DenseNet论文详解及PyTorch复现
DenseNet
1. ResNet 与 DenseNet
ResNet(深度残差网络,Deep residual network, ResNet):通过建立前面层与后面层之间的“短路连接”,这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。
DenseNet:采用密集连接机制,即互相连接所有的层,每个层都会与前面所有层在channel维度上连接(concat)在一起,实现特征重用,作为下一层的输入。

这样,不但减缓了梯度消失的现象,也使其可以在参数与计算量更少的情况下实现比ResNet更优的性能。


公式表示
传统的网络在 l l l层的输出为:
x l = H l ( x l − 1 ) x_l=H_l(x_{l-1}) xl=Hl(xl−1)
对于ResNet,增加了来自上一层输入:
x l = H l ( x l − 1 ) + x l − 1 x_l=H_l(x_{l-1}) + x_{l-1} xl=Hl(xl−1)+xl−1
在DenseNet中,会连接前面所有层作为输入:
x l = H l ( [ x 0 , x 1 , . . . , x l − 1 ] ) x_l=H_l([x_0, x_1, ..., x_{l-1}]) xl=Hl([x0,x1,...,xl−1])
H l ( ⋅ ) H_l(·) Hl(⋅)代表是非线性转化函数,它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。
特征传递方式是直接将前面所有层的特征concat后传到下一层,而不是前面层都要有一个箭头指向后面的所有层。
网络结构
DenseNet的密集连接方式需要特征图大小保持一致。所以DenseNet网络中使用DenseBlock+Transition的结构。
DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。
Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。
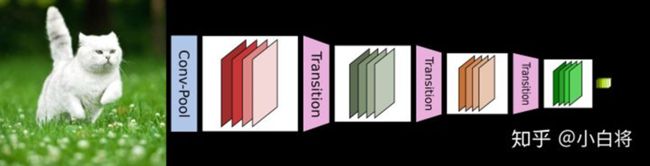
DenseBlock
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H l ( ⋅ ) H_l(·) Hl(⋅)采用的是 B N + R e L U + 3 x 3 C o n v BN+ReLU+3x3 Conv BN+ReLU+3x3Conv的结构。
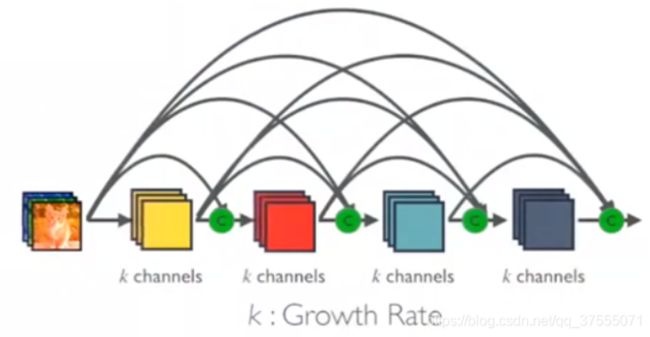
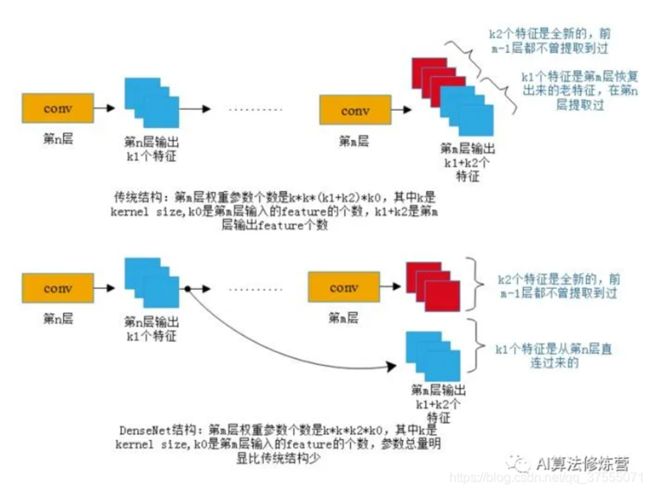
假定输入层的特征图的channel数为k0,DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为k,那么l层输入的channel数为k0+(l−1)k, 我们将k称之为网络的增长率(growth rate)。
因为每一层都接受前面所有层的特征图,即特征传递方式是直接将前面所有层的特征concat后传到下一层,一般情况下使用较小的K(比如12),要注意这个K的实际含义就是这层新提取出的特征。
Dense Block采用了激活函数在前、卷积层在后的顺序,即BN-ReLU-Conv的顺序,这种方式也被称为pre-activation。通常的模型relu等激活函数处于卷积conv、批归一化batchnorm之后,即Conv-BN-ReLU,也被称为post-activation。作者证明,如果采用post-activation设计,性能会变差。

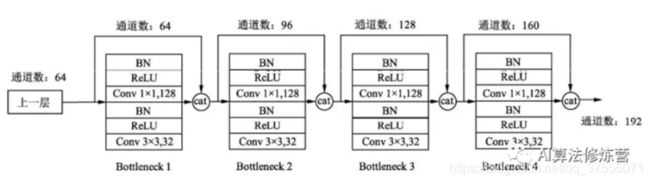
bottleneck层
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,即
B N + R e L U + 1 × 1 ⋅ C o n v + B N + R e L U + 3 × 3 ⋅ C o n v BN+ReLU+1\times 1·Conv+BN+ReLU+3\times 3· Conv BN+ReLU+1×1⋅Conv+BN+ReLU+3×3⋅Conv
称为DenseNet-B结构。其中1x1 Conv得到4k个特征图它起到的作用是降低特征数量,从而提升计算效率。
每一个Bottleneck输出的特征通道数是相同的。
这里1×1卷积的作用是固定输出通道数,达到降维的作用,1×1卷积输出的通道数通常是GrowthRate的4倍。当几十个Bottleneck相连接时,concat后的通道数会增加到上千,如果不增加1×1的卷积来降维,后续3×3卷积所需的参数量会急剧增加。
比如,输入通道数64,增长率K=32,经过15个Bottleneck,通道数输出为64+15*32=544,
如果不使用1×1卷积,第16个Bottleneck层参数量是3*3*544*32=156672,
如果使用1×1卷积,第16个Bottleneck层参数量是1*1*544*128+3*3*128*32=106496,可以看到参数量大大降低。
Transition层
它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为
B N + R e L U + 1 × 1 C o n v + 2 × 2 A v g P o o l i n g BN+ReLU+1\times 1 Conv+2\times 2 AvgPooling BN+ReLU+1×1Conv+2×2AvgPooling
Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为 m ,Transition层可以产生 θ m \theta m θm个特征(通过卷积层),其中 θ \theta θ是压缩系数(compression rate)。当Θ=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,一般使用Θ=0.5。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。

实验结果及讨论
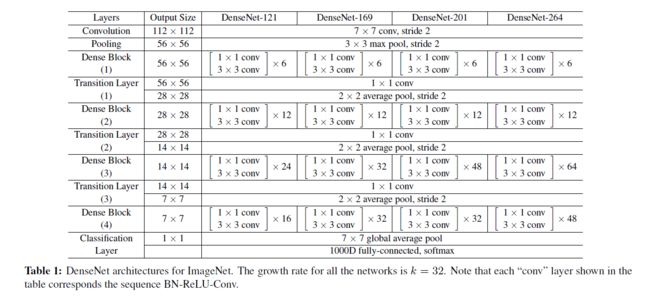
文章所提的网络框架结构有四种如表所示:
DenseNet在CIFAR-100和ImageNet数据集上与ResNet的对比结果。
从图8中可以看到,只有0.8M的DenseNet-100性能已经超越ResNet-1001,并且后者参数大小为10.2M。而从图9中可以看出,同等参数大小时,DenseNet也优于ResNet网络。


DenseNet优势
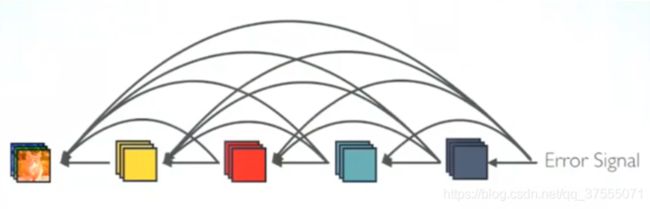
1.更强的梯度流动:
由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”。误差信号可以很容易地传播到较早的层,所以较早的层可以从最终分类层获得直接监管(监督)。
减轻了vanishing-gradient(梯度消失) 过梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。
2.减少了参数数量
3.保存了低维度的特征
在标准的卷积网络中,最终输出只会利用提取最高层次的特征。
而在DenseNet中,它使用了不同层次的特征,倾向于给出更平滑的决策边界。这也解释了为什么训练数据不足时DenseNet表现依旧良好。


DenseNet的不足
DenseNet的不足在于由于需要进行多次Concatnate操作,数据需要被复制多次,显存容易增加得很快,需要一定的显存优化技术。另外,DenseNet是一种更为特殊的网络,ResNet则相对一般化一些,因此ResNet的应用范围更广泛。
网络内容改进Memory-Efficient Implementation of DenseNets
PyTorch实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True))
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size *
growth_rate, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True))
self.add_module('conv2', nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate,training=self.training)
return torch.cat([x, new_features], 1)
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('denselayer%d' % (i+1), layer)
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(num_init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
]))
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers=num_layers, num_input_features=num_features,
bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate)
self.features.add_module('denseblock%d' % (i+1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i+1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.avg_pool2d(out, kernel_size=7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
def densenet121(**kwargs):
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16), **kwargs)
return model
def densenet169(**kwargs):
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 24, 32, 32), **kwargs)
return model
def densenet201(**kwargs):
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 48, 32), **kwargs)
return model
def densenet264(**kwargs):
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 64, 48), **kwargs);
return model
if __name__ == '__main__':
# 'DenseNet' 'DenseNet121' 'DenseNet169' 'DenseNet201' 'DenseNet264'
# Example
net = DenseNet()
print(net)
内容参考:
B站:https://www.bilibili.com/video/BV1Ly4y1z7Gh?spm_id_from=333.999.0.0
https://www.cnblogs.com/lyp1010/p/11820967.html