二分类最优阈值确定_最常用的分类模型评价指标整理_190416
一些比赛,看到不同的比赛有很多不同的模型评价标准,于是就想整理一份关于模型评价标准的资料分享一下,有不足和错误之处,希望能指教。
本文会先介绍二分类模型的主要评价指标:
AUC
KS
Log-loss
Accuracy/Recall/Precision/F1-score
紧接着会先介绍多分类模型的主要评价指标:
Accuracy
F1-macro
F1-score-weighted
【二分类模型】
1.AUC
AUC可以说是在比赛中二分类最常见的评价指标,在天池和Kaggle中二分类问题很多采取该指标。因为很多机器学习的模型对分类问题的预测结果都是概率,如果要计算accuracy,需要手动设定一个阈值(很多软件默认是0.5,但实际0.5可能不是最优的),如果预测概率高于这个阈值就判为1小于这个阈值就判为0,这个阈值就很大程度上影响了accuracy的计算,而AUC就避免了这种计算。另外当样本有偏时比如1的比率只有1%时,accuracy的区分度就很难体现出来,即使不做模型全判为0也有99%的准确率。
AUC的全称是(Area Under then Curve Of ROC), 十分直白就是ROC曲线下方的面积,因此就要讲到ROC(Receiver operating characteristic curve)接收者操作特征曲线了。
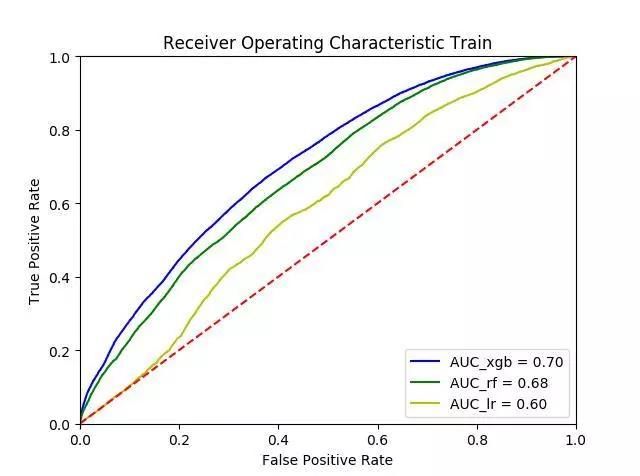
上图分别为三个模型在同一个数据上的ROC曲线,通常单个的模型ROC曲线并不能看出有效的价值,经常我们会把不同模型画在同一张ROC曲线上进行比较。
ROC曲线的横轴为False Positive Rate,也叫伪阳率(FPR),即预测错误且实际分类为负的数量与所有负样本数量的比例,纵轴为True Positive Rate,也叫真阳率(TPR),即预测正确且实际分类为正的数量 与 所有正样本的数量的比例,这里有些同学可能会觉得有点绕晕了,其实当别人问我时候我自己有点混乱,因此经常用混淆矩阵(confusion matrix)来进行记忆。
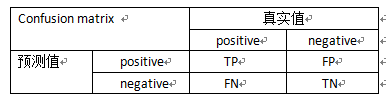
所以我们就能方便的理解FPR和TPR了。横轴FPR=FP/(FP+TN) 即实际的负样本当中,错误预测的比例是多少?纵轴TPR =TP/(TP+FN) 即实际的正样本中,正确预测的比例是多少?
现在可能有人会问我们算ROC的时候前面不是说只需要提供预测概率和真实LABEL就可以了么,那么为何还有判定为正和负呢。其实这个问题就解开了ROC曲线是如何画出了,对于一个阈值我们在判定后只能得到一个FPR和TPR,我们比如将阀值从0到1取等距的100份,此时的ROC就可以通过100个的阀值来得到多组的TPR和FPR(也可以用所有的得到概率作为阈值),通过这多组的TPR和FPR,我们最终就能得到ROC曲线,可能有同学会看到一些软件输出的ROC曲线是阶梯状的,其实是因为样本数的不足或者阈值过少使得曲线不够平滑。
使用ROC曲线还有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡现象,即1的比例很少或者很多,而且测试数据中的正负样本的分布也可能随着时间变化,此时ROC曲线和AUC值会比较稳定。
得到ROC曲线后通过面积的计算AUC值就自然可以得到了。下面是python中用内置的iris数据简单计算ROC的一个例子。
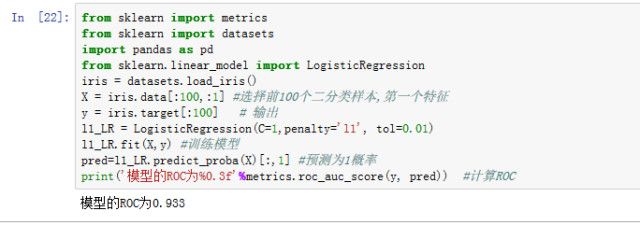
2.KS
Kolmogorov-Smirnov两样本检验法简称为KS检验法,基于经验分布函数的距离而构造, 检验两个累积分布的区分度,传统上说KS值就是KS检验法的统计量。我们通过预测概率或者分数和真实的label就可以计算出KS值。

通过画出KS图我们可以更加清晰的理解KS值是如何计算的。红色为样本实际标签为0的累积分布,蓝色为实际标签为1的累积分布。累积分布如何计算呢,我们先把标签为0的和标签为1的样本分开,然后将概率从0-1取等距的100份或者根据所有概率切成相应的份数,计算0和1的样本中小于等于该概率的样本占该类别总样本的比率即得到两类样本的累计分布,而KS即两样本累计分布差的最大值。
KS的另一种解释为真正率(TPR)与假正率(FPR)随阀值变化差的最大值。其中TPR=TP/(TP+FN), FPR=FP/(FP+TN)。
利用第一节的预测结果计算了KS如下:

3.Log-loss
很多机器学习的算法通常会用logloss作为模型评价的指标,对数损失(Log loss)亦被称为逻辑回归损失(Logistic regression loss)或交叉熵损失(Cross-entropy loss),简单来说就是逻辑回归的损失函数。Logloss的公式如下:
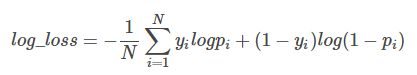
其中y为预测值,N为样本数,p为预测概率,。利用第一节的预测结果计算了Log-loss如下:

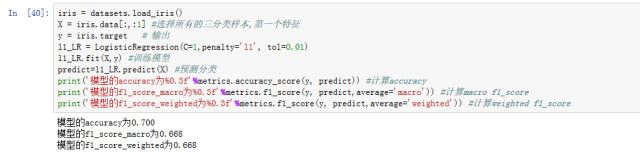
4.AccuracyRecallPrecisionF1-score
之前的三个指标都是根据分类模型的概率与真实值计算的评价指标,而有些情况下,需要给出具体的分类情况,此时主要可以从下面的几个指标进行分析。
1. Accuracy
准确率顾名思义即在所有样本中判别准确的比率,用混淆矩阵中的字母可表示为:
Accuracy=( TP+ TN)/(TP+ FP+FN+ TN)
2. Recall
召回率(查全率),即为在实际为1的样本中,预测为1的样本占比,用混淆矩阵中的字母可表示为:
Recall= TP/(TP+FN)
3. Precision
精确率( 查准率 ),即为在预测为1的样本中,预测正确(实际为1)的人占比,,用混淆矩阵中的字母可表示为:
Precision= TP/(TP+FP)
4.F1-score
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0。
随着阈值的变化,就像假设检验的两类错误一样,如下图所示召回率和精确率不能同时提高,因此我们就需要一个指标来调和这两个指标,于是人们就常用F1-score来进行表示
F1=2*Precision * Recall /( Precision + Recall)

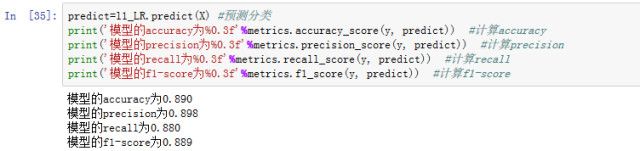
用第一节的模型得到预测分类计算了上面的四个指标如下:
【多分类模型】
1.Accuracy
准确率是指在分类中,使用测试集对模型进行分类,分类正确的记录个数占总记录个数的比例。样本均衡时用准确率较好,在某些类别过大或者过小时,准确率的效果会大打折扣,因此会用到几种F1 SCORE。
2.F1-macro
f1-score-macro是每一类算出的 f1 score的算术平均以三类分类为例,每一类以one VS all计算各类的f1 score:
每一类计算各类的f1 score如下:
f1[class 1] =
2*(precision[class1]*recall[class1])/(precision[class1]+recall[class1])
f1[class 2]=
2*(precision[class2]*recall[class2])/(precision[class2]+recall[class2])
f1[class 3]=
2*(precision[class3]*recall[class3])/(precision[class3]+recall[class3])
然后计算这些f1-score的平均值为
f1-score-macro= (f1[class1]+f1[class2]+f1[class3] )/3
3.F1-score-weighted
f1-score-weighted是每一类算出的 f1 score的加权平均以三类分类为例, 每一类计算各类的f1 score,每一类的实际样本数N1,N2, N3,公式如下:
f1-score-macro=
(N1*f1[class 1] +N2* f1[class 2] +N3* f1[class 3] ) /(N1+N2+N3)
具体的计算只要在f1_score后面加上选项就可以了