Python爬虫进阶(八)——爬虫Scrapy实战之爬取腾讯招聘信息
前面咱们介绍了scrapy框架的使用,今天就来实战,爬取一下腾讯招聘的职位信息。
一、分析url
二、创建scrapy项目并生成爬虫
三、提取数据
四、保存数据
一、分析url
先确定url,这是网站的url:
url = 'https://careers.tencent.com/search.html'
咱们的需求是获取职位的名称、下面的工作职责、工作需求,并实现翻页操作。
分析网页源代码,发现这些信息都不在源码中,考虑使用抓包工具,进入network,刷新后出现一个带有“query”的文件,可以从中找到咱们想要的信息。因此,现在的url就是要作为起始的url:
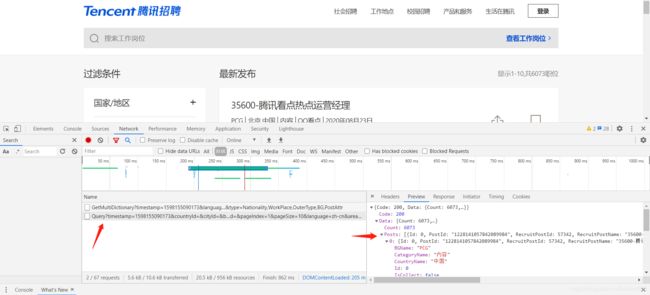
起始url(列表页,总的职位信息页面)为:
one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1598155090173&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn'
同样的方法,能找到起始url(详情页,单个职位的具体信息页面)为:
two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1598168153899&postId=1228141057842089984&language=zh-cn'
二、创建scrapy项目并生成爬虫
现在,通过terminal终端创建一个scrapy项目:
scrapy startproject tencent

创建爬虫 :scrapy genspider hr tencent.com

此时,咱们的scrapy爬虫框架就建好了,接下来进行相应的修改。
点开爬虫文件hr.py,把上一步确定的起始url添加到start_urls中

三、提取数据
1.对setting文件进行设置
为了不让其他信息显示出来干扰数据,设置中加入如下字段:
LOG_LEVEL = 'WARNING'
如下图:

2.添加start文件
在总目录下添加start.py文件,用于运行爬虫。

start文件代码如下:
from scrapy import cmdline
cmdline.execute(['scrapy','crawl','hr'])
右键run运行。
结果如下:
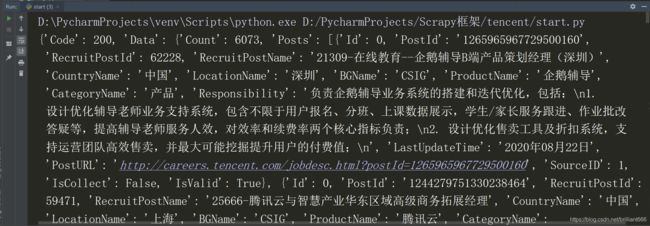
可以看到,数据已经获取到了。要做进一步处理。
3.对解析函数parse()进行定义
因为要实现翻页操作,因此要对每一页的url进行遍历,在parse()中,这部分代码如下(要爬取1-10页):
import scrapy
import json # 后面要用到json数据转换为字典
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
# 列表页(收集职位信息的页面)
one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1598155090173&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
start_urls = [one_urls.format(1)] # 格式化起始url(第一页)
# 详情页(具体职位的信息页面)
two_url = 'https://careers.tencent.com/jobdesc.html?postId={}'
def parse(self, response):
for page in range(1,11):
# 遍历访问10个页码url
list_url = self.one_url.format(page)
# 请求返回数据
yield scrapy.Request(
url=list_url,
# 将响应结果传到下面的parse_one函数中
callback=self.parse_one
)
def parse_one(self,response):
data = json.loads(response.text)
for job in data['Data']['Posts']: # 用字典收集数据
item = {
}
item['招募职位'] = job['RecruitPostName']
item['工作类别'] = job['CategoryName']
post_id = job['PostId']
# 通过拼接得到详情页url
detail_url = self.two_url.format(post_id)
# 请求返回数据
yield scrapy.Request(
url=detail_url,
meta={
'item':item}, # 利用meta进行传值
# 将响应结果传到下面的parse_two函数中
callback=self.parse_two
)
print(item)
结果如下:

接着编辑parse_two():
def parse_two(self,response):
# 将前面的item字典传过来继续加值
item = response.meta['item']
data = json.loads(response.text)
item['工作职责'] = data['Data']['Responsibility']
item['工作要求'] = data['Data']['Requirement']
print(item)
结果如下:

可以发现,整个数据是从最后一页(第10页)倒着往前打印的。至此,数据已经全都获取到了。
其中,要对页码url进行请求,获取每页数据,会用到scrapy.Request
这是其中的参数:
scrapy.Request(url, callback=None, method=‘GET’, headers=None, bod y=None,cookies=None, meta=None, encoding=‘utf-8’, priority=0, 2 dont_filter=False, errback=None, flags=None)
scrapy.Request常用参数为:
callback:指定传⼊的URL交给哪个解析函数去处理,回调函数是用来自定义一个接收函数名(接收响应结果)。
meta:实现不同的解析函数中传递数据,meta默认会携带部分信息,比如下载延迟,请求深度。
dont_filter:让scrapy的去重不会过滤当前URL,scrapy默认有URL去重功能,对需要 重复请求的URL有重要⽤途。
4.一些细节
4.1 items文件的使用
如果想把要获取的字段提前定义好,要用到items.py文件。在其中将之前定义要获取的字段按照这一格式写好:
class TencentItem(scrapy.Item):
字段名 = scrapy.Field()
将tencent文件夹设置成根目录:右键tencent文件夹

设置成根目录,在hr.py文件中导入:
from tencent.items import TencentItem
在已定义的字段之前,加上:item = TencentItem(),再次执行即可,能够排除因字段错误导致的问题。
4.2 验证爬虫文件的其他方式
前面咱们讲了2种方法,今天来介绍第三种方法。
isinstance():判断一个对象是否是另一个对象的实例,可以沿用到这里:
from tencent.items import TencentItem
class TencentPipeline:
def process_item(self, item, spider):
if isinstance(item,TencentItem):
print('当前item来自TencentItem')
return item
这样也能验证是不是某个爬虫文件的数据,要记住在这之前,要yield 字段数据;打开setting中的pipeline。再去运行start.py文件。
四、保存数据
在pipelines文件中进行保存数据的剩余工作。关于pipelines的使用,在前面已经介绍过。
好了,今天的scrapy实战操作就到这里了。
实战部分:
第一篇:Python爬虫实战之 爬取全国理工类大学数量+数据可视化
第二篇:Python爬虫实战之 爬取王者荣耀皮肤
爬虫基础部分:
第一篇:Python的要点(搭建环境、安装配置、第三方库导入方法详细过程)
第二篇:Python爬虫初探(一)——了解爬虫
第三篇:Python爬虫初探(二)——爬虫的请求模块
第四篇:Python爬虫初探(三)——爬虫之正则表达式介绍
第五篇:Python爬虫初探(四)——爬虫之正则表达式实战(爬取图片)
第六篇:Python爬虫初探(五)——爬虫之xpath与lxml库的使用
第七篇:Python爬虫初探(六)——爬虫之xpath实战(爬取高考分数线信息)
第八篇:Python爬虫初探(七)——爬虫之Beautifulsoup4介绍(Ⅰ)
第九篇:Python爬虫初探(八)——爬虫之Beautifulsoup4介绍(Ⅱ)
第十篇:Python爬虫初探(九)——爬虫之Beautifulsoup4实战(爬取豆瓣信息)
第十一篇:Python爬虫初探(十)——爬虫总结
爬虫进阶部分:
第一篇:Python爬虫进阶(一)——爬虫之动态数据与selenium
第二篇:Python爬虫进阶(二)——爬虫之多任务模块(Ⅰ)
第三篇:Python爬虫进阶(三)——爬虫之多任务模块(Ⅱ)
第四篇:Python爬虫进阶(四)——爬虫之多任务模块(Ⅲ)
第五篇:Python爬虫进阶(五)——爬虫之多线程爬虫实战(爬取王者荣耀皮肤)
第六篇:Python爬虫进阶(六)——爬虫之Scrapy初探(Ⅰ)
第七篇:Python爬虫进阶(七)——爬虫之Scrapy初探(Ⅱ)