Siam-RCNN VIsual Tracking by Re-Detection
Abctract
根据目前的siam-cnn,孪生再检测的结构,释放了视觉目标跟踪的两阶段目标检测方法的全部力量。我们结合一种新的基于轨迹的动态规划算法,该算法利用第一帧模板和前帧预测的重新检测,来模拟被跟踪对象和潜在干扰对象的完整历史。这使得我们的方法能够做出更好的跟踪决策,以及在长时间遮挡后重新检测被跟踪的对象。最后,我们提出了一种新的硬实例挖掘策略来提高Siam R-CNN对相似外观对象的鲁棒性。Siam R-CNN在10个跟踪基准上取得了目前最好的性能,特别是对于长期跟踪的非常棒的效果。
www.vision.rwth-aachen.de/page/siamrcnn.
1、Introduction
R-CNN和Siame结构重新检测一个模板对象在图像的任何地方,通过确定一个区域推荐是相同的对象作为一个模板区域,并回归该对象的边界框。Siam R-CNN对物体大小和高宽比的变化是稳健的,因为建议是对齐到相同的大小,这是对比流行的基于相关操作的方法。
遮挡物
在线适应
都出线漂移的情况。
主要针对干扰物的问题,首先介绍了一种新的hard样本挖掘的方法,主要针对复杂干扰物对重新检测器进行训练。其次提出了一种动态算法TDPA,可同时跟踪潜在的对象,包含干扰物对象,通过重新检测前一帧中的候选对象并随着时间的推移将候选对象组成(短目标跟踪),根据所有目标对象和干扰对象轨迹的完整历史,使用动态规划来选择当前时间步长的最佳对象。
(本文基于的范式是利用重检测进行视频目标追踪。前期利用重检测进行视觉目标追踪的方法通常会受到相似干扰物的影响,其解决策略主要是利用先前的预测提供强位置先验信息和模型在线更新,但是这两种方法都避免不了模型的漂移问题。本文的工作主要有:(1)提出一种新的Siam R-CNN追踪器,利用孪生结构将Faster R-CNN应用于解决视觉目标追踪问题;(2)提出一种新的难例挖掘方法,能有效缓解干扰物对追踪结果的影响;(3)提出一种基于Tracklets的动态规划算法,能够在遮挡、目标消失等挑战中实现有效追踪。Siam R-CNN在六个短期追踪基准和四个长期追踪基准中均优于先前提出的方法。另外,利用现有的box-to-segmentation部件能够利用追踪框实现视频目标分割,在四个常见追踪数据集上比仅使用初始框标注进行分割的其他方法性能都好。
Siam R-CNN通过对所有潜在对象的运动和交互进行建模,将检测到的归为tracklet的相似度信息汇集到一起,能够有效地进行长期跟踪,同时抵抗跟踪器漂移,并且能够在消失后立即重新检测到目标。我们的TDPA只需要在每个时间步中进行一组新的重新检测,在线迭代更新跟踪历史。使得R-CNN可以以每秒4.7帧的速度运行。超过15FPS。
优于只利用第一帧的视频跟踪分割方法。

2、相关工作
VOT和OTB基准集评估。Siam R-CNN通过离线训练而不是在线学习分类器来学习预期的外观变化。对比了RPN检测器将深层模版特征与当前帧深度互相关操作重新检测模版,单步意味着直接分类锚框,和两段分类形成对比,再对第二阶段进行特征排列进行分类。
最近的跟踪方法改进了SiamRPN,使其可以感知干扰(DaSiamRPN[117]),增加了级联(C-RPN[25]),产生掩码(SiamMask[93]),使用更深的架构(SiamRPN+[113]和SiamRPN++[48]),并维护了一组不同的模板(THOR[77])。这些(以及更多[7,35,62])只在先前预测的一个小窗口内搜索该物体。DiMP[5]遵循这一范式,元学习则是一个健壮的目标和背景外观模型。
VOT的其他近期发展包括使用与在线学习相关的领域特定层[66],学习自适应空间滤波器正则化器[17],利用分类特定语义信息[84],使用连续[20]或分解[18]卷积,以及使用重叠预测网络[19]实现准确的边界盒预测。siam-rcnn采用两段结构,但是依赖于元学习的话精度低的多。长期跟踪主要通过在检测置信度较低时增加孪生网络跟踪器的搜索窗口来解决,这样可以有更好的表现。
3、method
使用孪生网络作为重新预测器,之前的检测器均采用单级检测器结构,对于单目标的检测任务,两级检测网络更好。其中第二阶段主要将感兴趣的ROI与模版区域进行比较,将感兴趣的区域特征连接起来,与参考图像进行对比,实现了对物体大小和长宽比变化的鲁棒性,这一点,使用简单的互相关操作是很难实现的。
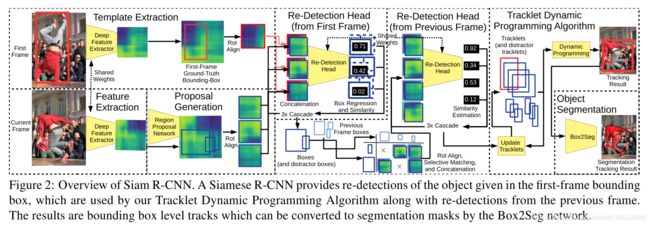
图2显示了包括Tracklet动态规划算法(TDPA)的Siam R-CNN的概述。
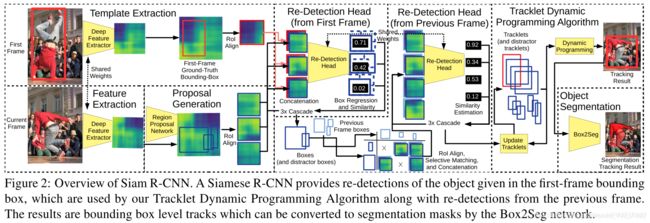
3.1、Siam-rcnn
是一个孪生网络检测器基于两段的检测结构,使用COCO数据集预先训练更快的R-CNN结构检测80个对象类别,该网络是一个主干网络特征提取器和两个检测阶段组成的。首先是一个RPN其次是 一个特定类别的检测head,固定主干和rpn的权重,再使用本文的重新检测head代替了特定分类的检测
将第一帧中初始化边界框的RoI对齐深度特征拼接在一起,将合并后的特征进行1×1卷积,使特征通道减少一半。这些连接的特征然后输入到有两个输出类的再检测头;建议的区域要么是引用对象,要么不是。我们的重探测头使用三级级联[9],没有共享权重。该重检测头的结构与更快的R-CNN的检测头的结构相同,只是只使用了两个类,以及重检测头的输入特征是通过拼接的方式创建的。骨干和RPN被冻结,只有重新检测头(连接后)被训练用于跟踪,使用视频数据集的帧对。这里使用一帧中的一个对象作为参考,然后训练网络在另一帧中重新检测相同的对象。
3.2. Video Hard Example Mining
在常规的Faster R-CNN训练期间,从目标图像中RPN提议的区域中采样第二阶段的负训练样本。 但是,在许多图像中,只有很少的相关负样本。 为了最大程度地提高重检测头的判别能力,我们需要在严格的负样本上进行训练。 在以前的工作中已经探索了进行检测的难例挖掘(例如[26,79])。 但是,与寻找用于检测的通用难例挖掘方法不同,我们通过从其他视频中检索参考对象来构建困难训练样本。
Embedding Network
(这个Embedding Network网络其实就是一个特征提取网络,提取ground truth bbox图像区域的特征,用这个特征代表这块图像对象。因为提取的是代表特征,所以它应该具有同一对象的特征距离会很近,而不同对象的特征之间的距离会很远。) 为当前视频建构难例的一个直观方法是选择相关的视频,这些视频里有和当前目标相同的类别[118]。 但是,对象类别标签并不总是可用,并且同一类的某些对象可能易于区分,而不同类的某些对象也可能是难例。 因此,我们建议使用embedding network,它是受行人重识别启发的,该网络为该对象外观的每个地面真相边界框提取一个嵌入向量来代表这个对象。 我们使用来自PReMVOS [60]的网络,该网络使用batch-hard triplet loss[36],先在COCO的各个类别上进行训练,然后再在YouTube-VOS上进行训练以消除各个对象实例之间的歧义。 例如,在嵌入空间中,两个不同的对象应该相距较远,而不同帧中的同一对象之间距离应相近。
Index Structure.
为最近的区域创建一个高效的索引结构,并用它来查找嵌入空间中找到被跟踪对象的最近邻,下图显示了所检索的hard负样本示例,可以看出,大多负样本是相关且困难的。

Training Procedure
Embedding Network 和 Index Structure 都是为都是为了Training Procedure中提供更高效的训练难例提取而设计的。大致的思路就是,先提取每个真值追踪框的ROI aligned特征,然后在训练的过程中,由Index Structure生成选取的追踪对象的难例,完成训练。这里的难例与追踪对象是非常相似的,这种训练方法应该是可以提高网络对同类的不同实例的差别能力。)
从其他视频中在线评估主干网络来检索当前视频帧的难例是非常昂贵的。 取而代之的是,我们为训练数据的每个地面真实框预先计算了与RoI对齐的特征。 对于每个训练步骤,通常会选择一个随机视频和该视频中的对象,然后选择一个随机参考图像和一个随机目标帧。 然后,我们使用索引结构从其他视频中为参考框检索10,000个最近邻的边界框,并从其中采样100个作为难例。 可以在补充材料中找到有关视频难例挖掘的更多详细信息。
3.3 Tracklet Dynamic Programming Algorithm
我们的Tracklet动态规划算法(TDPA)使用时空线索隐式地跟踪感兴趣的对象和潜在的相似的干扰物。通过这种方式,干扰可以被持续地抑制,而这仅靠视觉相似性是不可能实现的。为此,TDPA维护了一组tracklet,即几乎可以肯定属于同一对象的短检测序列。然后使用基于动态编程的计分算法来选择第一个帧和当前帧之间模板对象最有可能的tracklets序列。每个检测都是一个轨迹的一部分,它是由边界框, 重检测得分和它的ROI对齐特征进行定义的。tracklet由一组检测定义,从开始到结束的每一个时间步对应一个检测。也就是说,一个tracklets不允许有时间间隔。

Tracklet Building.
我们提取第一帧地面真值边界框(ff gt textures)的RoI对齐特征,并初始化仅由该框组成的tracklet。对于每一个新帧,我们更新轨迹集如下(见算法1):提取当前帧的骨干特征,并对区域建议网络(RPN)进行评估,得到感兴趣的区域(RoIs,第2-3行)。为了补偿潜在的RPN假阴性(误报),利用前一帧输出的边界框扩展了roi集合即利用前一帧预测的边界框。我们运行重新检测头(包括边界框回归)在这些roi产生一组重检测第一帧模板(4)行。后来,我们重新分类的一部分re-detection头对当前检测detst(第6行),但这一次的检测detst−1从第一帧的前一帧为参考而不是地面真实框,计算每队检测之间的相似性得分。
为了测量两次检测的空间距离,两次检测的空间距离,在追踪中的含义就是,前一帧的追踪框bbox和当前帧的追踪框bbox之间的距离)们用其中心坐标 x 和 y 表示其边界框,并用宽度 w 和高度 h表示它们的宽度,其中 x 和 w 用图像宽度标准化,而 y 和 h用图像高度标准化,所有值都在0到1之间。然后,通过 L ∞ 范数给出两个边界框 ( x 1 , y 1 , w 1 , h 1 ) 和 (x2,y2,w2,h2)之间的空间距离,即 max ( ∣ x 1 − x 2 ∣ , ∣ y 1 − y 2 ∣ , ∣ w 1 − w 2 ∣ , ∣ h 1 − h 2 ∣ ) 为了节省计算量并避免错误匹配,我们仅针对空间距离小于γ的检测对计算成对相似度得分,否则将相似度得分设置为 − ∞ 。
当与新检测的相似性得分高( > α )并且没有歧义时,我们通过当前帧检测来扩展前一帧的tracklet(第7-20行)。例如没有其他检测具有与该tracklet相同强度的相似性(小于β),并且没有其他tracklet与该检测具有几乎相同的相似度(小于β)。 只要有任何歧义,我们都会启动一个新的tracklet,它最初包含一个检测。 然后在tracklet评分步骤中消除歧义。 (tracklet的扩张和新建的过程大致就是,当前帧中可以明确检测到追踪目标时,就把这个检测加入到tracklet中,如果当前帧的检测结果有可能不是待追踪目标,那么就新那一个tracklet。就是在启动新tracklet的过程中,会自动隐式地追踪到相似干扰物,但是通过动态规划求解,可以求解出待追踪目标的tracklet序列。)
(a是一个tracklet,tracklet是一个检测序列,A代表一个追踪,也是一个由tracklet组成的序列)
Scoring. 一个追踪 A = ( a 1 , . . . , a N )是由 N 个不重叠的tracklets组成的序列,例如end( a i )


为了在很长的序列中保持效率,我们允许两个tracklet之间的最大时间间隔为1500帧,这对于大多数应用来说足够长。
在当前帧中更新 θ之后,我们选择动态规划得分最高的tracklet a ^,即 a ^ = arg max a θ 。 如果选定的tracklet a ^ ,在当前帧中不包含一个检测,则我们的算法表明该对象不存在 (目标出视野或被完全遮挡) 。 对于需要在每个帧中进行预测的基准,我们使用所选tracklet的最新框,并将其分配为0。
3.4 Box2Seg
为了为VOS任务生成分割掩膜,我们使用了来自PReMVOS [60]的现成的边界框到分割(Box2Seg)网络。 Box2Seg是具有Xception-65 [16]主干的全卷积DeepLabV3 + [11]网络。 它已经在Mapillary [68]和COCO [56]上受过训练,可以为边界框输出掩膜。 Box2Seg速度很快,在跟踪之后运行它只需每帧每个对象0.025秒。 我们组合重叠的掩膜,以使像素较少的掩膜位于顶部。
3.5 Training Details
Siam R-CNN建立在Faster R-CNN [74]实现和[96]的预训练权重基础之上,具有ResNet-101-FPN主干[34,55],组归一化[97]和级联[9]。 它已经在COCO [56]上从零开始[32]进行了预训练。 除非另有说明,否则我们将同时在多个跟踪数据集的训练集上训练Siam R-CNN:ImageNet VID [75](4000个视频),YouTube-VOS 2018 [101](3471个视频),GOT-10k [38]( 9335个视频)和LaSOT [23](1120个视频)。 我们使用运动模糊和灰度数据增强[118]以及伽玛和比例数据增强进行训练。
4 Experiments
我们在标准视觉对象跟踪、长期跟踪以及VOS基准上评估Siam R-CNN。 我们为DAVIS 2017训练集上的Tracklet动态编程算法(参见第3.3节)调整了一组超参数,因为我们没有用它来训练重新检测器的训练集。 我们在所有基准上使用这些超参数来评估结果,而不是针对每个基准单独调整参数。
4.1. Short-Term Visual Object Tracking Evaluation
对于短期VOT,我们使用以下基准:OTB2015 [99],VOT2018 [45],UAV123 [65],TrackingNet [66]和GOT-10k [38]。 在补充材料中,我们还评估了VOT2015 [46],VOT2016 [44],TC128 [54],OTB2013 [98]和OTB50 [99]。
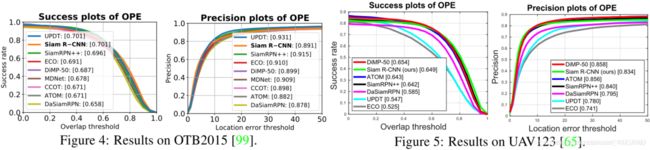
OTB2015. 我们评估OTB2015(100个视频,平均590帧的平均长度),计算重叠阈值变化时的成功率和精度。 方法通过成功曲线下的面积(AUC)进行排名。 图4将我们的结果与8个最先进的(SOTA)跟踪器进行了比较[6、48、18、5、67、20、19、118]。 Siam R-CNN达到了70.1%的AUC,这等于UPDT先前的最佳结果[6]。
UAV123. 图5显示了我们在UAV123 [65](123个视频,平均915帧的平均长度)上的结果,与六个SOTA方法[5、19、48、118、6、18]相比,其度量标准与OTB2015相同。 我们实现了64.9%的AUC,接近DiMP-50 [5]先前的最佳结果65.4%。
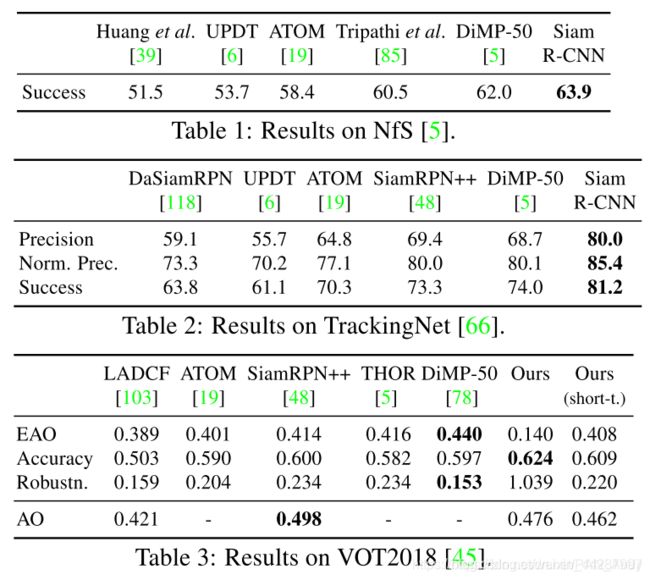
NfS表1显示了我们在NfS数据集上的结果[43](30FPS,100个视频,平均479帧),与5种SOTA方法相比。 Siam R-CNN的成功分数为63.9%,比DiMP-50先前的最佳成绩高1.9个百分点[5]。**
TrackingNet. 表2显示了我们在TrackingNet测试集上的结果[66](511个视频,平均长度442帧),与五种SOTA方法相比。 Siam R-CNN的成功分数为81.2%,比DiMP-50的先前最佳成绩高7.2个百分点[5]。 就精度而言,差距超过10个百分点。
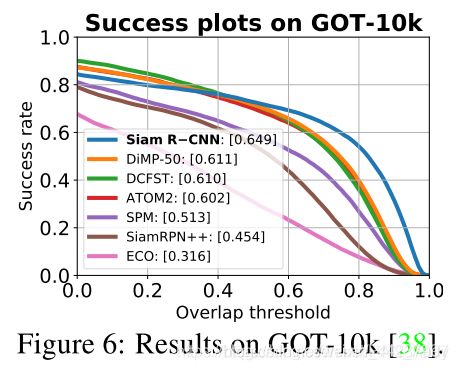
GOT-10k. 图6显示了我们在GOT-10k [38]测试集(180个视频,平均127帧的平均长度)上与六种SOTA方法相比的结果[5、116、19、90、48、18]。 在此基准上,方法仅允许使用GOT-10k训练集作为用于训练的视频数据。 因此,我们从COCO预训练开始训练新模型,并且仅在GOT-10k上训练。 我们实现了64.9%的成功率,比DiMP-50先前的最佳结果高3.8个百分点[5]。 这表明Siam R-CNN相对于所有以前方法的优势不仅是由于训练数据不同,还在于跟踪方法本身。
VOT2018. 表3显示了我们在VOT2018 [45]上的结果(60个视频,平均长度356帧)。按照VOT2018的 标准,使用基于重置的评估,一旦丢失对象,跟踪器将在五帧后用地面真值框重新启动,并受到处罚。主要评估标准是预期平均重叠(EAO)[46]。这种极端的短期跟踪方案不是为带有TDPA的Siam R-CNN设计的。它通常会触发重置,通常(没有基于重置的评估)Siam R-CNN可以自动恢复,从而得出EAO为0.140。由于VOT2018是重要的跟踪基准,因此我们创建了Siam R-CNN的简单短期版本,它假定前一帧的预测是正确的(必须是正确的,否则它将被重置),然后取平均重新检测的预测第一帧参考,并重新检测先前的预测,并将其与强大的空间先验结合在一起(补充材料中有更多详细信息)。我们的短期Siam R-CNN的EAO得分为0.408,可与许多SOTA方法相比。值得注意的是,两个版本的Siam R-CNN均获得最高的准确性得分。最后一行显示使用普通(非重置)评估时的平均重叠(AO)。在此设置中,Siam R-CNN达到0.476 AO,接近SiamRPN ++ 0.498的最佳结果。
4.2 Long-Term Visual Object Tracking Evaluation
为了评估Siam R-CNN进行长期跟踪的能力,我们评估了三个基准,即LTB35 [62],LaSOT [23]和OxUvA [86]。 在补充材料中,我们还评估了UAV20L [65]。 在长期跟踪中,序列会更长,并且对象可能会消失并再次出现(LTB35每个视频平均消失12.4个,每个平均消失40.6帧)。 在所有这些基准测试中,Siam R-CNN的性能明显优于所有以前的方法,这表明我们通过重新检测方法进行跟踪的优势。 通过在整个图像上进行全局搜索,而不是在先前预测的局部窗口内进行搜索,我们的方法具有更好的抗漂移性,并且可以在消失后轻松地重新检测目标。(这是如何实现的,怎样达到这种效果的,需要重点关注一下。)

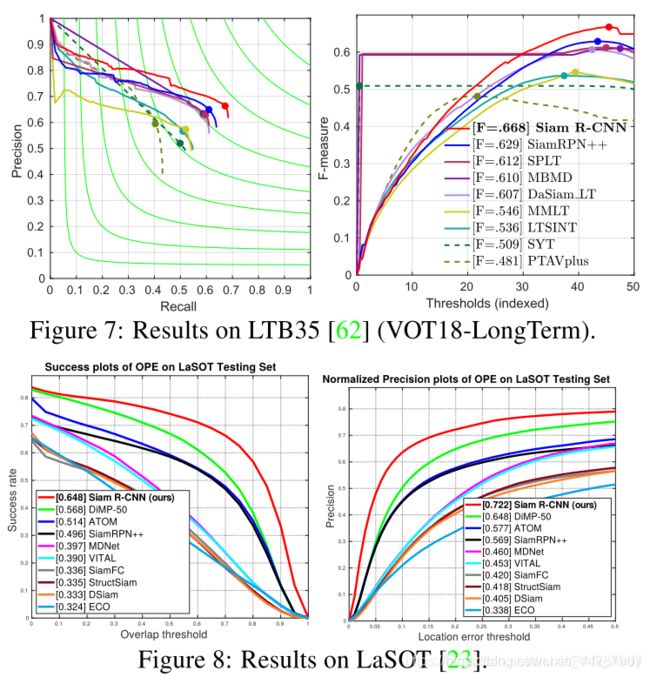
LTB35. 图7显示了与其他八种SOTA方法相比,我们的方法在LTB35基准(也称为VOT18-LT)上的结果[62](35个视频,平均长度为4200帧)。 要求跟踪器输出目标的置信度,以便在每个帧中进行预测。为一定范围的置信度阈值计算Precision(Pr)和Recall(Re)。F-score的计算为 F = 2 P r R e P r + R e F=\frac{2PrRe}{Pr+Re} F=
Pr+Re
2PrRe
。追踪器按在所有阈值上的F-score最大值进行排序。我们比较了2018年VOT-LT挑战赛中表现最好的6种方法[45]和SiamRPN ++ [48]和SPLT [104]。 Siam RCNN的F得分为66.8%,优于以前的所有方法,比以前的最佳结果高3.9个百分点。
LaSOT. 图8显示了与9种SOTA方法[5、19、48、67、80、4、112、29、18]相比,LaSOT测试集[23](280个视频,平均2448帧的平均长度)上的结果。 Siam RCNN以64.8%的成功率和72.2%的归一化精度获得了空前的成果。 与以前的最佳方法相比,成功率高8个百分点,归一化精度高7.4个百分点。
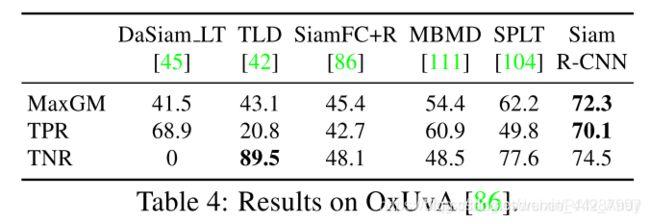
OxUvA. 表4显示了与五种SOTA方法相比,OxUvA测试集[86](166个视频,平均长度3293帧)的结果。 跟踪器必须在每个帧中做出艰难的决定,即对象是否存在。 为此,我们将检测器的置信度与在dev set上调整的阈值进行比较。 方法按真实阳性率(TPR)和真实阴性率(TNR)的最大几何平均值(MaxGM)进行排名。 Siam R-CNN的MaxGM比所有以前的方法高出10个百分点。
4.3 Video Object Segmentation (VOS) Evaluation
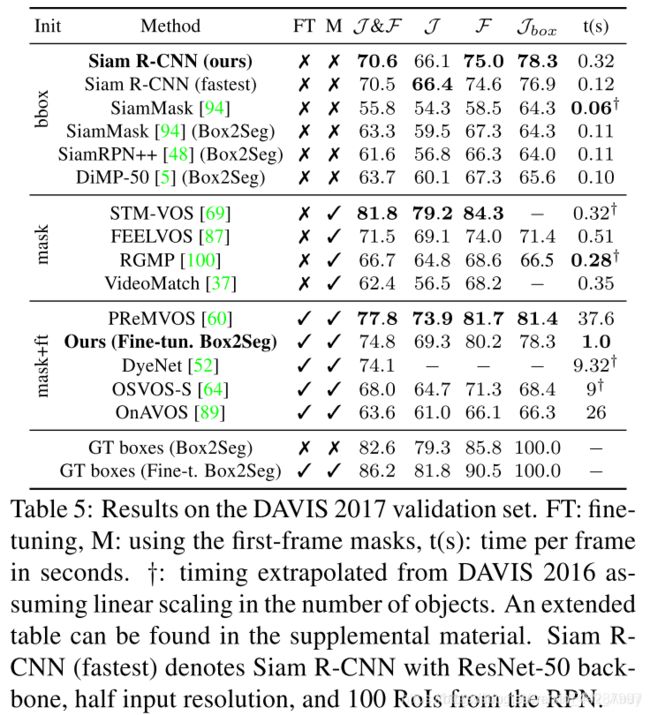
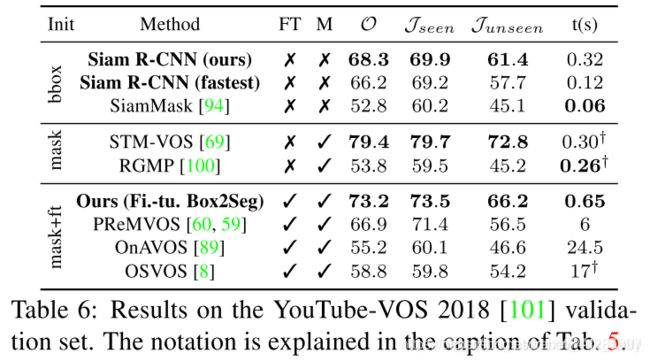

我们在VOS基准DAVIS17 [72]和YouTube-VOS [101]上进一步评估了我们的方法。除了其他跟踪评估之外,这还评估了两个方面。首先,能够产生准确的细分跟踪结果(在运行Siam R-CNN进行跟踪之后,我们引入了Box2Seg)。其次,要求同时跟踪多个对象。在VOS中,跟踪器使用 J \mathcal{J} J度量(预测的和地面真理掩码的平均联合相交(IoU))和 F \mathcal{F} F度量(边界相似性)进行评估。我们还引入了一个新的度量 J b o x \mathcal{J}_{box} J
box
,它是 J \mathcal{J} J度量,但使用围绕预测的和地面真实掩膜的边界框进行计算,可用于直接测量跟踪质量而无需掩膜。我们将VOS方法分为不使用第一帧掩膜的方法(如我们的方法),直接使用第一帧掩膜的方法以及对其进行微调的方法。除了带有Box2Seg的标准Siam R-CNN,我们还展示了在第一帧掩膜上对Box2Seg进行300步微调的结果(Siam RCNN从未进行微调,仅使用第一帧标注框)。
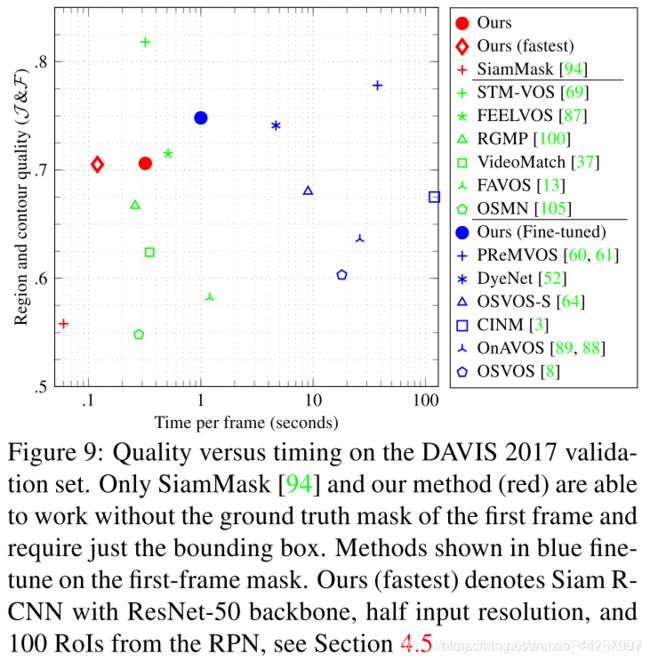
DAVIS 2017. 表5和图9显示了与SOTA方法相比,DAVIS 2017验证集的结果(72个视频(30个视频,平均长度67.4帧,每个视频平均2.03个对象))。方法按 J \mathcal{J} J和 F \mathcal{ F} F的平均值排序。SiamR-CNN明显优于仅使用第一帧边界框SiamMask [94]的以前的最佳方法,提高了14.8个百分点。为了评估Box2Seg有多少改进以及我们的跟踪有多少改进,我们将Box2Seg应用于SiamMask的输出。这确实改善了结果,但仍比我们的方法差7.3个百分点。我们还使用Box2Seg运行SiamRPN ++ [48]和DiMP-50 [5]进行比较。作为跟踪器可实现的性能的参考,我们在真值标注框上运行Box2Seg,结果得分为82.6%。
即使不使用第一帧掩膜,Siam R-CNN的性能也比使用第一帧掩膜的许多方法(例如RGMP [100]和VideoMatch [37])要好,甚至比执行缓慢的第一帧微调的方法要好(例如OSVOS-S [ 64]和OnAVOS [89]。我们的方法也更实用,因为与边界框初始化相比,手工创建完美的第一帧分割掩膜要繁琐得多。如果可以使用第一帧掩膜,那么我们就可以对此进行微调,以丧失速度为代价将结果提高4.2个百分点。我们在补充材料中报告了对DAVIS17 test-dev基准和DAVIS16 [71]的进一步评估。
YouTube-VOS. 表6和图10显示了我们的方法在YouTube-VOS 2018基准测试[101]上的结果(474个视频,平均长度26.6帧,平均每个视频1.89个对象),并和六种SOTA方法相比。 评估区分了训练集中(出现)和未训练(未出现)中的类别。 方法以总分 O进行排名,总分 O是可见和不可见类的 J和 F指标的平均值。 Siam R-CNN再次优于所有不使用第一帧掩膜的方法(提高了15.5个百分点),并且也优于PReMVOS [60,59]和除STM-VOS [69]以外的所有其他先前方法。 使用经过微调的Box2Seg的方法版本将结果提高了4.9个百分点。
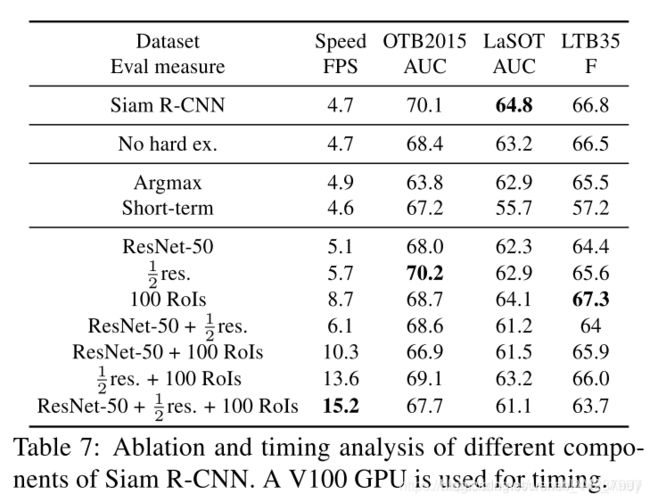
表7显示了在三个数据集上的Siam R-CNN消融实验及其运行速度(使用V100 GPU)。 Siam R-CNN使用ResNet-101主干网以每秒4.7帧(FPS)的速度运行,每帧1000 RPN提议,以及TDPA。
“No hard ex”行。 显示了不进行难例挖掘的结果(参见第3.2节)。 难例挖掘可将所有数据集的结果提高多达1.7个百分点。
我们将TDPA与仅在每个帧中使用最高评分的重新检测(“ Argmax”)和我们用于基于复位的VOT18评估的短期算法(“Short-term”)进行比较。 TDPA在所有数据集中均胜过这两个。 Argmax稍快一些,因为它不会使用先前的预测作为参考来进行重新检测。 对于长期数据集,Argmax明显优于Short-term甚至所有以前的方法,从而突出了通过重新检测进行长期跟踪的跟踪强度。
5 Conclusions
我们将Siam R-CNN引入具有Tracklet 动态规划算法的孪生两阶段全图像重检测架构。 Siam R-CNN在十个跟踪基准上均优于以前的所有方法,对于长期跟踪而言,结果尤其出色。 我们希望我们的工作会激发以后使用两阶段体系结构和全图像重新检测进行跟踪的工作。
**Summary
论文的主要方法是在孪生两阶段重检测的基础上,引入论文新提出的基于tracklet的动态规划方法,可以充分利用对第一帧模板和先前预测帧的优势,解决追踪问题,在长时追踪问题上的表现尤为突出。
论文的主要贡献为:(1)提出了Siam R-CNN构架;(2)提出了一种新的难例挖掘策略;(3)提出了一种新的基于tracklet的动态规划方法。
Research Objective
运用孪生两阶段重检测架构解决视觉目标追踪问题。
Problem Statement
论文解决的问题是视觉目标追踪问题,特别是长时追踪问题。
Method(s)
论文在Faster R-CNN的基础上,引入了孪生架构,用来解决视觉目标追踪问题。将Siam R-CNN与论文提出的基于tracklet的动态规划算法相结合,可以做出更好的追踪预测。对长期追踪尤其有效。 论文提出的基于tracklet的方法比较难理解。
Evaluation
论文在5个短时追踪数据集上评测了Siam R-CNN的短时追踪能力,实验表明,在短时追踪能力上,可以达到当前的SOTA水平。
论文在3个长时追踪数据集上评测了Siam R-CNN的长时追踪能力,实验表明,在长时追踪能力上,Siam R-CNN创立了新的SOTA水平,表现特别好。
论文还在Siam R-CNN的追踪结构之后,添加了box2seg部件,添加该部件后,可以高效地将追踪框转换为分割掩膜,实现追踪到分割的快速应用。在2个视频目标分割数据上的实验表明,在仅使用第一帧标注框进行初始化的方法中,Siam R-CNN可以取得新的SOTA,比较最近的SiamMask要高,在速度上大约是Siammak的六分之一。如果使用第一帧掩膜进行在线学习还可以达到更高。
Conclusion
论文将Siam R-CNN引入具有Tracklet 动态规划算法的孪生两阶段全图像重检测架构。 Siam R-CNN在十个跟踪基准上均优于以前的所有方法,对于长期跟踪而言,结果尤其出色。 作者希望他们的工作会激发以后使用两阶段体系结构和全图像重新检测进行跟踪的工作。**