里以DanskeBank的应用项目为例,简单介绍下国际上银行反欺诈项目的领先成果。
基于DanskeBank每秒60笔交易的实时数据,首先尝试利用决策树和逻辑回归的聚合模型,与行内传统规则引擎相比,降低了25-30%的误报率,提高了35%以上的准确性。随后更近一步,利用包括CNN、LSTM在内的多种深度学习模型进行尝试,将测试集上的AUC提高到了0.9以上。
可以预期,伴随国内银行数据环境的优化和硬件系统的升级,这些有监督的深度学习算法也都可以在国内银行业进行尝试,以便进一步提高欺诈行为的主动预测能力。
❸
关于技术与应用的思考
本文对几种算法进行了简要说明,并给了两个实际应用案例。实际上还有其他可以用到的智能算法,只不过案例更多的集中在学术界而非工业界。在银行反欺诈领域,从专家规则到大数据分析规则,然后再到智能化模型规则,这是应对欺诈的技术升级路线,也是银行数字化转型过程中必须具备的能力。
欺诈行为千奇百怪,欺诈与反欺诈从根本上来说还是人与人的较量,双方都是业务专家并且配备技术手段加持。因此在实际反欺诈应用建设过程中,我们需要将更多的精力放到对业务和数据的理解上,针对不同场景选择合适的技术方法。
人工智能是当前热门话题,银行可以多个角度去发现应用场景,其中反欺诈对于数据积累与系统建设的要求最高。关于智能反欺诈,我们有个最朴素的观点,就是通过更丰富的数据与更复杂的算法来应对欺诈风险,当然还需要更加强大的计算平台。