10年Java开发经验,教你解决线上频出MySQL死锁问题!实战解析
程序员:给多少工资,干多少事
我们不是经常会看到一个关于西游记的“悖论”吗:
为什么孙悟空初期大闹天宫的时候那么厉害?因为他自己当老板,打一群天庭的打工仔。
为什么取经路上又变得不行了?作为一个打工仔,去跟一群出来自己创业的妖怪打架。
很多程序员想跟老板说,但又不太敢说,实际却在做的一件事。
事实却是:
“拿着10K的工资,做着20K的事,还要操着30K的心!”
其实,这些情况都不奇怪,甚至是人之常情。
思考
前面提到 Kafka 帮我们实现了各个版本的生产者代码,其实他也可以完全不提供这份代码,因为核心的队列的功能已经实现了,这些客户端的代码也可以完全交由用户自己实现。
那么假如没有官方代码,我们又该实现一些什么功能,有哪些接口,哪些方法,以及如何组织这些代码呢。带着这样的问题我们一起来思考一下!一般对于这种带有数据流转的设计,我会从 由谁产生? 什么数据? 通往哪去? 如何保证通路可靠? 这几个方面来考虑。
消息自然是通过应用程序构造出来并提供给生产者,生产者首先要知道需要将消息发送到哪个 Broker 的哪个 Topic,以及 Topic 的具体 Partition 。那么必然需要配置客户端的 Broker集群地址 ,需要发送的 Topic 名称 ,以及 消息的分区策略 ,是指定到具体的分区还是通过某个 key hash 到不同的分区。
知道了消息要通往哪,还需要知道发送的是什么格式的消息,是字符串还是数字或是被序列化的二进制对象。 消息序列化 将需要消息序列化成字节数组才方便在网络上传输,所以要配置生产者的消息序列化策略,最好是可以通过传递枚举或者类名的方式自动构造序列化器,便于后续序列化过程的扩展。
消息队列常常用于多个系统之间的异步调用,那么这种调用关系就没有强实时依赖。由于发消息到 Kafka 会产生 网络 I/O ,相对来说比较耗时,那么消息发送这一动作除了同步调用, 是否也可以设置为异步,提高生产者的吞吐呢? 。并且大量消息发送场景, 我们可以设置一个窗口,窗口可以是时间维度也可以是消息数量维度,将消息积攒起来批次发送,减少网络 I/O 次数,提高吞吐量。
最后呢为了保证消息可以最大程度的成功发送到 Broker ,我们还需要一些 失败重试机制 ,例如失败后放到重试队列中,隔一段时间尝试再次发送。
理清思路
通过上面的分析,我们会有一个大致的认识,应该会有哪些方法,以及底层的大致的设计会分为哪几个部分。但是不够清楚,不够明晰。
首先总结一下实现客户端的几个要点在于:
-
配置 Broker 基础信息:集群地址、Topic、Partition
-
消息序列化,通过可扩展的序列化器实现
-
消息异步写入缓冲区,网络 I/O 线程实现消息发送
-
消息发送的失败重试机制
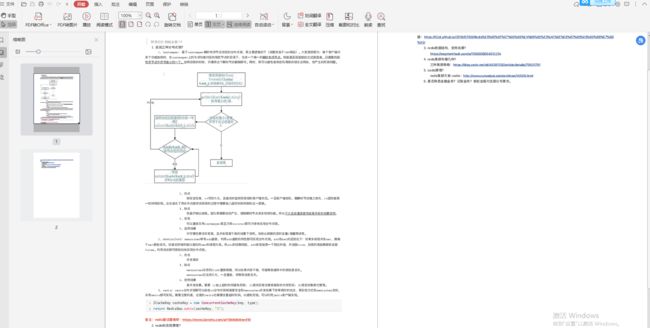
话不多说,用一张图画出各个核心模块以及他们之间的交互顺序:

用户设定 Kafka 集群信息,生产者从 Kafka Broker 上拉取 可用 Kafka 节点、Topic 以及 Partition 对应关系。缓存到生产者成员变量中,如果 Broker 集群有扩容,或者有机器下线需要重新获取这些服务信息。
客户端根据用户设置的序列化器,对消息进行序列化,之后异步的将消息写入到客户端缓冲区。缓冲区内的消息到达一定的数量或者到达一个时间窗口后,网络 I/O 线程将消息从缓冲区取走,发送到 Broker 。
以上就是我对于一个 Kafka 生产者实现的思考,接下来看看官方的代码设计与我们的思路有何差别,他又是为什么这么设计。
官方设计
其实经过上面的思考和整理,我们的设计已经非常接近 Kafka 的官方设计了,官方的模块拆分的更加细致,功能更加独立。
核心组件
首先看一眼 KafkaProducer 类中有哪些成员变量,这些变量就是 Producer 的核心组件。
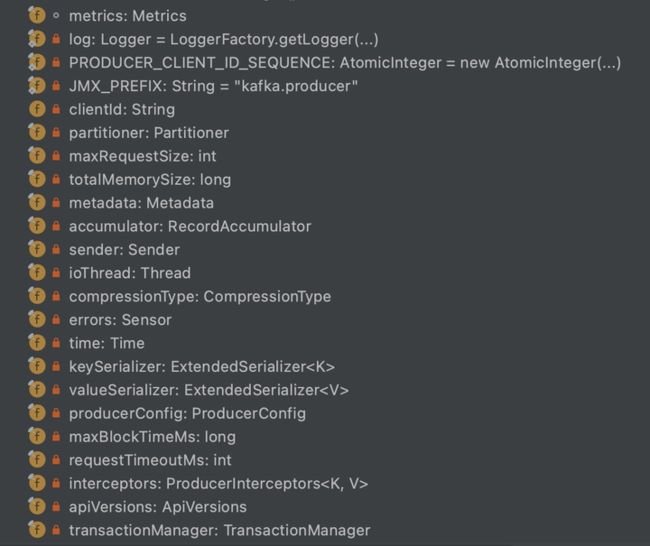
其中核心字段的解释如下:
clinetId :标识发送者Id
metric :统计指标
partitioner :分区器作用是决定消息发到哪个分区。有 key 则按照 key 的 hash ,否则使用 roundrobin
key/value Serializer :消息 key/value 序列化器
interceptors :发送之前/后对消息的统一处理
maxRequestSize :可以发送的最大消息,默认值是1M,即影响一个消息 Record 的大小,此值在服务端也是有限制的。
maxBlockTimeMs :buffer满了或者等待metadata信息的,超时的补偿机制
accumulator :累积缓冲器
networkClient :包装的网络层
sender :网络 I/O 线程
发送流程
发送一条消息的时候,数据又是怎样在这些组件之间进行流转的呢?
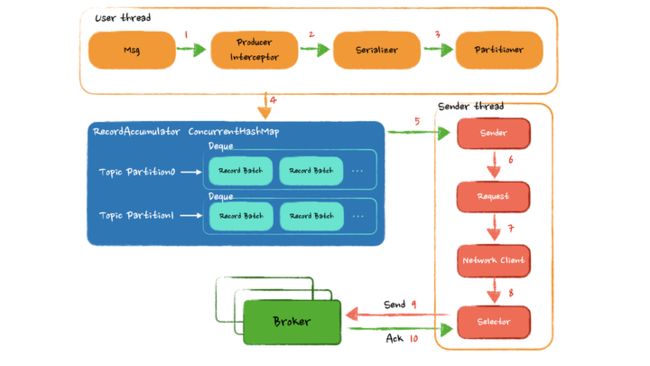
Producer调用 send 方法后,在从 Broker 获取的 Metadata 有效情况下,经过拦截器和序列化后,被分区器放到了一个缓冲区的特定位置,缓冲区由一个 ConcurrentHashMap 构成,key 为主题分区,value 是一个 deque 存放消息缓存块。从客户端角度来看如果无需关心发送结果,发送流程就已经结束了。
接下来是独立的Sender线程负责从缓冲中获取足量的数据调用 Network Client 封装层去真正发送数据,这里使用了 Java8 的 NIO 网络模型发送数据。
可以看到整个逻辑的关键点在于 RecordAccumulator 如何进行消息缓存,一般的成熟框架和中间件中都会有一套自己的内存管理机制,比如 Netty 也有一套复杂而又精妙的内存管理抽象层,这里的缓冲区也是一样的道理,主要需要去看看 Kafka 如何去做内存管理。
另外需要关注 Sender 从缓冲里以什么样的逻辑获取数据,来达到尽量少的网络交互发送尽量多的数据。还有网络失败又是如何保证数据的可靠性的。这个地方也是我们的设计和官方实现的差距,对于网络 I/O 的精心优化。
目前的篇幅已经比较长了,为了大家方便阅读理解,本篇主要从和大家一起思考如何设计一个 Kafka Producer 以及官方是如何实现的,我们之间的差距是什么,更需要关注的点是什么。通过自己的思考和对比更加能认识到不足学习到新的点!
最后
毕竟工作也这么久了 ,除了途虎一轮,也七七八八面试了不少大厂,像阿里、饿了么、美团、滴滴这些面试过程就不一一写在这篇文章上了。我会整理一份详细的面试过程及大家想知道的一些问题细节
美团面试经验
字节面试经验
菜鸟面试经验
蚂蚁金服面试经验
唯品会面试经验
因篇幅有限,图文无法详细发出,感兴趣的朋友可以点击这里前往我的腾讯文档免费获取上述资料!
g-Xz6mY6Ei-1615810650813)]
因篇幅有限,图文无法详细发出,感兴趣的朋友可以点击这里前往我的腾讯文档免费获取上述资料!