《Neural Factorization Machines for Sparse Predictive Analytics》NFM模型及python代码
1 原文
点击【原文】即可进行下载
2 NFM模型
在当今互联网工业界中,有许多预测任务需要用到大量的类别特征。要想将这些类别特征送入到模型中,就必须得将其onehot。但这样一来,就会产生大量的稀疏特征,要想从这些稀疏特征中充分学习到有用的信息,必须要考虑特征之间的相互作用。
FM算法是一种常用的解决方案,因为它充分考虑了二阶特征之间的相互作用。然而FM有一个缺点,就是它仅仅以线性的方式组合了特征,并不能考虑到特征之间的非线性关系。
本文提出了一个称为Neural Factorization Machine (NFM)的模型,来解决上述问题。NFM充分结合了FM提取的二阶线性特征与神经网络提取的高阶非线性特征。总得来说,FM可以被看作一个没有隐含层的NFM,故NFM肯定比FM更具表现力。
模型的输出结果:
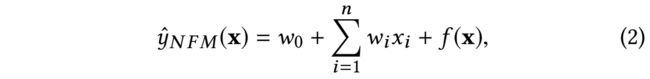
上式的第1项与第2项是与FM相似的线性回归部分,第3项是NFM的核心部分,它的网络结构如下:
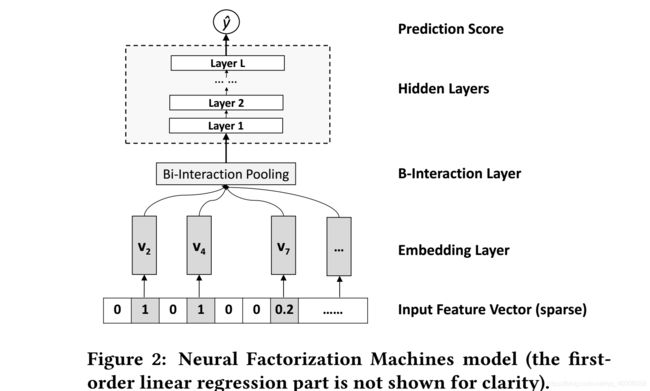
Embedding Layer和FM、PNN、AFM等的embedding layer是相同的,得到的vector其实就是我们在FM中要学习的隐变量v。
Bi-Interaction Layer 上层得到的输出是一个特征向量的embedding的集合,本层本质上是做一个pooling的操作,让这个embedding向量集合变为一个向量,公式如下:

其中 ⨀代表两个向量对应的元素相乘。显然,该层的输出向量为 kk 维,本层采用的pooling方式与传统的max pool和average pool一样都是线性复杂度的,上式可以变换为:

hidden layers就是多个标准的神经网络全连接层,执行过程如下:

prediction layer的输出即为 f ( x ) f(x) f(x)的值:
![]()

3 python
import numpy as np
import tensorflow as tf
from time import time
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.metrics import roc_auc_score
class AFM(BaseEstimator, TransformerMixin):
def __init__(self, feature_size, field_size,
embedding_size=8,
deep_layers=[32, 32], deep_init_size = 50,
dropout_deep=[0.5, 0.5, 0.5],
deep_layer_activation=tf.nn.relu,
epoch=10, batch_size=256,
learning_rate=0.001, optimizer="adam",
batch_norm=0, batch_norm_decay=0.995,
verbose=False, random_seed=2016,
loss_type="logloss", eval_metric=roc_auc_score,
greater_is_better=True,
use_inner=True):
assert loss_type in ["logloss", "mse"], \
"loss_type can be either 'logloss' for classification task or 'mse' for regression task"
self.feature_size = feature_size
self.field_size = field_size
self.embedding_size = embedding_size
self.deep_layers = deep_layers
self.deep_init_size = deep_init_size
self.dropout_dep = dropout_deep
self.deep_layers_activation = deep_layer_activation
self.epoch = epoch
self.batch_size = batch_size
self.learning_rate = learning_rate
self.optimizer_type = optimizer
self.batch_norm = batch_norm
self.batch_norm_decay = batch_norm_decay
self.verbose = verbose
self.random_seed = random_seed
self.loss_type = loss_type
self.eval_metric = eval_metric
self.greater_is_better = greater_is_better
self.train_result,self.valid_result = [],[]
self.use_inner = use_inner
self._init_graph()
def _init_graph(self):
self.graph = tf.Graph()
with self.graph.as_default():
tf.set_random_seed(self.random_seed)
self.feat_index = tf.placeholder(tf.int32,
shape=[None,None],
name='feat_index')
self.feat_value = tf.placeholder(tf.float32,
shape=[None,None],
name='feat_value')
self.label = tf.placeholder(tf.float32,shape=[None,1],name='label')
self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')
self.train_phase = tf.placeholder(tf.bool,name='train_phase')
self.weights = self._initialize_weights()
# Embeddings
self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * K
feat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])
self.embeddings = tf.multiply(self.embeddings,feat_value) # N * F * K
# first order term
self.y_first_order = tf.nn.embedding_lookup(self.weights['feature_bias'], self.feat_index)
self.y_first_order = tf.reduce_sum(tf.multiply(self.y_first_order, feat_value), 2)
# second order term
# sum-square-part
self.summed_features_emb = tf.reduce_sum(self.embeddings, 1) # None * k
self.summed_features_emb_square = tf.square(self.summed_features_emb) # None * K
# squre-sum-part
self.squared_features_emb = tf.square(self.embeddings)
self.squared_sum_features_emb = tf.reduce_sum(self.squared_features_emb, 1) # None * K
# second order
self.y_second_order = 0.5 * tf.subtract(self.summed_features_emb_square, self.squared_sum_features_emb)
# Deep component
self.y_deep = self.y_second_order
for i in range(0, len(self.deep_layers)):
self.y_deep = tf.add(tf.matmul(self.y_deep, self.weights["layer_%d" % i]), self.weights["bias_%d" % i])
self.y_deep = self.deep_layers_activation(self.y_deep)
self.y_deep = tf.nn.dropout(self.y_deep, self.dropout_keep_deep[i + 1])
# bias
self.y_bias = self.weights['bias'] * tf.ones_like(self.label)
# out
self.out = tf.add_n([tf.reduce_sum(self.y_first_order,axis=1,keep_dims=True),
tf.reduce_sum(self.y_deep,axis=1,keep_dims=True),
self.y_bias])
# loss
if self.loss_type == "logloss":
self.out = tf.nn.sigmoid(self.out)
self.loss = tf.losses.log_loss(self.label, self.out)
elif self.loss_type == "mse":
self.loss = tf.nn.l2_loss(tf.subtract(self.label, self.out))
if self.optimizer_type == "adam":
self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate, beta1=0.9, beta2=0.999,
epsilon=1e-8).minimize(self.loss)
elif self.optimizer_type == "adagrad":
self.optimizer = tf.train.AdagradOptimizer(learning_rate=self.learning_rate,
initial_accumulator_value=1e-8).minimize(self.loss)
elif self.optimizer_type == "gd":
self.optimizer = tf.train.GradientDescentOptimizer(learning_rate=self.learning_rate).minimize(self.loss)
elif self.optimizer_type == "momentum":
self.optimizer = tf.train.MomentumOptimizer(learning_rate=self.learning_rate, momentum=0.95).minimize(
self.loss)
#init
self.saver = tf.train.Saver()
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.sess.run(init)
# number of params
total_parameters = 0
for variable in self.weights.values():
shape = variable.get_shape()
variable_parameters = 1
for dim in shape:
variable_parameters *= dim.value
total_parameters += variable_parameters
if self.verbose > 0:
print("#params: %d" % total_parameters)
def _initialize_weights(self):
weights = dict()
#embeddings
weights['feature_embeddings'] = tf.Variable(
tf.random_normal([self.feature_size,self.embedding_size],0.0,0.01),
name='feature_embeddings')
weights['feature_bias'] = tf.Variable(tf.random_normal([self.feature_size,1],0.0,1.0),name='feature_bias')
weights['bias'] = tf.Variable(tf.constant(0.1),name='bias')
#deep layers
num_layer = len(self.deep_layers)
input_size = self.embedding_size
glorot = np.sqrt(2.0/(input_size + self.deep_layers[0]))
weights['layer_0'] = tf.Variable(
np.random.normal(loc=0,scale=glorot,size=(input_size,self.deep_layers[0])),dtype=np.float32
)
weights['bias_0'] = tf.Variable(
np.random.normal(loc=0,scale=glorot,size=(1,self.deep_layers[0])),dtype=np.float32
)
for i in range(1,num_layer):
glorot = np.sqrt(2.0 / (self.deep_layers[i - 1] + self.deep_layers[i]))
weights["layer_%d" % i] = tf.Variable(
np.random.normal(loc=0, scale=glorot, size=(self.deep_layers[i - 1], self.deep_layers[i])),
dtype=np.float32) # layers[i-1] * layers[i]
weights["bias_%d" % i] = tf.Variable(
np.random.normal(loc=0, scale=glorot, size=(1, self.deep_layers[i])),
dtype=np.float32) # 1 * layer[i]
return weights
def get_batch(self,Xi,Xv,y,batch_size,index):
start = index * batch_size
end = (index + 1) * batch_size
end = end if end < len(y) else len(y)
return Xi[start:end],Xv[start:end],[[y_] for y_ in y[start:end]]
# shuffle three lists simutaneously
def shuffle_in_unison_scary(self, a, b, c):
rng_state = np.random.get_state()
np.random.shuffle(a)
np.random.set_state(rng_state)
np.random.shuffle(b)
np.random.set_state(rng_state)
np.random.shuffle(c)
def predict(self, Xi, Xv,y):
"""
:param Xi: list of list of feature indices of each sample in the dataset
:param Xv: list of list of feature values of each sample in the dataset
:return: predicted probability of each sample
"""
# dummy y
feed_dict = {self.feat_index: Xi,
self.feat_value: Xv,
self.label: y,
self.dropout_keep_deep: [1.0] * len(self.dropout_dep),
self.train_phase: True}
loss = self.sess.run([self.loss], feed_dict=feed_dict)
return loss
def fit_on_batch(self,Xi,Xv,y):
feed_dict = {self.feat_index:Xi,
self.feat_value:Xv,
self.label:y,
self.dropout_keep_deep:self.dropout_dep,
self.train_phase:True}
loss,opt = self.sess.run([self.loss,self.optimizer],feed_dict=feed_dict)
return loss
def fit(self, Xi_train, Xv_train, y_train,
Xi_valid=None, Xv_valid=None, y_valid=None,
early_stopping=False, refit=False):
has_valid = Xv_valid is not None
for epoch in range(self.epoch):
t1 = time()
self.shuffle_in_unison_scary(Xi_train, Xv_train, y_train)
total_batch = int(len(y_train) / self.batch_size)
for i in range(total_batch):
Xi_batch, Xv_batch, y_batch = self.get_batch(Xi_train, Xv_train, y_train, self.batch_size, i)
self.fit_on_batch(Xi_batch, Xv_batch, y_batch)
if has_valid:
y_valid = np.array(y_valid).reshape((-1,1))
loss = self.predict(Xi_valid, Xv_valid, y_valid)
print("epoch",epoch,"loss",loss)
参考
1、原文:http://xueshu.baidu.com/s?wd=paperuri:(698cc0e22cefdff2b65f7c24c16d5112)&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http://arxiv.org/pdf/1708.05027&ie=utf-8&sc_us=6917339300733978278
2、代码:https://github.com/princewen/tensorflow_practice/blob/master/recommendation/Basic-AFM-Demo/main.py