目标检测与识别(R-CNN理解)
1. 两步走的目标检测: 先进行区域推荐,然后进行目标分类
常见算法 R-CNN, SPP-net, Fast R-CNN, Faster R-CNN
做法: 给找出候选的一些区域, 对区域传入网络进行分类
2. 端到端的目标检测: 采用一个网络一步到位
常见算法: YOLO算法, SSD算法
做法: 将图片输入到网络,直接输出图片中的物体以及位置。
目标检测的任务:
1.输入: 图片
2.输出: 物体类别和位置坐标
物体位置类型, x,y,w,h型。 x,y表示物体的中心位置, 以及中心点距离物体两边的长宽。
xmin,ymin,xmax,ymax表示物体的左上角和右下角的坐标,左上角坐标为(0,0),
训练网络步骤:
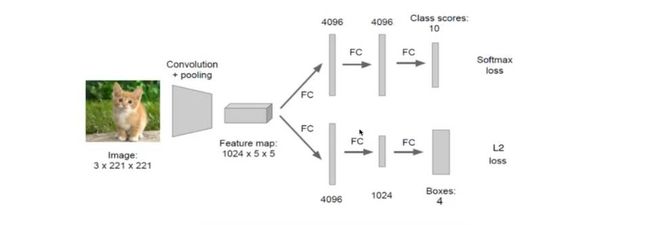
人为标记图片中的物体和物体的位置,之后将图片传入到下面的网络中,进入全连接层,会有两个全连接层,一个训练用于预测出物体类别(使用Softmax函数进行分类),一个训练用输出物体位置(使用均方误差损失函数训练输出位置)
滑动窗口:
对于图片中有多个物体时候,就不能固定个数输出物体的位置值,所以就有了滑动窗口。
滑动窗口: 目标检测的暴力方法是从左到右,从上到下滑动窗口,利用分类识别图片。为了在不同观察距离出检测的不同的目标类型,我们使用不同大小和宽高比的窗口,这样就变成每个子图输出类别及位置
但是设置固定大小的框有的物体刚好框住,有的框不住,如不能用一个横框作为一个高物体的窗口。解决办法是设置多个长宽不同的窗口进行滑动, 假设有k个窗口,每个窗口滑动m次,则总共k*m个图片输入CNN分类器中,我们使用一个分类器识别类 和 边框的先线性回归器
滑动窗口存在的问题:
这种方法类似一种暴力穷举的方式,会消耗大量计算力,并且由于窗口大小固定,可能会造成效果不准确。
R-CNN: (使用候选框)
步骤: (以AlexNet网络为基准)
1. 利用选择性搜索,在一张图片中提取出可能存在的目标候选区域,(如默认找2000个候选区域)
选择性搜索: 将每一个像素作为一组,计算每组纹理,并将两个最接近的组结合起来,
2.为了让每一个候选区域适合AlexNet网络,将所有的候选区域图片转换成227*227大小的图片,通过CNN提取特征向量,最终输出2000*4096维矩阵(2000表示有2000个框,4096表示一个候选框的特征向量)
3. 将2000*4096维特征经过分类器进行(20类别)分类,获得2000*20矩阵
4.对2000*20维矩阵做NMS(非极大值抑制),剔除一些不好的,得到剩下分数高的,结果好的候选框
非极大抑制:
目的: 筛选候选区域,目标是一个物体只保留一个最优的框,来抑制那些多余的候选框。
步骤: 迭代过程:
1.对2000个候选区域得分进行概率筛选, 0.5(得分小于0.5的框全部删除)
剩余的候选框,假设真实物体个数(图片中真实标记的物体个数)为2个(记作N), 筛选之后的候选框为5个(P),计算N中每个物体位置与P的交并比IOU, 得到P中每个候选框对应IoU最高的N中一个
如图,真实物体有2个, 候选框有5个, 用每个物体实际大小与所有候选框计算交并比(例如计算黑色车与A,B,C,D,E五个候选框的交并比,结果黑色与D的IoU=0, 再用白色车和A,B,C,D,E五个候选框做交并比,得到10个IoU值,保留Iou值比较高的,如计算得,A,C对黑色车的IoU值高,说明A,C是匹配黑色车的框, B,D,E对白色车的IoU值比较高,说明B,D,E是匹配白色车的框,这样,5个候选框都有了对应的匹配物体了,A,C对应黑色车,B,D,E对应白色车),保留IoU值最大的那个。

开始迭代,图中有两个物体,所以需要迭代两轮,
第一轮,对于白色车辆,假设B框得分(得分指的是真实物体与框的重合程度)最高,用剩余的D,E候选框分别与B候选框计算IoU值, 当与B候选框的IoU>0.5, 则删除候选框, 只保留B作为最终候选框。
当B与D的IoU>0.5, 说明B和D的框接近重合,所以可以删除D候选框。
第二轮,对于黑色车辆,操作与白色相同。
最终输出结果,理想状态,每一个物体都有一个候选框
SS算法(选择性搜索)得到的物体位置是固定的,但是我们筛选出的位置不一定真的就特别准确,需要A和B进行最后的修正。
5.修正候选框,对候选框做回归微调。
为了让候选框标注更加准确,去修正原来的位置。
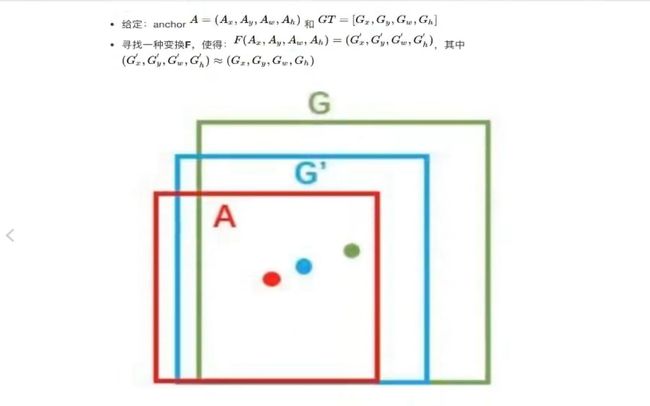
回归用于修正筛选后的候选区域,将每一个候选框与对应的真实物体的位置做一个线性回归。

线性回归: 其中A是候选框, G是物体真实的位置, G`是经过回归后得到的候选框,找到一种变换关系F()将候选框进行变换得到新的候选框位置G`, G`的位置更接近与真实位置G。
RCNN评估指标:
一, IoU交并比。
两个区域的面积的交集 除以 两个区域的并集。
交并比的值为0~1之间,越接近1,则重合度越高。

R-CNN总结。
1.输入图片。
2.默认选取2000个候选区域。
3.将得到的候选区域图片进行大小变换,得符合神经网络的维度。
4.经过卷积,得到特征向量,之后进入两个全连接层,一个用于分类,一个用于计算坐标值
R-CNN缺点:
训练阶段多,需要对SVM分类器 和 边框回归器分别进行训练,不能一起训练,
处理速度慢。
占用磁盘空间大, 5000张图像会产生几百G的特征文件