PixPro是第一个通过像素级对比学习来进行特征表示学习
上图是整个算法流程图,接下来进行详细解析
前向传播
input是输入图像,维度尺寸是(b, c, h, w)
augmentation:通过对同一张input进行随机大小、位置裁剪并缩放到统一大小224*224,并基于一定概率下进行随机水平翻转、color distortion、高斯模糊和solarization操作,最后生成两张不同视图view #1和view #2,大小都是(b, c, 224, 224)
backbone+projection:view #1和view #2分别送入两个网络分支,上下两分支中都含有相同结构的backbone+projection模块,其中backbone模块使用了Resnet,输出最后一层特征图,大小为(b, c1, 7, 7)。
projection模块是一个conv1*1+BN+Relu+conv1*1结构,先进行升维,再降维到256大小,这样就得到了两个输出大小为(b, 256, 7, 7)的特征$x$和$x^{,}$,projection模块代码如下:
class MLP2d(nn.Module):
def __init__(self, in_dim, inner_dim=4096, out_dim=256):
super(MLP2d, self).__init__()
self.linear1 = conv1x1(in_dim, inner_dim)
self.bn1 = nn.BatchNorm2d(inner_dim)
self.relu1 = nn.ReLU(inplace=True)
self.linear2 = conv1x1(inner_dim, out_dim)
def forward(self, x):
x = self.linear1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.linear2(x)
return x
def conv1x1(in_planes, out_planes):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=True)
PPM:是一个自注意力模块,针对(b, 256, 7, 7)的输入特征图$x$

首先根据cosine相似度计算出attention图,大小为(b, 49, 49),表示每个特征点与其他特征点的相似度。再对输入特征图进行特征融合,得到输出大小为(b, 256, 7, 7)的特征图$y$,PPM代码如下:
def featprop(self, feat):
N, C, H, W = feat.shape
# Value transformation
feat_value = self.value_transform(feat) # 1*1卷积操作
feat_value = F.normalize(feat_value, dim=1)
feat_value = feat_value.view(N, C, -1)
# Similarity calculation
feat = F.normalize(feat, dim=1)
# [N, C, H * W]
feat = feat.view(N, C, -1)
# [N, H * W, H * W]
attention = torch.bmm(feat.transpose(1, 2), feat)
attention = torch.clamp(attention, min=self.pixpro_clamp_value)
if self.pixpro_p < 1.:
attention = attention + 1e-6
attention = attention ** self.pixpro_p # pixpro_p控制注意力的范围,默认为1
# [N, C, H * W]
feat = torch.bmm(feat_value, attention.transpose(1, 2))
return feat.view(N, C, H, W)
Loss:计算$x^,$和$y$之间的loss。$x^,$和$y$的空间位置示意图如下所示:

在数据增强augmentation过程中,可以获取裁剪图像的左上角和右下键坐标,由于输出特征图$x^,$和$y$大小为(b, 256, 7, 7),所以每个特征图中有7*7个特征点,根据插值法就可以获取输出特征图$x^,$和$y$的每个特征点的空间坐标,大小为(b, 2, 7, 7)。
首先计算出不同视图中每个特征点彼此之间的距离,可以得到大小为(b, 49, 49)的距离矩阵D,步骤如下:
- 特征图$x^{,}$的x坐标$X_{x^{,}}$:(b, 7, 7)->(b, 49, 1), y坐标$Y_{x^{,}}$:(b, 7, 7)->(b, 49, 1)
- 特征图$y$中x坐标$X_{y}$:(b, 7, 7)->(b, 1, 49), y坐标$Y_{y}$:(b, 7, 7)->(b, 1,49)
- 距离矩阵D=$\sqrt{(X_{x^{,}}-X_{y})^2+(Y_{x^{,}}-Y_{y})^2}/max\_bin$(max_bin是相邻特征点之间的最大距离,目的是为了"归一化")
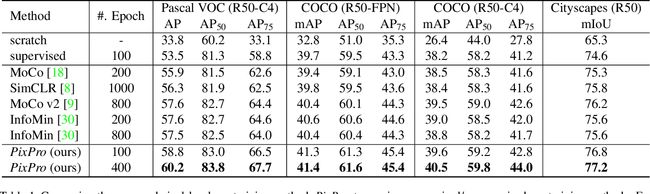
不同视图中距离较近的特征点特征应该具有一致性consistency,所以对距离特征D根据阈值ratio进行二分来获取距离较近的特征点掩码M=(D 再计算出$x^,$和$y$的特征相似度图logit,大小为(b, 49, 49),这步与PPM中计算注意力相似度类似 最后根据特征相似图和掩码矩阵计算loss: $loss = logit * M$ 整个loss计算完整过程的代码如下: 下分支网络不参与直接训练,其中所有的权重参数不具有梯度值。其参数$param\_k$更新方式是基于上分支网络参数$param\_q$动量更新。训练开始前,上下分支网络初始权重保持一致。 $$ param\_k.data = param\_k.data * momentum + param\_q.data * (1-momentum) $$ 其中,momentum是动量值,整个训练过程从0.99逐渐增大到1.0 优化器:LARS,weight_decay=1e-5 lr_scheduler:cosine, warmup total_batchsize:1024 world size:8 V100 GPUs 与其他基于实例级自监督算法在下游检测分割任务上的比较结果 不同超参数下的实验结果 PixPro和ProContrast结果比较 结合实例级模块的结果 有无FPN、head、实例级模块的实验比较结果def regression_loss(q, k, coord_q, coord_k, pos_ratio=0.5):
""" q, k: N * C * H * W
coord_q, coord_k: N * 4 (x_upper_left, y_upper_left, x_lower_right, y_lower_right)
"""
N, C, H, W = q.shape
# [bs, feat_dim, 49]
q = q.view(N, C, -1)
k = k.view(N, C, -1)
# generate center_coord, width, height
# [1, 7, 7]
x_array = torch.arange(0., float(W), dtype=coord_q.dtype, device=coord_q.device).view(1, 1, -1).repeat(1, H, 1)
y_array = torch.arange(0., float(H), dtype=coord_q.dtype, device=coord_q.device).view(1, -1, 1).repeat(1, 1, W)
# [bs, 1, 1]
q_bin_width = ((coord_q[:, 2] - coord_q[:, 0]) / W).view(-1, 1, 1)
q_bin_height = ((coord_q[:, 3] - coord_q[:, 1]) / H).view(-1, 1, 1)
k_bin_width = ((coord_k[:, 2] - coord_k[:, 0]) / W).view(-1, 1, 1)
k_bin_height = ((coord_k[:, 3] - coord_k[:, 1]) / H).view(-1, 1, 1)
# [bs, 1, 1]
q_start_x = coord_q[:, 0].view(-1, 1, 1)
q_start_y = coord_q[:, 1].view(-1, 1, 1)
k_start_x = coord_k[:, 0].view(-1, 1, 1)
k_start_y = coord_k[:, 1].view(-1, 1, 1)
# [bs, 1, 1]
q_bin_diag = torch.sqrt(q_bin_width ** 2 + q_bin_height ** 2)
k_bin_diag = torch.sqrt(k_bin_width ** 2 + k_bin_height ** 2)
max_bin_diag = torch.max(q_bin_diag, k_bin_diag)
# [bs, 7, 7]
center_q_x = (x_array + 0.5) * q_bin_width + q_start_x
center_q_y = (y_array + 0.5) * q_bin_height + q_start_y
center_k_x = (x_array + 0.5) * k_bin_width + k_start_x
center_k_y = (y_array + 0.5) * k_bin_height + k_start_y
# [bs, 49, 49]
dist_center = torch.sqrt((center_q_x.view(-1, H * W, 1) - center_k_x.view(-1, 1, H * W)) ** 2
+ (center_q_y.view(-1, H * W, 1) - center_k_y.view(-1, 1, H * W)) ** 2) / max_bin_diag
pos_mask = (dist_center < pos_ratio).float().detach()
# [bs, 49, 49]
logit = torch.bmm(q.transpose(1, 2), k)
loss = (logit * pos_mask).sum(-1).sum(-1) / (pos_mask.sum(-1).sum(-1) + 1e-6)
return -2 * loss.mean()
反向传播
实验