《Day13》熬夜整理的MySQL的高级编程【完整版】
一、Mysql的高级编程
(一)msyql的自带函数
函数就是将一系列的sql处理提前封装在数据库中,调用函数就是执行对应的sql程序,通过函数达到降低语句的重复。
1、字符串函数
| 介绍 | 应用 | 拓展 |
|---|---|---|
| 1、-- CONCAT(str1,str2,…) 可以拼接多个字符串 在oracle数据库中 concat只能拼接两个字符串 | SELECT CONCAT(“aa”,“bb”,“cc”,“dd”) -->aabbccdd | |
| 2、-- INSERT(str,m,n,str1) str 原字符串 m 序号 n 个数 str1 替换的字符串 | SELECT INSERT(“abcdefg”,3,4,"") -->abg | |
| 3、-- LOWER(str) 将字符串转化为小写 | SELECT LOWER(“aBcdEFGh”) -->abcdefgh | |
| 4、-- UPPER(str) 将字符串转化为大写 | SELECT UPPER(“aBcdEFGh”) -->ABCDEFGH | |
| 5、-- LEFT(str,len) 从左边截取对应长度的字符串 | SELECT LEFT(“abcdef”,3) -->abc | |
| 6、-- RIGHT(str,len) 从右边截取对应长度的字符串 | SELECT RIGHT(“abcdef”,3) -->def | |
| 7、-- LPAD(str,len,padstr) 将一个字符串转化为固定长度的字符串 补位的位置左边 | SELECT LPAD(“abcdef”,8,"*") -->**abcdef | SELECT LPAD(“abcdef”,4,"*") -->abcd |
| 8、-- RPAD(str,len,padstr) 将一个字符串转化为固定长度的字符串 补位的位置右边 | SELECT RPAD(“abcdef”,8,"*") -->abcdef** | SELECT RPAD(“abcdef”,4,"*") -->abcd |
| 9-- trim(str) 去掉最前面 和最后面的空格 | SELECT trim(" ab cd ef ") -->ab cd ef | |
| 10、-- LTRIM(str) 去掉前面的空格 | ||
| 11、-- RTRIM(str) 去掉后面的空格 | ||
| 12、-- INSTR(str,substr) str 待查找的字符串 substr 要查找的字符串 | SELECT INSTR(“abcdefcdedfcdef”,“cd”) -->3 | – SELECT * FROM person where name like “%保%” – SELECT * FROM person where INSTR(name,“保”) > 0 |
| 13、-- REVERSE(str) 将字符串位置倒序 | SELECT REVERSE(“abcdefcdedfcdef”) -->fedcfdedcfedcba | |
| 14、 – SUBSTR(str,m,n) 截取字符串 从序号m开始 截取n个 | SELECT SUBSTR(“abcdef”,4,2) -->de | SELECT SUBSTR(“abcdef”,4) -->def |
| 15、 REPEAT(str,count) 将字符串重复conut次 | SELECT REPEAT(“abc”,5) | |
| 16、REPLACE(str,from_str,to_str) 将str字符串中的from_str 替换为to_str | SELECT REPLACE(“EFCDEFCDEFCEFcd”,“CD”,"") -->EFEF*EFCEFcd |
2、数字函数
| 介绍 | 应用 | 拓展 |
|---|---|---|
| – CEIL(X) 向上取整 | SELECT CEIL(33.000000001) -->34 | |
| – FLOOR(X) 向下取整 | SELECT FLOOR(33.999999) -->33 | |
| – ROUND(X) 四舍五入 | SELECT ROUND(33.45) -->33 | |
| – ROUND(X,m) m 小数点的位数 | SELECT ROUND(33.45,1) -->33.5 | SELECT ROUND(33.45,-2) -->30 |
| – MOD(N,M) 求模 | SELECT MOD(10,3) -->1 | |
| – POW(X,Y) 次幂 | SELECT POW(2,3) -->8 | |
| – RAND() 从0 到1 之间取一个小数 | SELECT RAND() -->0.9758970970063443 | SELECT CEIL(RAND() * 100) -->41 |
3、时间函数
| 介绍 | 应用 | 拓展 |
|---|---|---|
| – NOW() 获取当前时间 | SELECT NOW() -->2021-01-07 10:03:14 | |
| – CURDATE() 获取当前时间的年月日 | SELECT CURDATE() -->2021-01-07 | |
| – CURTIME() 获取当前时间的时分秒 | SELECT CURTIME() -->10:04:49 | |
| – UNIX_TIMESTAMP() 获取时间戳 1970到现在的毫秒 | SELECT UNIX_TIMESTAMP() -->1609985174 | SELECT UNIX_TIMESTAMP(“19971011”) -->876499200 |
| – FROM_UNIXTIME(时间戳) 将时间戳转化为时间 | SELECT MOD(10,3) -->1 | |
| SELECT FROM_UNIXTIME(1609999174) -->2021-01-07 10:06:14 | SELECT FROM_UNIXTIME(876499200) -->1997-10-11 00:00:00 | |
| – DATE_FORMAT(date,format) 按照format的格式将时间格式化-- 格式化写法 %y 两位数的年 %Y四位数的年 %m 月 %d 日 %H 24小时制 %h 12小时制 %i 分钟 %s 秒 | SELECT DATE_FORMAT(FROM_UNIXTIME(1609999174),"%Y-%m-%d %H:%i:%s") -->2021-01-07 13:59:34 | SELECT DATE_FORMAT(FROM_UNIXTIME(1609999174),"%y-%m-%d %h:%i:%s") -->21-01-07 01:59:34 |
附DATE_FORMAT(date,format)
– DATE_FORMAT(date,format) 按照format的格式将时间格式化
– 格式化写法 %y 两位数的年 %Y四位数的年
– %m 月 %d 日 %H 24小时制 %h 12小时制 %i 分钟 %s 秒SELECT DATE_FORMAT(FROM_UNIXTIME(1609999174),"%Y-%m-%d %H:%i:%s")
–>2021-01-07 13:59:34SELECT DATE_FORMAT(FROM_UNIXTIME(1609999174),"%y-%m-%d %h:%i:%s")
–>21-01-07 01:59:34
4、流程控制函数
1.-- IF(expr1,expr2,expr3) 根据第一个个参数作为条件判断 如果结果是true 返回第二个参数 如果是false返回第三个
SELECT IF(1=1,“正确”,“错误”) -->正确
SELECT IF(1>0,“正确”,“错误”) -->正确2.-- 判断空 分为在select 后面 的 和where后面的
– 在where后面 使用 is null 或者 is not null
– 在select后面 使用 ifnull(column,defult) --判断 column是否为空 如果是空返回defult ,如果不是返回本身SELECT * FROM person where hobby IS NOT NULL
SELECT name , (sal + bonus) * 12 ‘年薪’ FROM person
SELECT name , (sal + IFNULL(bonus,0)) * 12 ‘年薪’ FROM person3.-- CASE WHEN THEN ELSE END 类似于if else 判断,是一套判断组合
SELECT
CASE
WHEN 9 = 10 THEN “这是9”
WHEN 10 = 11 THEN “这是10”
ELSE “不是9也不是10”
ENDSELECT name , age ,
CASE
WHEN age > 10 and age < 50 THEN “青年”
WHEN age >= 50 and age < 70 THEN “老年”
ELSE “未划分”
END
FROM person
5、其他函数
| 介绍 | 应用 |
|---|---|
| – 返回当前数据库名称 | SELECT DATABASE() -->mybatis |
| – 查看当前数据库版本 | SELECT VERSION() -->5.5.49 |
| – 查看当前操作的用户 | SELECT USER() -->root@localhost |
– md5 加密 一种加密算法 将任意长度的字符串加密为32位长度的字符串
– md5 算法不支持解密
SELECT MD5(“e80b5017098950fc58aad83c8c14978eABCD啊s大声地啊大蛇大蛇的撒的撒大蛇的傻傻的啥 大的”) --》a071af21a9d0777821080d84f8ac1c3e
(二)自定义函数
在使用mysql函数的过程中,如果感觉mysql自带的函数不够用或者不符合需求,可以自己定义函数,在mysql数据库中 函数是绑定到数据库的,函数创建后只能在当前的数据库使用,不能跨数据库。

1、语法结构
– 语法结构
– CREATE FUNCTION 函数名称
– ([参数列表] 参数名称 参数类型 …)
– RETURNS 数据类型
– BEGIN
– DECLARE 名称 类型 --自定义局部变量
– 流程语句、sql语句… --自定义函数的内容
– RETURN 返回值;
– END
使用黑窗口命令

修改结束符
2、创建一个没有入参的自定义函数

– 删除自定义函数
DROP FUNCTION fun01

3、创建一个有参数并且有sql语句的自定义函数
–创建一个有参数并且有sql语句的自定义函数
– 入参是person的id 返回id对应数据的name
– into 关键字 在自定义函数中将查询的结果赋值变量
– DECLARE 定义局部变量
– 在自定义函数中 局部变量声明后面 SQL语句的后面 返回值的后面必须要加;
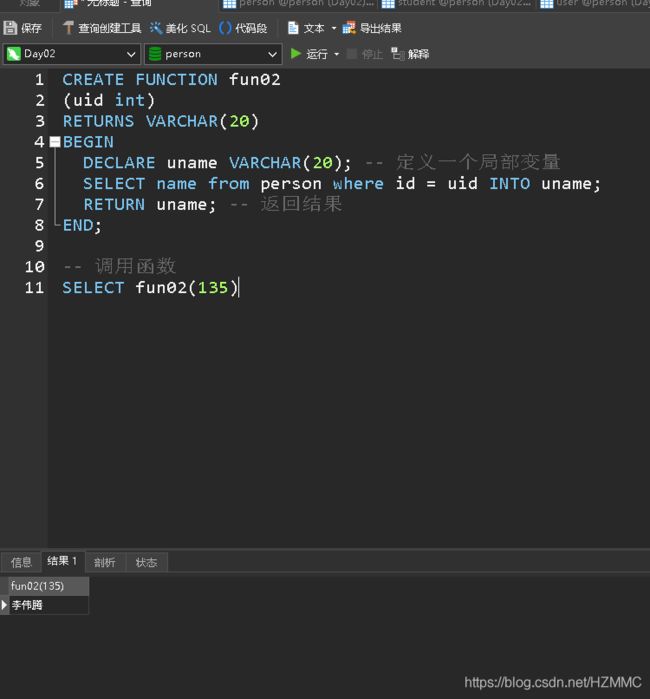
注意: 在oracle数据库中 自定义函数中不能写sql。
在oracle数据库中 字符串只能使用 ‘’ 来表示
4、使用if判断实现自定义函数
– 根据工资数据 计算工资级别的自定义函数
– 入参就是工资 doubler 返回值 字符串
– 在自定义函数中需要添加判断
– 变量赋值 SET 变量 = 值

如果在oracle中 变量赋值使用 :=
(三)mysql的触发器
trigger 触发器 在mysql数据库中根据特定的条件触发的执行动作。
根据增删改语句触发对应的操作。
触发器是在数据库表中绑定的,在触发器执行期间不会造成任何的操作的任何影响。可以使用触发器记录数据,不能用触发器来操作被绑定触发器的表。
可以执行除了当前数据库表任意的sql语句。
1、触发器的语法
create trigger 名称
[after|before] – 设置转发器执行的瞬间 是在触发语句的前面还是后面
[insert|delete|update] --设置触发器的触发规则
on 表名 --绑定那个数据库表
for each row --固定写法 sql语句中 每行数据都触发
begin
触发的sql
end
2、创建一个Person表添加的触发器
(1)创建一个数据库表,用来记录触发器sql的
CREATE TABLE
log(
idint(11) NOT NULL AUTO_INCREMENT,
user_namevarchar(255) DEFAULT NULL,
messagevarchar(255) DEFAULT NULL,
timedatetime DEFAULT NULL,
remarkvarchar(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(2)创建一个person添加的触发器
– 创建一个person添加的触发器 记录数据
– 在触发器中 有两个关键字 可以使用 new 新增的一行数据 old 原始的一行数据

3、创建一个user表修改的触发器

(四)mysql的视图
1、视图的概念
视图就是一个虚拟的表,是数据库中根据查询语句一个或者多个数据库表查询的结果,表的内容就是查询语句得到的结果。视图中数据和真正的数据是关联的,相当于将查询写好后放在数据库中,将结果转化为一张表,这个表就是视图。视图和真正的表结构是一样的,有行和列对应的数据。在底层还是有区别的,视图是依赖真正的表存在。视图只在数据库中存放了视图的定义,没有真正的数据。
2、视图的作用
(1)简单性
看到的就是需要的,视图不仅可以简化用户对数据库的了解,也可以简化操作,我们可以将一些常用的查询封装为视图。在下次使用的时候直接调用视图就可以。通过简单的sql实现复杂的查询。
(2)安全性
视图是有权限的,可以防止未授权的用户查看特点的内容,通过授权保证数据库的安全。
3、视图创建的语法
CREATE [OR REPLACE] VIEW 视图名称
AS 查询语句
如果要创建和使用视图,必须要有对应的权限,权限默认是关闭的。
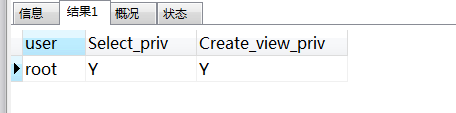
查看权限是否开启:
SELECT user,Select_priv,Create_view_priv from user where user = “root”
查看结果,如果是Y 表示开启:
如果没有开启使用update语句修改:
update user set Select_priv = “Y”,Create_view_priv = “Y” where user = “root”
4、创建视图案例
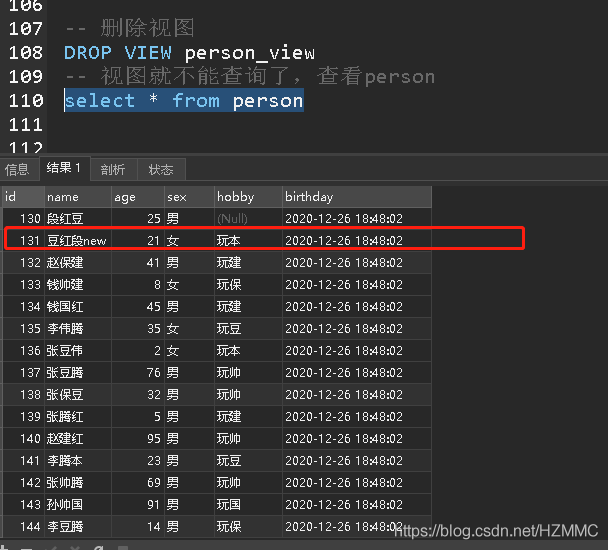
(1)创建一个简单的视图
列的数据和表中数据完全一样,如果视图中的数据和表的完全一样,就可以修改视图数据达到修改表的目的。


(2)创建一个有运算的视图
– 创建一个有运算的视图
CREATE VIEW person_view1
AS
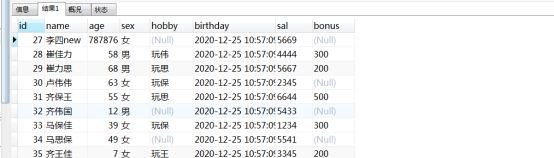
SELECT name,age,sex,hobby,sal*12 sumsal from person
– 查询视图
SELECT * from person_view1
– 修改视图
UPDATE person_view1 set sumsal = 787876 where name = “李四new”

(五)mysql的存储过程
存储过程就是按照特定的语法,创建特定的sql语句的一个程序,由数据库进行编译和执行,程序员可以重复调用的程序。
1、存储过程的优缺点
(1)优点
①存储过程是直接存放在数据库中的,调用的时候不需要编译,执行效率高
②一个存储过程可以被重复调用
③一个存储过程中可以有多条sql或者查询多个表,在使用的时候一个存储过程连接数据库一次。
④存储过程是安全的,数据库管理员可以向访问数据库存储过程的人员进行授权,可以授权访问存储过程而不授权访问存储过程查询对应的表。
(2)缺点
①可移植性太差,如果要更换数据,很麻烦
②如果在存储过程中写一些简单的sql,没有太大的意义。
③如果存储过程中有太复杂的业务逻辑,对应存储过程也很吃力。
④对于只有一类用户的数据库,安全性没有太大的意义。
⑤如果在日常开发中,规则没有定义的太好,维护起来非常麻烦。
⑥对于开发和调试都不太方便
2、存储过程的语法
CREATE PROCEDURE 存储过程名称
([参数列表] in 名称 类型 … out 名称 类型 …)
BEGIN
存储过程的内容;
END
procedure 程序、过程
3、存储过程案例
(1)简单的存储过程–没有入参没有出参
– 最简单的存储过程 查询person表
CREATE PROCEDURE peroc01()
BEGIN
SELECT * FROM person;
END
– 调用存储过程
CALL peroc01()
(2)带有入参的存储过程-- 有入参的存储过程 根据传入的性别 查询对应的平均工资
CREATE PROCEDURE proc02
(in psex VARCHAR(2))
BEGIN
SELECT sex,avg(sal+IFNULL(bonus,0)) FROM person GROUP BY sex HAVING sex = psex;
END
– 调用存储过程
CALL proc02(“女”)

– 删除存储过程
DROP PROCEDURE proc02
(3)带返回值的存储过程
mysql中变量:
三种变量:
①局部变量 在局部生效 一般来说在 begin 和end中间
②会话变量 当前连接数据库生效的一个变量
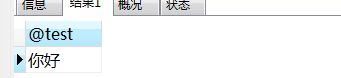
使用 @变量名 来使用
– 会话变量赋值
SET @test = “你好”
– 查询会话变量
SELECT @test
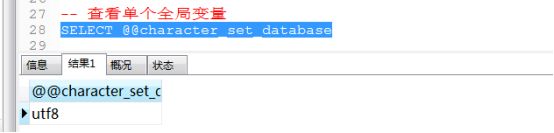
③全局变量 使用@@变量名 来使用
全局变量 我们最好是不要用 一般全局变量都是用来设置mysql的

– 创建一个带有入参和出参的存储过程
– 根据perosn表id 查询对应的name并返回
CREATE PROCEDURE proc03
(in pid int , out pname VARCHAR(10))
BEGIN
SELECT name into pname from person where id = pid;
END
– 调用
call proc03(31,@name)
– 查看变量
SELECT @name
结果;

(4)入参和出参是同一个类型

结果:

二、mysql的索引
1、索引的概述
数据的索引是一种特殊的文件(innoDB引擎中,数据库表中索引就是表的一部分),索引中包含了数据库表引用的指针,索引就类似于重点的目录,作用提高查询的效率。我们如果在没有索引的情况下查询二百万条数据的时候,如果不使用索引可能用时会大于一分钟,使用索引后用时可以减少到秒内。如果不使用索引查询数据,在查询的过程中将所有的数据都搜索一次。索引就是将特定的列单独生成一个文件,查询的时候查询索引。索引数据查询到以后会指向对应的数据。
我们使用索引的时候 ,会降低增删改的速度。
所以如果数据库表的数据增删改使用概率不低的情况下,也不推荐使用索引。
在mysql中索引分为聚簇索引和非聚簇索引:
聚簇索引就是安装物理存放数据的位置类排序的, 非聚簇索引安装数据库表顺序来排序。
聚簇索引会提升多行简述的效率,非聚簇的会提升单行简述的效率。
2、索引的分类
(1)普通索引
普通索引是数据库最常见的索引,没有任何的限制,一般创建索引都使用普通索引,特殊的情况下才考虑其他的索引。
索引创建的方法:
①直接添加索引
– 直接添加索引
CREATE INDEX per_id ON person(id)
②创建表的时候同时添加索引
CREATE TABLE t1(
id int PRIMARY KEY auto_increment,
title varchar(20),
time date,
index t1_index (title)
③通过修改表的列来添加索引
– 通过修改表的列
ALTER TABLE user ADD INDEX user_index (sex)
(2)唯一索引
和普通索引的区别就是 索引中数据是唯一的。
①直接添加索引
– 直接添加索引
CREATE unique INDEX per_id ON person(id)
②创建表的时候同时添加索引
CREATE TABLE t1
( id int PRIMARY KEY auto_increment,
title varchar(20),
time date,
unique index t1_index (title) )
③通过修改表的列来添加索引
– 通过修改表的列
ALTER TABLE user ADD unique INDEX user_index (sex)
(3)复合索引
如果在创建索引的过程中,发现数据库表多行在查询中经常会被使用,将多列创建为一个复合索引,如果我们创建了一个单行的普通索引,在查询语句中查询了多列,索引无效、
①直接添加索引
– 直接添加索引
CREATE INDEX per_id ON person(id,nmae)
②创建表的时候同时添加索引
CREATE TABLE t1(
id int PRIMARY KEY auto_increment,
title varchar(20),
time date,
index t1_index (title,time)
)
③通过修改表的列来添加索引
– 通过修改表的列
ALTER TABLE user ADD INDEX user_index (sex,age)
3、索引使用的注意事项
索引使用的目的就是提高查询的效率,但是索引也不能滥用,要根据具体情况来添加。
创建索引相当于将当前的列重新创建一个存储空间。在数据库增删改的时候也要修改索引,创建的时候不要创建太多的索引。
在使用的时候也要注意:
(1)索引在使用的时候不要使用null
如果有NULL 索引无效。
(2)使用索引的时候尽量使用短索引
在创建表的时候,习惯将设置的长度设置的比较长,但是在使用的过程中如果没有用到太长,在设置索引的时候是根据设置创建的。(3)在使用索引的时候要注意排序
我们如果使用索引 name查询,在排序的时候使用id排序,结果 索引无效。
不使用索引内排序 可以使用子查询
(4)like关键字
在使用索引的时候不能使用like
(5)不要在索引列上进行运算
比如perosn表 sal设置了索引 如果在查询的时候 sal*12 计算年薪 索引无效