Flink简介、快速上手及部署
文章目录
-
-
- Flink简介
-
- Flink是什么
- 为什么要用Flink
- 传统数据架构
-
- 流处理的演变
-
- lambda架构
- 新的流式架构
- Flink的主要特点
- Flink的其他特点
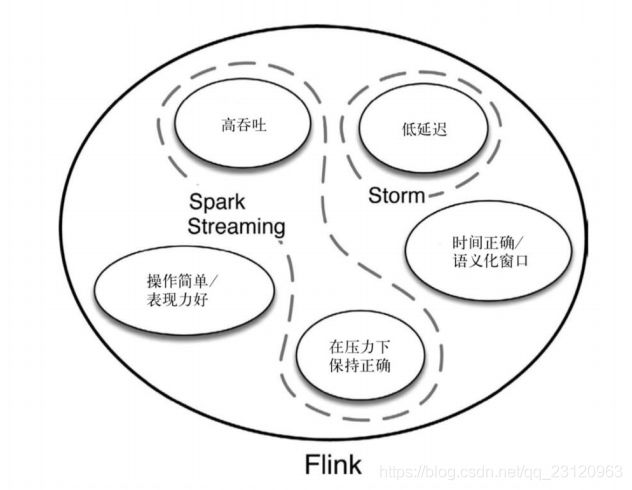
- Flink VS SparkStreaming
- Flink快速上手
-
- 批处理WordCount
- 流处理WordCount
- socket源流处理WordCount
- Flink部署
-
- Standalone模式
- Flink On Yarn模式
-
- Session-Cluster 模式
- Per Job Cluster 模式
- 参考网址
-
Flink简介
Flink是什么
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。

为什么要用Flink
传统的数据架构是基于有限数据集的。
流数据更真实地反映人们的生活方式。
我们更迫切地希望做到:低延迟 + 高吞吐 + 分布式(结果的正确性(确保乱序数据的顺序)、良好的容错性)。
由于分布式网络的关系,数据不一定是按序到达的,所以结果的正确性非常重要!
传统数据架构
- 事务处理
基于传统的关系型数据库

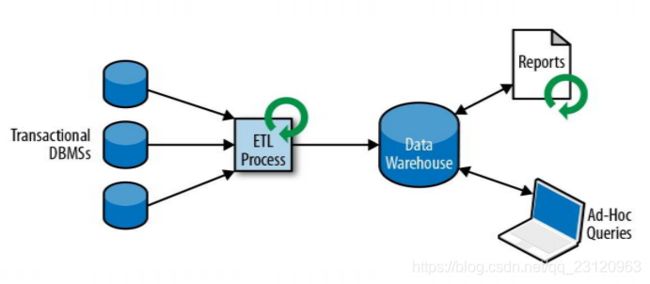
- 分析处理
将业务数据复制到数仓(Data Warehouse),再进行分析和查询
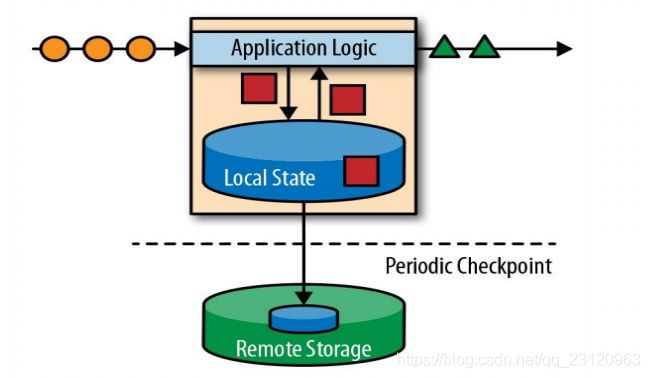
- 有状态的流式处理
任务的状态存放在本地内存中,并通过定期和异步地将本地状态持久化存储来保证故障场景下精确一次的状态一致性。
流处理的演变
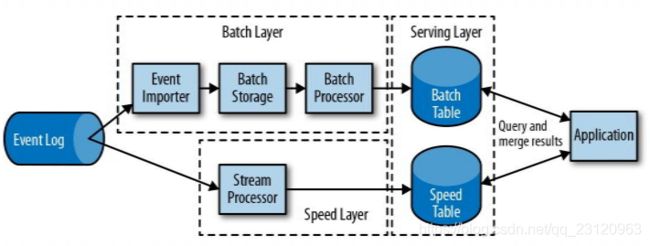
lambda架构
用两套系统,同时保证低延迟和结果准确
新的流式架构
Flink的主要特点
-
事件驱动(
Event-Driven)
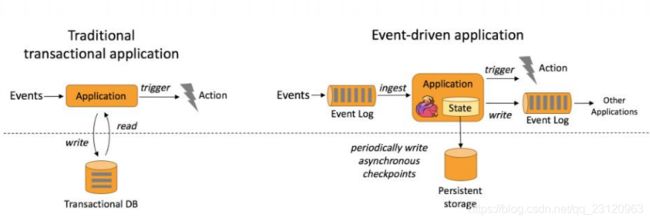
-
基于流的世界观
一切都是由流组成,离线数据是有界流,实时数据是无界流。
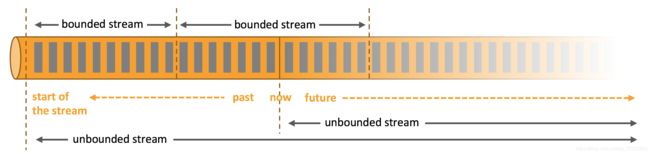
无界流:有定义流的开始,没有定义流的结束,无界流的数据必须持续处理,即数据摄入后必须立刻处理,不能等待所有数据到达再处理,因为输入是无限的。处理无界数据,通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。无界流:有定义流的开始和结束,有界流可以摄取所有数据后再计算。有界流所有数据可以排序,所以无需有序摄取,有界流处理通常被称为批处理。
-
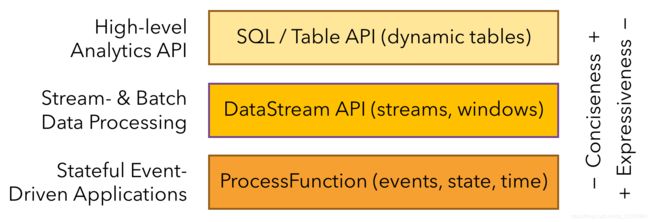
分层API
越顶层越抽象,表达含义越简明,使用越方便
越底层越具体,表达能力越丰富,使用越灵活
Flink的其他特点
- 支持事件时间(
event-time)和处理时间(processing-time)语义 - 精确一次(
exactly-once)的状态一致性保证 - 低延迟,毫秒级延迟
- 与众多常用存储系统连接
- 高可用,动态扩展,实现7*24小时全天候运行
Flink VS SparkStreaming
- 流(
stream)和微批(micro-batching)
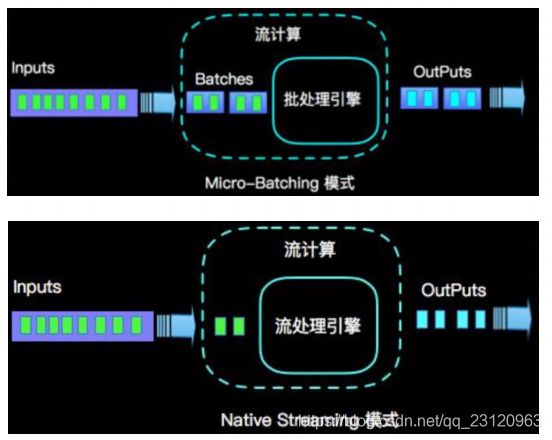
- 数据模型
- spark采用RDD模型,sparkStreaming的DStream实际上也就是一组组小批数据RDD的集合
- flink基本数据模型是数据流,以及事件(
event)序列
- 运行时架构
- spark是批计算,将DAG划分成不同的stage,一个完成后才可以计算下一个
- flink是标准的流执行模式,一个事件在一个节点处理完成以后可以直接发往下一个节点进行处理
Flink快速上手
批处理WordCount
- 依赖
<properties>
<flink.version>1.10.1flink.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>${flink.version}version>
dependency>
dependencies>
- 源码
package com.patrick.examples.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @ClassName WordCount
* @Description flink批处理WordCount例子
* @Author Administrator
* @Date 2021/3/11
* @Version 1.0
**/
public class WordCount {
public static void main(String[] args) throws Exception {
//创建批处理环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//读取文本数据
String fpath = "F:\\idea_workspace\\FlinkDemo\\src\\main\\resources\\hello.txt";
// DataSource dataSource = env.readTextFile(fpath);
// 从源码可知DataSource是DataSet的子类,所用的方法基本都是DataSet的方法
DataSet<String> inputDataSet = env.readTextFile(fpath);
// 统计数据
DataSet<Tuple2<String, Integer>> resultDataSet = inputDataSet.flatMap((String word, Collector<Tuple2<String, Integer>> out) -> {
String[] words = word.split("\\s+");
for (String w : words) {
out.collect(new Tuple2<String, Integer>(w, 1));
}
}) // 如果用lamda表达式则必须显示指定返回类型
.returns(Types.TUPLE(Types.STRING, Types.INT))
.groupBy(0).sum(1);
//打印数据
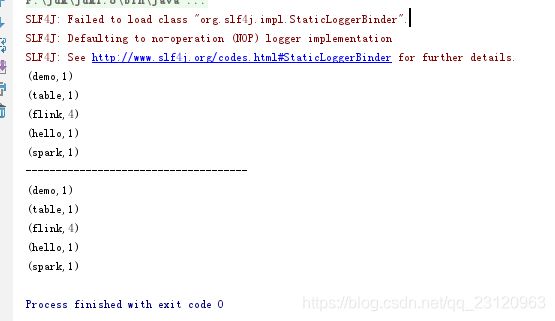
resultDataSet.print();
System.out.println("-------------------------------------");
// 用匿名类来替代 lambda 表达式
DataSet<Tuple2<String, Integer>> sum = inputDataSet.flatMap(new MyFlatMapper()).groupBy(0).sum(1);
//打印数据
sum.print();
}
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split("\\s+");
for (String w : words) {
out.collect(new Tuple2<String, Integer>(w, 1));
}
}
}
}
- 运行结果如下
流处理WordCount
- 源码
package com.patrick.examples.wc;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @ClassName StreamWordCount
* @Description flink流处理WordCount例子
* @Author Administrator
* @Date 2021/3/11
* @Version 1.0
**/
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 创建流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度, 开发环境下不设置默认是当前电脑核数
env.setParallelism(8);
//读取文本数据
String fpath = "F:\\idea_workspace\\FlinkDemo\\src\\main\\resources\\hello.txt";
// 从源码可知DataStreamSource是DataStream的子类,所用的方法基本都是DataStream的方法
DataStream<String> dataStream = env.readTextFile(fpath);
// 统计数据
// 注意流处理的数据处理模型是事件,来一个处理一个
DataStream<Tuple2<String, Integer>> resultDataStream = dataStream.flatMap(new WordCount.MyFlatMapper())
// 批处理API分组是groupBy 因为批处理是数据集已经到了所有用groupBy
// 流处理API分组是keyBy 因为流处理是来一个处理一个,是根据当前事件的某个字段进行分组的
.keyBy(0)
.sum(1);
// 打印数据
// 注意这里不是真正的触发打印动作
resultDataStream.print();
// 执行任务
// 上面的代码只是定义了流处理的具体步骤,真正的执行需要下面的代码执行上面的流任务
env.execute();
}
}
- 运行结果如下
每次遇到一个事件就打印一次,这就是流处理的状态计算,而不是批处理的只打印一次统计数据。

socket源流处理WordCount
- 服务器启动Socket服务
# 在本机启动socket服务
nc -lk 6666
- 程序启动参数
--host localhost --port 6666
- 源代码
package com.patrick.examples.wc;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @ClassName SocketStreamWordCount
* @Description 以socket作为输入源的 flink流处理WordCount例子
* @Author Administrator
* @Date 2021/3/12
* @Version 1.0
**/
public class SocketStreamWordCount {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(3);
// 使用Flink自带的工具类ParameterTool从任务启动参数获取配置项
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
// 定义socket数据源
DataStream<String> dataStream = env.socketTextStream(host, port);
// 统计数据
DataStream<Tuple2<String, Integer>> resultDataStream = dataStream.flatMap(new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
// 打印数据
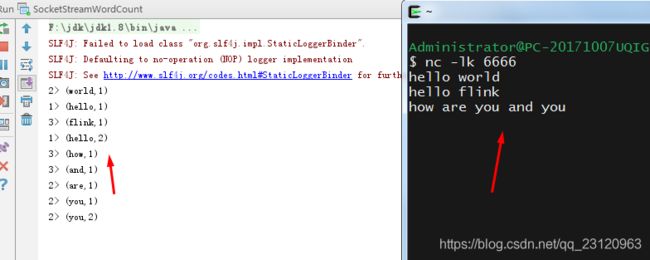
resultDataStream.print();
// 执行任务
env.execute();
}
}
- 运行结果
Flink部署
Standalone模式
从华为镜像网站下载flink-1.10.3-bin-scala_2.12.tgz
解压并建立软连接的步骤就不详细说明。

这里有三台机器:master、slave1、slave2
进入目录${FLINK_HOME}/conf,修改配置文件
- flink-conf.yaml
jobmanager.rpc.address: master
taskmanager.numberOfTaskSlots: 2
- masters
master:8081
- slaves
slave1
slave2
配置文件修改完后分发文件夹flink-1.10.3到slave1、slave2
在master机器启动flink集群
cd /usr/local/src/flink/bin
# 启动集群
./start-cluster.sh
将上面的socket源流处理WordCount达成Jar包后上传到Flink集群运行
# -c 指定入口类 -d 表示提交成功后退出客户端
/usr/local/src/flink/bin/flink run -c com.patrick.examples.wc.SocketStreamWordCount -d FlinkDemo-1.0-SNAPSHOT.jar --host master --port 6666
Flink作业占用多少Slot和它最大并行度的算子有关。
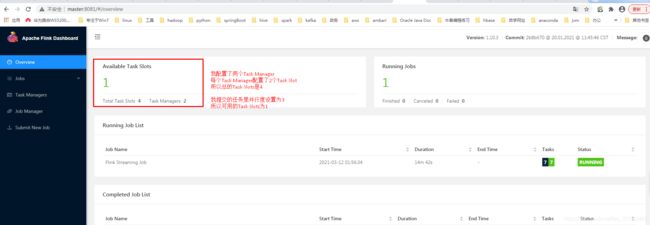
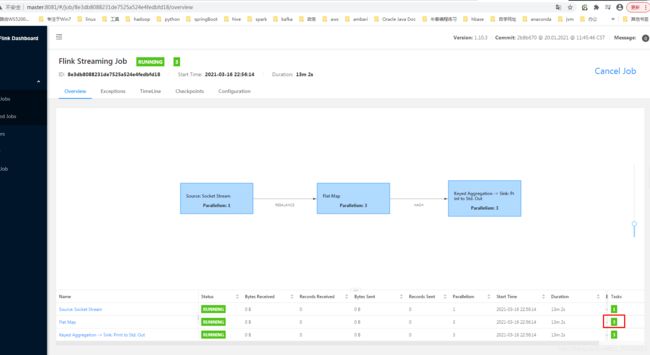
此时的运行结果就打印在Task Manager的标准输出里
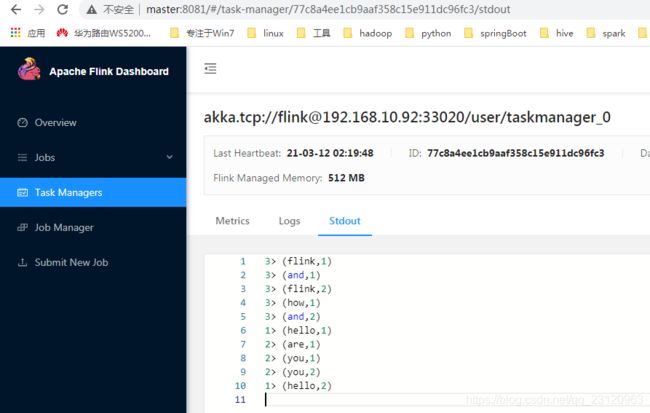
Flink On Yarn模式
Session-Cluster 模式

如上图,官方叫作start-a-long-running-flink-cluster-on-yarn,Session-Cluster模式需要先启动集群向YARN申请资源,然后再提交作业。以前可以通过yarn-session.sh -n指定TaskManager的数量,-s指定每个TaskManager的slot数目,也就是以前申请的资源是固定的。但是现在1.10版本后不用通过-n指定TaskManager的数量了,直接提交作业即可,资源会动态申请分配,作业完成之后,资源也会被YARN回收。
申请的Flink集群会在YARN集群中以Application的形式存在,
./bin/yarn-session.sh有如下重要参数,更详细的可以通过./bin/yarn-session.sh -h查看
-s 指定每个TaskManager的slot数目, 建议为机器的CPU数
-jm 指定JobManager的堆内存
-tm 指定TaskManager的堆内存
-d 分离模式
-nm 指定YARN上的Application名字
启动命令
./yarn-session.sh -s 3 -jm 1024 -tm 1024 -nm YARN-SESSION-FLINK -d
停止命令
# 优雅地停止
echo "stop" | ./bin/yarn-session.sh -id application_1615908453229_0002
# 稍微粗暴
yarn application -kill application_1615908453229_0002
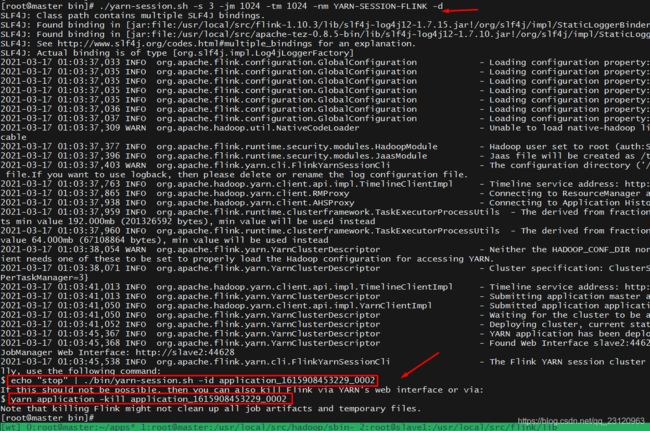
提交任务的命令还是一样的,-p可以指定并行度
/usr/local/src/flink/bin/flink run -p 3 -c com.patrick.examples.wc.SocketStreamWordCount -d FlinkDemo-1.0-SNAPSHOT.jar --host master --port 6666

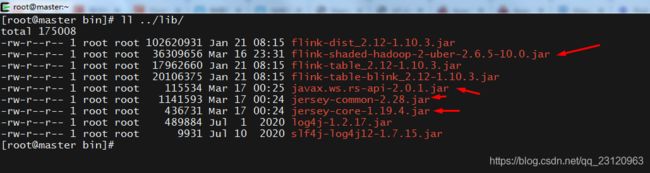
中间发生了ClassNotFound的问题,也就是Jar包找不到,需要将下面4个Jar包放到${FLINK_HOME}/lib目录下
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-shaded-hadoop-2-uberartifactId>
<version>2.6.5-10.0version>
dependency>
<dependency>
<groupId>com.sun.jerseygroupId>
<artifactId>jersey-coreartifactId>
<version>1.19.4version>
dependency>
<dependency>
<groupId>org.glassfish.jersey.coregroupId>
<artifactId>jersey-commonartifactId>
<version>2.28version>
dependency>
<dependency>
<groupId>javax.ws.rsgroupId>
<artifactId>javax.ws.rs-apiartifactId>
<version>2.0.1version>
dependency>
Per Job Cluster 模式
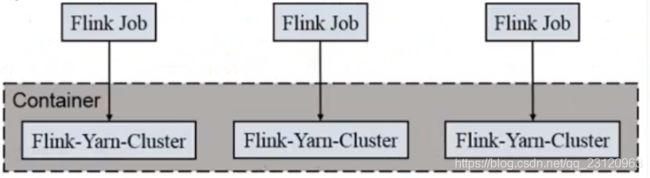
如上图,一个Job会对应一个集群每提交一个作业会根据自身的情况都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业,生产上建议使用这种模式。
启动命令
/usr/local/src/flink/bin/flink run -m yarn-cluster -p 3 -c com.patrick.examples.wc.SocketStreamWordCount -d FlinkDemo-1.0-SNAPSHOT.jar --host master --port 6666
停止命令下图也展示了
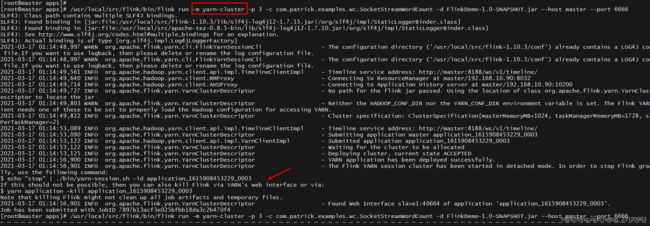
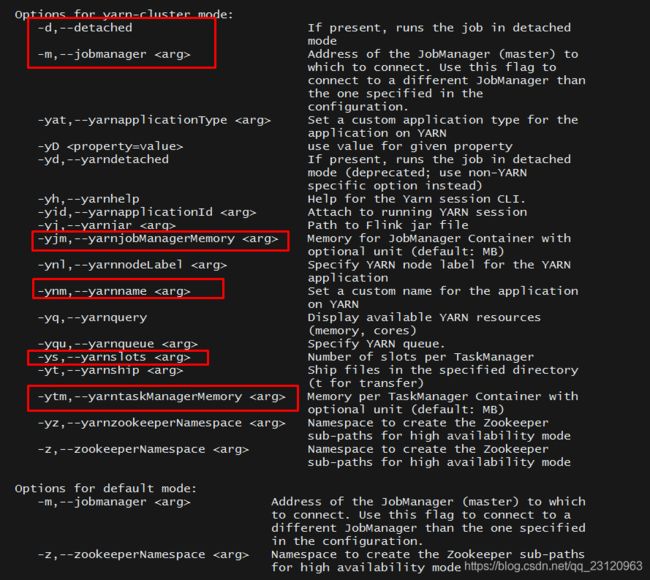
flink run更详细的参数请参考flink run -h
参考网址
解决Flink代码用Lambda表达式运行时报错“函数返回类型无法正确检测”
解决Flink on yarn模式下Class Not Found问题