Spark - BloomFilter 推导与工业界应用
1.引言
上一篇文章 BitMap 的增删改查 介绍了如何使用 Bit 存储大规模数据以及对数据进行遍历和去重。常规数量的元素去重可以使用 HashSet ,但是受内存原因影响 HashSet 不方便对大批量数据去重,BitMap 的一个重要应用就是 BloomFilter-布隆过滤器,BitMap 上一篇文章已经解释了其如何对空间进行压缩,本文主要就 BloomFilter 的原理推到和工业界的应用进行分析。
二.原理推导
1.布隆过滤器简介
布隆过滤器可以理解为一个长的 bit 数组和 k 个映射函数组成,每个元素经过 k 个函数 Hash 得到 K个索引,bit 数组将对应 K 个索引的元素置为1,当判断一个元素是否存在时,只需判断其对应的 K 个 Hash 索引是否均为1。由于映射函数的随机性,布隆过滤器可能存在一定概率误判,即一定概率判断一个元素存在,100%概率判断一个元素不存在。
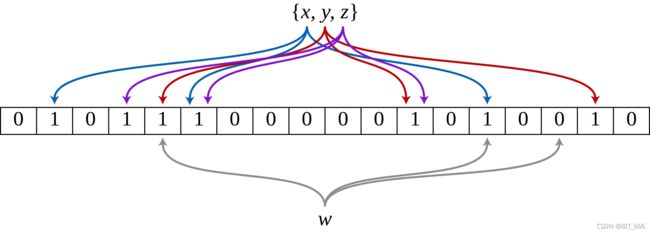
根据上述描述,布隆概率器的性能或者误判率 p 主要有由下几个参数决定:
> 待插入元素个数 : n
待插入元素 n 需根据本身使用场景决定,BloomFIlter 主要应用于大规模去重场景,例如对单一 id 进行去重,则 n 设置为比该 id 全部数量数值大的数字即可,如果对多 id 进行去重,可以将 n 设置为 id1 x id2 ... x idm 的总可能数,这个参数比较好确定。
-> bit 数组大小 : m
bit 数组长度过短,很快所有位置会被映射函数映射为1,失去去重的作用;bit 数组长度过长,可以一定程度的去重效果,但是空间占用也会随之加大
-> 映射函数: k
映射函数一般为 Hash 函数,对去重元素进行 Hash 得到多个值,映射函数较少,被误判的概率就越高,例如只有一个映射函数,则所有映射为相同值的数都会被误判,太多的话会造成空间浪费,快速填充满 bit 数组,失去去重效果
2.误判概率 p 推导
令待插入元素 = n 、bit 数组大小 = m 、映射函数数量 = k
一次函数映射某个索引被置为 1 的概率 : ![]()
一次函数映射某个索引被置为 0 的概率: ![]()
一次插入k个函数映射某个索引未被置为1的概率 : ![]()
n 次插入,共nk次映射某个索引未被置为1的概率 : ![]()
n 次插入,共nk次映射某个索引被置为1的概率为: ![]()
判断一个元素存在需要 k 个索引均为1,所以判定存在的概率为: ![]()
由于 ![]() ,令
,令 ![]() 得到判定概率的近似:
得到判定概率的近似:
![]()
由于 ![]() 为增函数,所以
为增函数,所以 ![]() 为减函数,所以
为减函数,所以 ![]() 为增函数,k有大于0,所以 p = f(k) 为增函数,其中
为增函数,k有大于0,所以 p = f(k) 为增函数,其中 ![]()
A. 可以看到当 n 增大时即插入元素增多时,x增大导致分母增大,f(k) 即误判概率增大
B. m 增大时即 bit 数组长度增加时, x减小导致分母减小,f(k) 即误判概率减小
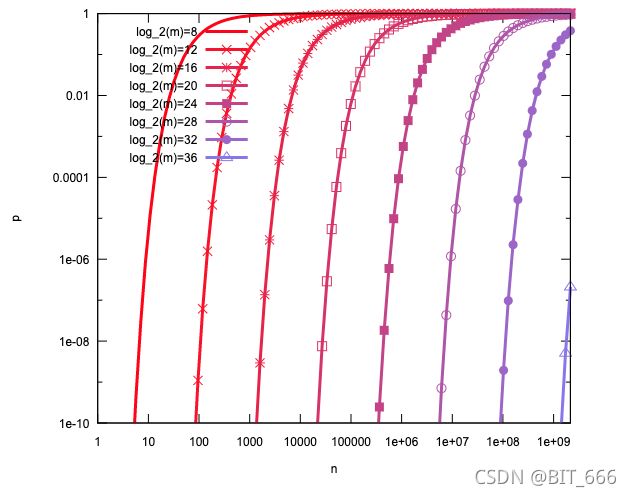
3.最优映射函数 k 推导
已知误判概率函数近似满足:![]() ,其中 k > 0
,其中 k > 0
这里忽略 ![]() ,近似看下
,近似看下 ![]() 的函数图像:
的函数图像:
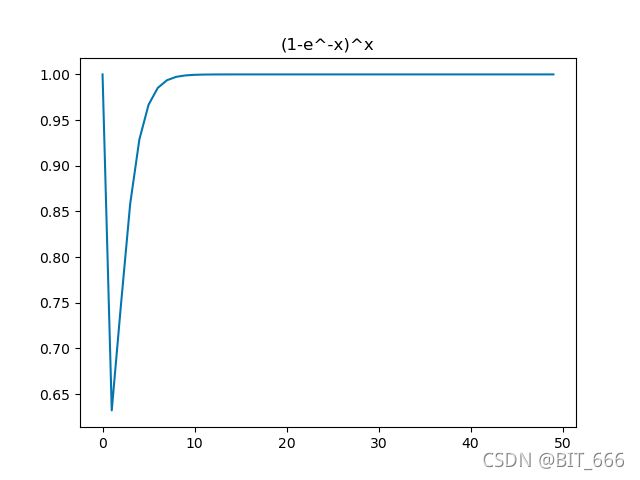
可以看到函数在 0 - 正无穷的单调性是先递减再递增,所以函数在对应区间内存在最小值且在最小值处函数一阶导数为0,关于单调性的证明有兴趣同学也可以求导实现,这里为了直观采用图示。
![]()
令 ![]() 则 f(k) 化简为
则 f(k) 化简为 ![]()
由于是对数函数,为了求极值需要用到极大似然估计,这里对简化后的函数两边求对数得到 :
![]()
两边同时求导 :
![]()
函数先减后增,极小值点 ![]() 满足:
满足:
![]()
所有在极值点满足:
![]()
移项得:
![]()
由于:
![]()
带入移项的式子得:
![]()
得到:
![]()
又:
![]()
最终得到,即误判概率达到最小值时 k 的值满足下述公式,其中 m,n 已知:
![]()
此时误判概率为:
![]()
4. bit 数组长度 m 计算
创建 BloomFilter 时一般需要提供两个参数,待插入的元素个数 n 和容忍度【误判率】p, 由上面可知误判达到最小时满足:
![]()
两边移项得:
![]()
整体思路就是先确定样本数 n,误判率 p 从而确定数组长度 m,再根据前者确定映射函数 k 的大小
三.工业场景应用
工业场景下 BloomFilter 主要应用与大规模数据的去重,例如用户的浏览记录去重判断
1.静态去重
静态去重多用于历史长期数据的过滤,针对每个用户的历史浏览记录构建一个 BloomFilter,然后对用户新的推荐内容进行去重,这里 BloomFilter 使用 org.spark_project.guava.hash.BloomFilter 实现。
A.根据插入数据n,误判率 p 初始化 BloomFilter
// 构建 BloomFilter
def getBloomFilter(insertNum: Int, fpp: Double): BloomFilter[java.lang.Long] = {
val bf = BloomFilter.create(Funnels.longFunnel(), insertNum, fpp)
bf
}B.获取用户浏览记录
这里采用 random 随机模拟用户浏览记录,userNum 代表模拟的用户数,recordNum 模拟每个用户浏览的数量
// 构造随机数据
def genRandomData(userNum: Int, recordNum: Int, seed: Int = 666): Array[(String, Array[Long])] = {
random.setSeed(seed)
val browserHistory = new ArrayBuffer[(String, Array[Long])]()
(0 until userNum).foreach(user => {
val records = (0 until recordNum).map(_ => random.nextLong()).toArray
browserHistory.append((user.toString, records))
})
browserHistory.toArray
}C.添加浏览记录并存储 BloomFilter
每个用户调用 getBloomFilter 函数生成 bf 并将浏览记录 records 存储进 bf,最后调用 saveAsObject 方法将结果存储为 (user, bf) 的 pairRdd
val sc = spark.sparkContext
val inputRdd = sc.parallelize(genRandomData(100, 200))
// 构造 BloomFilter
inputRdd.map { case (user, records) => {
val bf = getBloomFilter(10000, 0.001)
records.foreach(record => {
bf.put(record)
})
(user, bf)
}
}.saveAsObjectFile(output)saveAsObject 会将数据序列化存储,所以存储结果不可视化:

D.加载 BloomFilter 并去重
使用 objectFile 反序列化上一步存储的 BloomFilter,对于给用户的新的推荐内容进行过滤,由于存在一定误判几率,所以 bf 的判断方法为 mightContain
// 读取 BloomFilter
val sendResults: RDD[(String, Array[String])] = sc.emptyRDD
val realSendResults = sc.objectFile[(String, BloomFilter[java.lang.Long])](output).leftOuterJoin(sendResults).map(info => {
val user = info._1
val bf = info._2._1
val sendResults = info._2._2.getOrElse(Array.empty[String])
val realSend = sendResults.filter(re => !bf.mightContain(re.toLong))
(user, realSend)
})
realSendResults.saveAsTextFile(output)
}2.动态去重
静态去重适合于实时性要求不高的场景,对于一些时效性要求高的场景,可以使用动态 BloomFilter,其底层一般基于数据库实现,常用的为 Redis
A. bit 数组 n
通过 setbit(key, offset, value) 方法在长数组中放置对应元素与值
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}B. hash 函数 k
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}C. 去重
通过 k 个 hash 函数得到 K 个索引,通过 redis.getbit 方法获取对应位置的状态值,如果均为1则存在,否则不存在
四.总结
BloomFilter 布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。