Python+爬虫+反爬破解策略实战
我们经常会写一
些网络爬虫,想必大家都会有一个感受,写爬虫虽然不难,但是反爬处理却很难,因为现在大部分的网站都有自己的反爬机制,所以我们要爬取这些数据会比较难。但是,每一种反爬机制其实我们都会有相应的解决方案,作为爬虫方的我们,重点需要处理这些反爬机制,所以,今天我们在这里就为大家分析常见的反爬策略以及破解的手段。
1. 知己知彼-常见的反爬策略有哪些?
首先,既然要破解这些常见的反爬策略,就首先需要知道常见的反爬策略有哪些,所谓知己知彼,百战百胜。
常见的反爬策略主要有这些:
A. 有些网站会通过用户代理对爬虫进行限制,只要不是浏览器访问或者一直都是某个浏览器访问,那么就限制该用户不能对网站进行访问;
遇到这种情况,我们一般会采用用户代理池的方式进行解决,我们将在2中进行详细讲解。
B. 还有些网站会通过用户访问站点时的ip进行限制,比如某一个ip在短时间内大量的访问该网站上的网页,则封掉该ip,封掉之后使用该IP就无法访问该站点了;
如果遇到这种情况,我们一般会通过IP代理池的方式进行解决,难点在于如何找到可靠的代理IP并构建好IP代理池,我们将在3中进行详细讲解。
C. 除此之外,有的网站会通过验证码对用户的访问请求进行限制,比如当一个用户多次访问该站点之后,会出现验证码,输入验证码之后才可以继续访问,而怎么样让爬虫自动的识别验证码是一个关键问题;
如果遇到验证码从而阻挡了爬虫的运行,我们可以使用验证码自动识别的方式去处理验证码,我们将在4中进行详细讲解。
D. 还有的网站会通过数据屏蔽的方式进行反爬,比如用户访问时出现的数据并不会出现在源码中,此时这些数据会隐藏在js文件中,以此避免爬虫对这些数据的抓取。 如果遇到这种情况,我们一般会采用抓包分析去找到被屏蔽的数据,并自动获取。我们将在5中进行详细讲解。
2. 解决UA限制-浏览器伪装与用户代理池构建实战
我们先来为大家讲解如何解决UA限制。刚才已经提到,我们可以采用用户代理池构建的方式来解决这个问题。有新朋友可能会问,为什么采用用户代理就能够解决UA限制呢? 原理是这样的,我们不妨打开任意一个网页并按F12调用调试工具,然后在传递的数据中会发现头信息中有如下所示的一项信息:
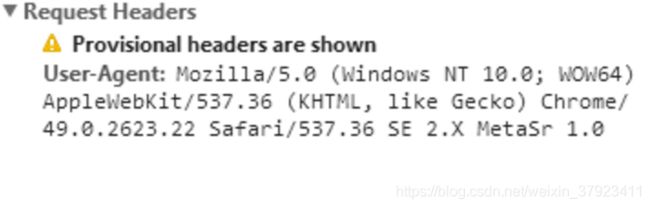
这一项字段为User-Agent,也就是我们俗称的用户代理(UA),对方服务器就是通过这一项字段的内容来识别我们访问的终端是什么的。不同浏览器的User-Agent的值是不一样的,我们可以使用不同浏览器的User-Agent的值构建为一个池子,然后每次访问都随机调用该池子中的一个UA,这样,也就意味着我们每次访问都使用的是不同的浏览器,这样的话,对方的服务器就很难通过用户代理来识别我们是否是爬虫了。
那么用户代理池应该怎么构建呢?我们以Scrapy爬虫为案例进行讲解。
在Scrapy里面,如果我们需要使用用户代理池,就需要使用下载中间件,所谓下载中间件,就是处于爬虫和从互联网中下载网页中间的一个部件。
首先我们在爬虫项目中建立一个文件作为下载中间件,名字随意,只需要在设置文件中设置为对应的即可。比如在此,我们建立了一个名为“downloader_middlerwares.py”的文件,如下所示:
然后在该文件中写入如下代码:
import random
from qna.settings import UAPOOLS
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
class Uagt(UserAgentMiddleware):
def __init__(self,ua=''):
self.user_agent = ua
def process_request(self,request,spider):
thisua=random.choice(UAPOOLS)
self.user_agent=thisua
print("当前使用的用户代理是:"+thisua)
request.headers.setdefault('User-Agent',thisua)
上述代码中,基本意思为:首先导入对应需要的模块,其中UAPOOLS是在设置文件中设置的用户代理池中各用户代理(我们稍后再设置),然后导入用户代理对应的中间件类UserAgentMiddleware,然后建立一个自定义类并继承该用户代理中间件类,在主方法process_request中,我们首先从UAPOOLS中随机选择一个用户代理,然后通过self.user_agent=thisua设置好对应的用户代理,并通过request.headers.setdefault(‘User-Agent’,thisua)在头文件中添加上该用户代理,那么在每次网站的时候,都会随机的从用户代理池中选择一个用户代理,并以该用户代理进行访问,这个时候,对方服务器就会认为我们每次访问都是不同的浏览器。
然后,我们需要在设置文件中构建用户代理池,如下所示:
UAPOOLS=["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Windows NT 6.1; rv:49.0) Gecko/20100101 Firefox/49.0",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
]
当然我们也可以在用户代理池中添加更多用户代理,构建好用户代理池之后,我们需要在设置文件中开启刚才设置的对应的中间件,如下所示:
DOWNLOADER_MIDDLEWARES = {
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 124,
'qna.downloader_middlerwares.Uagt': 125,
}
这样,对应的用户代理其就会生效,我们运行之后如下所示,可以看到,只采用了如下所示的用户代理进行爬取。

3. 解决IP限制-构建稳定可靠的IP代理池
接下来我们为大家讲解如何解决IP限制。
我们知道,在访问对方网站的时候,有时对方网站会通过我们的ip信息对我们进行识别,如果频繁访问的话很可能会把我们这个ip封掉。我们在使用爬虫自动的抓取大量信息的时候,通常都会由于访问过于频繁被禁掉ip,当然有些朋友会采用拨号的方式来切换本机电脑的ip,但始终是治标不治本。
此时我们可以通过代理ip池解决。我们知道,使用某一个代理ip去访问一个网站,在该网站的服务器中看到的ip就是对应的代理ip,所以当我们本机的ip被禁之后,我们使用代理ip去访问该网站就可以访问,但是如果只有一个代理ip,那么很可能代理ip也被禁掉。
此时,我们可以使用多个代理ip组建成一个池子,每次访问都从该池子中随机选择一个ip出来进行访问,那么这样,对方服务器就很难通过IP限制的方式对我们进行屏蔽了。那么代理ip应该怎么找呢?我们可以直接通过下面代码中的对应地址去申请代理ip。
其次,在实践中我们研究发现,国外的代理ip有效的程度会更高,所以我们待会会使用国外的代理ip进行实验,同时也建议各位朋友使用国外的代理ip构建代理ip池。那么我们怎么构建代理ip池呢?我们可以这样做:
首先,建立一个下载中间件(各用户代理池构建时所创建的中间件类似,名字同样自定义),在此我们创建的下载中间件文件如下所示:
然后在该中间件中编写如下程序:
import urllib.request
from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware
IPPOOLS=urllib.request.urlopen("http://tpv.daxiangdaili.com/ip/?tid=559126871522487&num=1&foreign=only").read().decode("utf-8","ignore")
class Ippl(HttpProxyMiddleware):
def __init__(self, ip=''):
self.ip=ip
def process_request(self, request,spider):
print("当前使用的代理IP是:"+str(IPPOOLS))
request.meta["proxy"] = "http://" + str(IPPOOLS)
在该程序中,我们使用daxiangdaili.com提供的代理ip,foreign=only代表只是用国外的代理ip,因为在实践中得出的经验是国外的代理ip有效的可能性会比较高,我们每次都从该接口中获取一个代理ip,然后通过request.meta[“proxy”] = “http://” + str(IPPOOLS)将该代理ip添加到meta中,此时该代理ip生效。
然后,我们还需要在设置文件中开启该下载中间件,如下所示:
DOWNLOADER_MIDDLEWARES = {
'qna.downloader_middlerwares.Ippl': 121,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':123,
}
随后,我们可以运行对应爬虫,结果如下所示:

可以看到此时使用代理ip:107.170.26.74:8088对网站进行爬取。
4. 解决验证码限制-验证码三种处理手段及实战讲解
接下来我们为大家讲解,如何解决验证码限制。
我们使用爬虫爬取一些网站的时候,经常会遇到验证码,那么遇到验证码之后应该怎么处理呢? 一般来说,遇到验证码时,处理思路有三种:
半自动识别
通过接口自动识别
通过机器学习等知识自动识别
由于第三种方法涉及AI领域的新知识,所以第三种方法在此不具体讲解(我也不会),在此,我们主要会为大家讲解如何使用前两种方式去处理验证码。
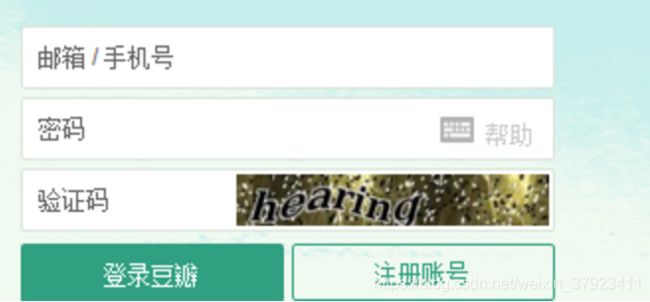
首先为大家讲解如何通过半自动识别的方式去处理验证码,我们以豆瓣登陆爬虫为例进行讲解。比如,在登录豆瓣时,我们经常会遇到如下所示的验证码:
那么此时如果通过半自动处理的方式来做,我们可以这样:
先爬一遍登录页,然后得到验证码图片所在的网址,并将该验证码图片下载到本地,然后等待输入,此时我们可以在本地查看该验证码图片,并输入对应的验证码,然后就可以自动登录。
通过半自动处理的方式登录豆瓣网站,完整代码如下所示,关键部分一给出注释,关键点就在于找到验证码图片所在的地址并下载到本地,然后等待我们手动输入并将输入结果传递给豆瓣服务器。
import ssl
import os
import scrapy
import urllib.request
from scrapy.http import Request,FormRequest
ssl._create_default_https_context=ssl._create_unverified_context
class LoginspdSpider(scrapy.Spider):
name = "loginspd"
allowed_domains = ["douban.com"]
#设置头信息变量,供下面的代码中模拟成浏览器爬取
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0"}
#编写start_requests()方法,第一次会默认调取该方法中的请求
def start_requests(self):
#首先爬一次登录页,然后进入回调函数parse()
return [Request("https://accounts.douban.com/login", meta={
"cookiejar": 1}, callback=self.parse)]
def parse(self, response):
#获取验证码图片所在地址,获取后赋给captcha变量,此时captcha为一个列表
captcha=response.xpath('//img[@id="captcha_image"]/@src').extract()
#因为登录时有时网页有验证码,有时网页没有验证码
# 所以需要判断此时是否需要输入验证码,若captcha列表中有元素,说明有验证码信息
if len(captcha)>0:
print("此时有验证码")
#设置将验证码图片存储到本地的本地地址
localpath="D:/我的教学/Python/CSDN-Python爬虫/captcha.png"
#将服务器中的验证码图片存储到本地,供我们在本地直接进行查看
urllib.request.urlretrieve(captcha[0], filename=localpath)
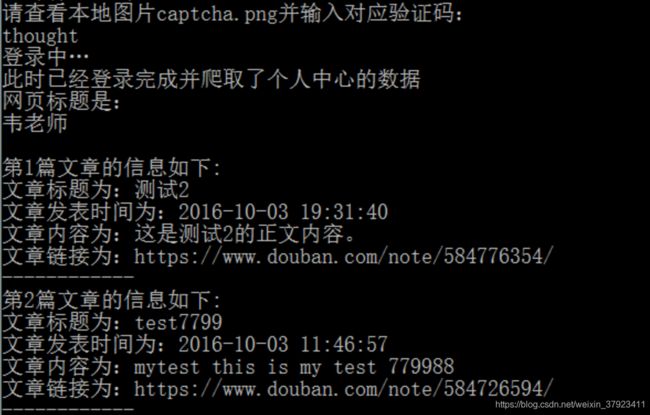
print("请查看本地图片captcha.png并输入对应验证码:")
#通过input()等待我们输入对应的验证码并赋给captcha_value变量
captcha_value=input()
#设置要传递的post信息
data={
#设置登录账号,格式为账号字段名:具体账号
"form_email":"[email protected]",
#设置登录密码,格式为密码字段名:具体密码,读者需要将账号密码换成自己的
#因为笔者完成该项目后已经修改密码
"form_password":"weijc7789",
#设置验证码,格式为验证码字段名:具体验证码
"captcha-solution":captcha_value,
#设置需要转向的网址,由于我们需要爬取个人中心页,所以转向个人中心页
"redir":"https://www.douban.com/people/151968962/",
}
#否则说明captcha列表中没有元素,即此时不需要输入验证码信息
else:
print("此时没有验证码")
#设置要传递的post信息,此时没有验证码字段
data={
"form_email":"[email protected]",
"form_password":"weijc7789",
"redir": "https://www.douban.com/people/151968962/",
}
print("登录中…")
#通过FormRequest.from_response()进行登陆
return [FormRequest.from_response(response,
#设置cookie信息
meta={
"cookiejar": response.meta["cookiejar"]},
#设置headers信息模拟成浏览器
headers=self.header,
#设置post表单中的数据
formdata=data,
#设置回调函数,此时回调函数为next()
callback=self.next,
)]
def next(self,response):
print("此时已经登录完成并爬取了个人中心的数据")
#此时response为个人中心网页中的数据
#以下通过Xpath表达式分别提取个人中心中该用户的相关信息
#网页标题Xpath表达式
xtitle="/html/head/title/text()"
#日记标题Xpath表达式
xnotetitle="//div[@class='note-header pl2']/a/@title"
#日记发表时间Xpath表达式
xnotetime="//div[@class='note-header pl2']//span[@class='pl']/text()"
#日记内容Xpath表达式
xnotecontent="//div[@class='note']/text()"
#日记链接Xpath表达式
xnoteurl="//div[@class='note-header pl2']/a/@href"
#分别提取网页标题、日记标题、日记发表时间、日记内容、日记链接
title=response.xpath(xtitle).extract()
notetitle = response.xpath(xnotetitle).extract()
notetime = response.xpath(xnotetime).extract()
notecontent = response.xpath(xnotecontent).extract()
noteurl = response.xpath(xnoteurl).extract()
print("网页标题是:"+title[0])
#可能有多篇日记,通过for循环依次遍历
for i in range(0,len(notetitle)):
print("第"+str(i+1)+"篇文章的信息如下:")
print("文章标题为:"+notetitle[i])
print("文章发表时间为:" + notetime[i])
print("文章内容为:" + notecontent[i])
print("文章链接为:" + noteurl[i])
print("------------")
然后我们可以运行该程序,如下所示:

可以看到,此时会提示我们输入验证码,我们在本地可以看到验证码如下所示:

随后我们输入该验证码,然后按回车键,此时便可正常登陆,如下所示:
自动识别:
显然,通过半自动的处理方式不足以处理验证码,此时,我们可以通过接口的方式,自动的识别验证码并进行处理,这样就完全自动化操作了。
具体方式如下,首先我们在云打码注册一个账号并申请对应接口,然后将程序验证码处理部分做以下修改:
cmd=“D:/python27/python D:/python27/yzm/YDMPythonDemo.py”
r = os.popen(cmd)
captcha_value = r.read()
r.close()
print(“此时已经自动处理验证码完毕!处理的验证码结果为:”+str(captcha_value))
然后运行该程序,结果如下所示:
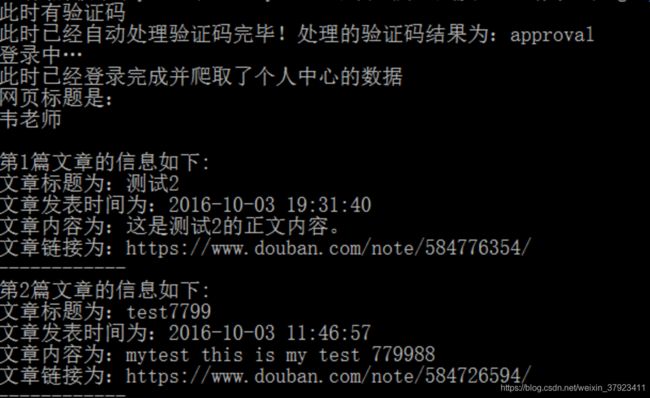
可以看到,事实已经能够自动的识别验证码并能够成功登陆。
接口自动处理验证码的完整代码如下所示:
# -*- coding: utf-8 -*-
import ssl
import os
import scrapy
import urllib.request
from scrapy.http import Request,FormRequest
ssl._create_default_https_context=ssl._create_unverified_context
class LoginspdSpider(scrapy.Spider):
name = "loginspd"
allowed_domains = ["douban.com"]
#设置头信息变量,供下面的代码中模拟成浏览器爬取
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0"}
#编写start_requests()方法,第一次会默认调取该方法中的请求
def start_requests(self):
#首先爬一次登录页,然后进入回调函数parse()
return [Request("https://accounts.douban.com/login", meta={
"cookiejar": 1}, callback=self.parse)]
def parse(self, response):
#获取验证码图片所在地址,获取后赋给captcha变量,此时captcha为一个列表
captcha=response.xpath('//img[@id="captcha_image"]/@src').extract()
#因为登录时有时网页有验证码,有时网页没有验证码
# 所以需要判断此时是否需要输入验证码,若captcha列表中有元素,说明有验证码信息
if len(captcha)>0:
print("此时有验证码")
#设置将验证码图片存储到本地的本地地址
localpath="D:/我的教学/Python/CSDN-Python爬虫/captcha.png"
#将服务器中的验证码图片存储到本地,供我们在本地直接进行查看
urllib.request.urlretrieve(captcha[0], filename=localpath)
'''
print("请查看本地图片captcha.png并输入对应验证码:")
#通过input()等待我们输入对应的验证码并赋给captcha_value变量
captcha_value=input()
'''
cmd="D:/python27/python D:/python27/yzm/YDMPythonDemo.py"
r = os.popen(cmd)
captcha_value = r.read()
r.close()
print("此时已经自动处理验证码完毕!处理的验证码结果为:"+str(captcha_value))
#设置要传递的post信息
data={
#设置登录账号,格式为账号字段名:具体账号
"form_email":"[email protected]",
#设置登录密码,格式为密码字段名:具体密码,读者需要将账号密码换成自己的
#因为笔者完成该项目后已经修改密码
"form_password":"weijc7789",
#设置验证码,格式为验证码字段名:具体验证码
"captcha-solution":captcha_value,
#设置需要转向的网址,由于我们需要爬取个人中心页,所以转向个人中心页
"redir":"https://www.douban.com/people/151968962/",
}
#否则说明captcha列表中没有元素,即此时不需要输入验证码信息
else:
print("此时没有验证码")
#设置要传递的post信息,此时没有验证码字段
data={
"form_email":"[email protected]",
"form_password":"weijc7789",
"redir": "https://www.douban.com/people/151968962/",
}
print("登录中…")
#通过FormRequest.from_response()进行登陆
return [FormRequest.from_response(response,
#设置cookie信息
meta={
"cookiejar": response.meta["cookiejar"]},
#设置headers信息模拟成浏览器
headers=self.header,
#设置post表单中的数据
formdata=data,
#设置回调函数,此时回调函数为next()
callback=self.next,
)]
def next(self, response):
print("此时已经登录完成并爬取了个人中心的数据")
#此时response为个人中心网页中的数据
#以下通过Xpath表达式分别提取个人中心中该用户的相关信息
#网页标题Xpath表达式
xtitle="/html/head/title/text()"
#日记标题Xpath表达式
xnotetitle="//div[@class='note-header pl2']/a/@title"
#日记发表时间Xpath表达式
xnotetime="//div[@class='note-header pl2']//span[@class='pl']/text()"
#日记内容Xpath表达式
xnotecontent="//div[@class='note']/text()"
#日记链接Xpath表达式
xnoteurl="//div[@class='note-header pl2']/a/@href"
#分别提取网页标题、日记标题、日记发表时间、日记内容、日记链接
title=response.xpath(xtitle).extract()
notetitle = response.xpath(xnotetitle).extract()
notetime = response.xpath(xnotetime).extract()
notecontent = response.xpath(xnotecontent).extract()
noteurl = response.xpath(xnoteurl).extract()
print("网页标题是:"+title[0])
#可能有多篇日记,通过for循环依次遍历
for i in range(0,len(notetitle)):
print("第"+str(i+1)+"篇文章的信息如下:")
print("文章标题为:"+notetitle[i])
print("文章发表时间为:" + notetime[i])
print("文章内容为:" + notecontent[i])
print("文章链接为:" + noteurl[i])
print("------------")
上述代码中关键部分已给出注释。
5. 解决屏蔽数据问题-抓包分析及异步数据加载分析实战(解决JS\Ajax等隐藏数据获取问题)
除此之外,有些网站还会通过数据屏蔽的方式进行反爬。如果是通过这种方式尽反爬,我们可以使用Fiddler进行抓包,分析出数据所在的真实地址,然后直接爬取该数据即可。
当然,Fiddler默认是不能抓取HTTPS协议的,如果要抓取HTTPS协议,需要进行如下设置:
打开Fiddler,点击“Tools–Fiddler Options–HTTPS”,把下方的全勾上,如下图所示:
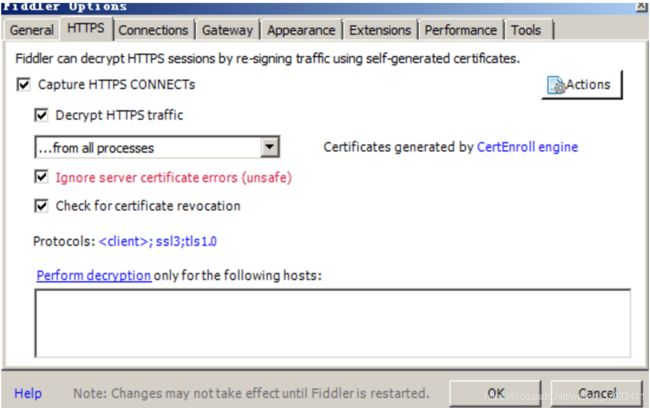
然后,点击Action,选择将CA证书导入到桌面,即第二项,导出后,点击上图的ok保存配置。
然后在桌面上就有了导出的证书,如下所示:

随后,我们可以在浏览器中导入该证书。我们打开火狐浏览器,打开“选项–高级–证书–导入”,选择桌面上的证书,导入即可。随后,Fiddler就可以抓HTTPS协议的网页了。如下图所示。
能够抓取HTTPS的数据之后,我们便可以对大多数网站进行抓包分析。
由于抓包分析的内容比较多,所以我们为大家配了配套视频进行讲解,配套视频中讲解了如何解决淘宝网站商品数据的屏蔽问题。
6. 其他反爬策略及应对思路
我们使用上面几种反爬处理的方式,基本上可以应付大多数网站了。当然,有些网站的数据所在地址是随机生成的,根本没有规律可循,如果遇到这种情况,我们采用PhantomJS将对应的地址获取到,再交给爬虫处理即可。
随着时代的发展,也会出现越来越多的反爬方式,我们掌握了这些基础之后,在遇到新的反爬方式的时候,稍微研究便可以处理了。