R语言基础
R语言基础
- 前言
- 一、R相关基础
-
- 1.常见符号
- 2.其他注意点
- 二、R语言基本操作函数
-
- 1.变量的基本操作
- 2.其他函数
- 三、R包
-
- 1.plyr包
- 2.glmnet包
- 3.foreach包
前言
摘录一些与R相关的基础内容,以便以后查看
一、R相关基础
1.常见符号
赋值时:c代表向量,list代表列表,rbind代表数据框
作为函数时:cbind(): 根据列进行合并,即叠加所有列,m列的矩阵与n列的矩阵cbind()最后变成m+n列,合并前提是cbind(a, c)中矩阵a、c的行数必需相符;rbind(): 根据行进行合并
R语言里面的特殊值,即R的保留字(reserved words)
详见知乎文章-R语言初级教程(12): NA、Inf、NaN、NULL 特殊值
NA:表示缺失值(Missing value),是“Not Available”的缩写
Inf:表示无穷大,是“Infinite”的缩写
NaN:表示非数值,是“Not a Number”的缩写
NULL:表示空值,即没有内容
2.其他注意点
verbose=FALSE #不打印运行信息
在处理多重复任务时,尽量不要使用显式的for循环,而要尽可能的使用R语言内置的apply组函数,这样可以极大地提高代码运行效率。当然除了内置的apply组函数之外,你还有另外一个更好地选择,就是利用一些支持并行运算的扩展包。
二、R语言基本操作函数
1.变量的基本操作
详见豆瓣文章-(1)变量的基本操作
1).变量变换
as.array(x),as.data.frame(x),as.numeric(x),as.logical(x),as.complex(x),as.character(x),…转换变量类型;使用如下命令可得到全部列表,methods(as)
factor():将一个向量转化为一个因子
2).变量信息
is.na(x),is.null(x),is.array(x),is.data.frame(x),is.numeric(x),is.complex(x),is.character (x),…检验变量的类型;使用如下命令得到全部列表,methods(is)
length(x):x中元素的个数
dim(x):查看变量的维数;重新设置的维数,例如dim(x)=c(3,2)
dimnames(x):重新设置对象的名称
nrow(x):行的个数
ncol(x):列的个数
class(x):得到或设置x的类;class(x)<-c(3,2)
unclass(x):删除x的类
attr(x,which):得到或设置x的属性which
attributes(obj):得到或设置obj的属性列表
fix,edit:对数据框数据进行表格形式的编辑
3).数据选取和操作
which.max(x):返回x中最大元素的指标
which.min(x):返回x中最小元素的指标
rev(x):翻转x中所有的元素
sort(x):升序排列x中的元素;降序排列使用:rev(sort(x))
cut(x,breaks):将x分割成为几段(或因子);breaks为段数或分割点向量
match(x,y):返回一个和x长度相同且和y中元素相等的向量不等则返回NA
which(x==a):如果比较操作为真(TRUE),返回向量x的指针
choose(n,k):组合数的计算
na.omit(x):去除缺失值(NA)(去除相关行如果x为矩阵或数据框)
na.fail(x):返回错误信息,如果x包含至少一个NA
unique(x):如果x为向量或数据框,返回唯一值
table(x):返回一个由x不同值个数组成的表格(通常用于整数或因子),即频数表
subset(x,…):根据条件(…选取x中元素,如x$V1<10);如果x为数据框,选项select使用负号给出保留 或去除的变量 subset(x, subset, select, drop = FALSE, …)
sample(x,size):不放回的随即在向量x中抽取size个元素,选项replace=TRUE允许放回抽取
prop.table(x,margin=):根据margin使用分数表示表格,wumargin时,所有元素和为1
2.其他函数
1)Reduce(f, x, …)或Reduce(x, f, …)
对x的第一、二两个元素运行函数f,得到的结果与第三个元素再运行函数f,以此类推,最后将x的所有元素整合到一起;x为向量(可以是原子向量,也可以是list)。
例如:
a=1:10; b=5:15; c=8:20
(1.使用reduce函数)
reduce(list(a,b,c),intersect)
输出:[1] 8 9 10
(2.使用嵌套的形式来求多个向量的交集)
intersect(intersect(a,b),c)
输出:[1] 8 9 10
2)apply(array, margin, FUN, …)
在array上,沿margin方向,依次调用FUN。返回值为vector。
例如: col.sums <- apply(x, 2, sum)
lapply(list, FUN, …)
在list上逐个元素调用FUN。可以用于dataframe上,因为dataframe是一种特殊形式的list。
例如:
lst <- list(a=c(1:5), b=c(6:10))
lapply(lst, mean)
$a
[1] 3
$b
[1] 8
apply系列函数的基本作用是对数组(array,可以是多维)或者列表(list)按照元素或元素构成的子集合进行迭代,并将当前元素或子集合作为参数调用某个指定函数。详见R语言apply函数族笔记
3)ldply(.data, .fun = NULL, …)
ldply: Split list, apply function, and return results in a data frame。其中.data是list to be processed;.fun是function to apply to each piece。
三、R包
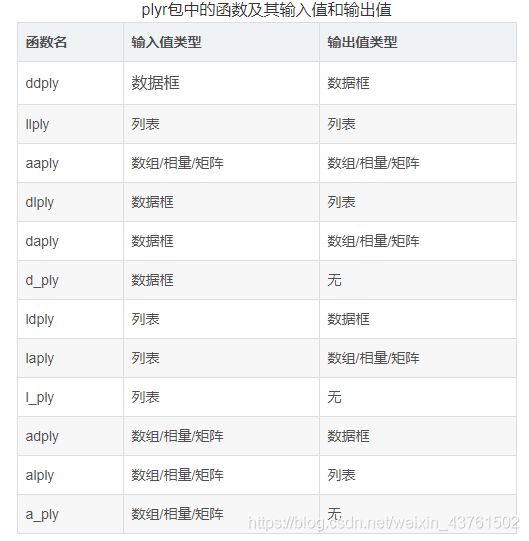
1.plyr包
plyr包中的所有的函数名均由五个字母组成且最后三个字母都为ply。函数名的第一个字母代表输入值的类型,第二个字母代表输出值的类型。图片来自R语言-plyr包中的函数
2.glmnet包

3.foreach包
多任务处理与并行运算包,支持在R语言中调用多进程功能的第三方包。
foreach包执行任务的核心理念与传统的apply组函数基本一致,都是与split – apply – combine一致的流程,优越之处在于可以通过调用操作系统的多核运行性能来执行并行任务,对于I/O密集型任务而言,可以大大节省代码执行效率。
foreach(…, #待输入的参数
.combine, #结果返回后执行的数据合并操作(c代表合并为向量,list代表合并为列表,rbind代表合并为数据框)
.packages=NULL, #在多进程共享的程序包(仅对于非系统安装包必备)
.export=NULL, #未在当前环境中定义的数据对象
.verbose=FALSE #是否打印运行信息
)
以上函数中,第1个参数是必备参数,即必须有输入参数,结果默认返回list。
任务的执行则需要使%do%或%dopar%分隔,前面为调用参数(上述代码块内容),后面为执行函数(自己定义)。
其中%do%执行的是普通的单进程任务(与apply组函数一样),%dopar%则可以执行多进程任务。