【深度学习基础】PyTorch实现DenseNet亲身实践
【深度学习基础】PyTorch实现DenseNet亲身实践
- 1 论文关键信息
-
- 1.1 密集连接
- 1.2 Dense Block
- 1.3 网络结构
- 1.4 实现细节
-
- 1.4.1 BN-ReLU-Conv
- 1.4.2 Transition layers
- 1.4.3 Bottleneck结构
- 1.4.4 初始的7x7卷积层
- 2 PyTorch实现
- 2.1 BN-ReLu-Conv
- 2.2 Dense Block
- 2.3 网络搭建并测试
代码已同步到GitHub:https://github.com/EasonCai-Dev/torch_backbones.git
1 论文关键信息
1.1 密集连接
论文通过公式描述了密集连接的思想,假设一个网络(block)具有 L L L层,每一层相当于一个非线性变化 H l ( . ) H_l(.) Hl(.),其中 l l l表示第 l l l层, H l ( . ) H_l(.) Hl(.)可以是BN,卷积,池化或者非线性激活单元,第 l l l层的特征输出为 x l x_l xl。
- 普通卷积
x l = H l ( x l − 1 ) x_l = H_l(x_{l-1}) xl=Hl(xl−1) - 残差结构
x l = H l ( x l − 1 ) + x l − 1 x_l = H_l(x_{l-1})+x_{l-1} xl=Hl(xl−1)+xl−1 - 密集连接
x l = H ( [ x 0 , x 1 , . . . , x l − 1 ) ] x_l = H([x_0, x_1, ..., x_{l-1})] xl=H([x0,x1,...,xl−1)]
也就是说, 密集连接将之前每一层的特征输出作为该成的输入,需要注意的是之前层不是通过加法,而是通过叠加(concatenate)的方式组合在一起的。
1.2 Dense Block
近年来,优秀的backbone论文多在通过设计block结构来加强网络的性能和可训练程度。这一思路,自从Inception和ResNet提出以来,几乎成了设计CNN的惯常思考路线。其中,Residual block,Inception block,以及1x1卷积的的作用被广泛地使用。DenseNet也是在这种思路上前进的,其基本block结构如下:
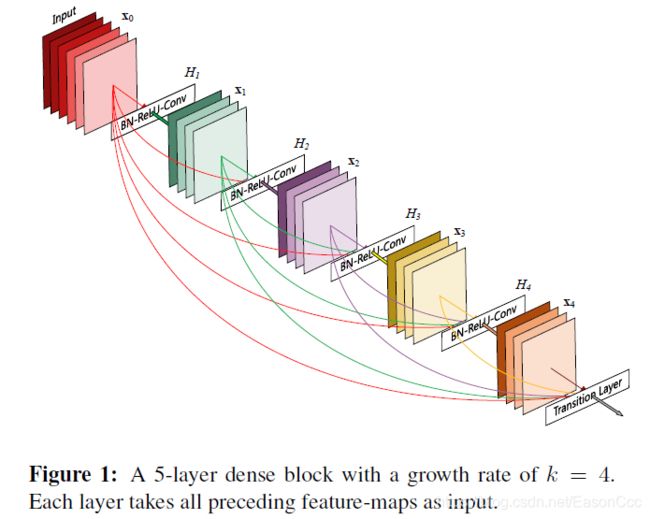
如上图,DenseNet基本block 结构的核心思想是——它将当前层的输出特征用于后续网络的每一层当中。其中block中特征层的数量表示为L;每个特征层输出特征图的数量,也就是说滤波器的数量称为Growth rate,表示为k.。 每个block中第l层的输入为k_0+(l-1)k,其中k_0为初始输入的维度。注意,从结构图中,我们可以看出block中最后一层的输出也会叠加之前特征层的输出,再送到Transition layer。
基于该block结构构件的DenseNet具有以下的优点:
- 进一步缓解了梯度消失的问题;
- 利用这种密集结构强化了特征传递的过程;
- 促进了不同层之间特征的融合;
- 将k设置得较小即可实现很好的性能,显著减少了网络的参数量。
1.3 网络结构
DenseNet的主干主要由两个关键部分:(1)Dense block,(2)连接两个Dense block的transition layer。Dense block主要用来学习特征表示,和ResNet不同的是,Dense不利用Convolution进行降维,其中的卷积层都是stride为1,same padding ;transition layer的作用主要是对特征进行整维,得到预期的特征维度和特征层的数量。

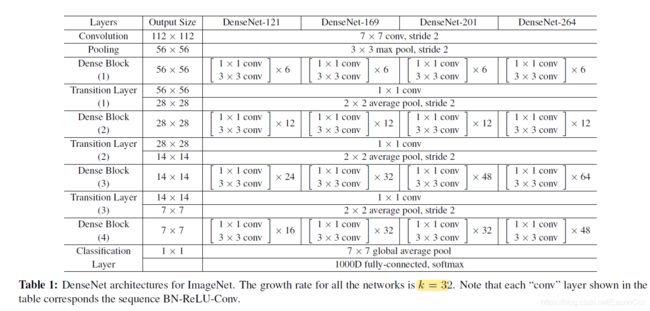
下图是论文中给出的是k = 32的DenseNet在ImageNet上测试的网络结构示例,这篇博客也是复现下表的几种网络结构:
1.4 实现细节
1.4.1 BN-ReLU-Conv
像Inception和ResNeXt一样,DenseNet使用BN-ReLU-Conv的结构代替传统的卷积层,本文所说的卷积层都表示的是BN-ReLU-Conv。
1.4.2 Transition layers
DenseNet通过transition layers调整输出特征的尺寸,每个Transition Layer包括一个1x1卷积和一个2x2的均值池化。其中,1x1卷积实现对特征进行压缩,通过一个系数θ控制,假设其输入为m层特征,则输出[θm]层特征;2x2均值池化实现特征降维。
1.4.3 Bottleneck结构
受ResNet启发,Dense block采用Bottleneck结构,该结构为1x1的卷积后面紧跟一个3x3的卷积,stride=1,same padding。在DenseNet中,Bottleneck中的1x1卷积输出的特征层数为4k。
1.4.4 初始的7x7卷积层
在ImageNet上,DenseNet首先使用一个7x7卷积层(stride=2,same padding),该卷积层的输出层数设置为2k。
2 PyTorch实现
2.1 BN-ReLu-Conv
class BN_Conv2d(nn.Module):
"""
BN_CONV_RELU
"""
def __init__(self, in_channels: object, out_channels: object, kernel_size: object, stride: object, padding: object,
dilation=1, groups=1, bias=False) -> object:
super(BN_Conv2d, self).__init__()
self.seq = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=bias),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
return F.relu(self.seq(x))
2.2 Dense Block
Dense Block通过grow rate,卷积层数量L,输入特征层数三个参数控制:
class DenseBlock(nn.Module):
def __init__(self, input_channels, num_layers, growth_rate):
super(DenseBlock, self).__init__()
self.num_layers = num_layers
self.k0 = input_channels
self.k = growth_rate
self.layers = self.__make_layers()
def __make_layers(self):
layer_list = []
for i in range(self.num_layers):
layer_list.append(nn.Sequential(
BN_Conv2d(self.k0+i*self.k, 4*self.k, 1, 1, 0),
BN_Conv2d(4 * self.k, self.k, 3, 1, 1)
))
return layer_list
def forward(self, x):
feature = self.layers[0](x)
out = torch.cat((x, feature), 1)
for i in range(1, len(self.layers)):
feature = self.layers[i](out)
out = torch.cat((feature, out), 1)
return out
2.3 网络搭建并测试
DenseNet的网络结构相比之前复现的一些基于Inception结构的网络,其结构的重复程度比较高,所以只要算清楚了每个block之间的关系,代码实现还是挺简单的:
class DenseNet(nn.Module):
def __init__(self, layers: object, k, theta, num_classes) -> object:
super(DenseNet, self).__init__()
# params
self.layers = layers
self.k = k
self.theta = theta
# layers
self.conv = BN_Conv2d(3, 2*k, 7, 2, 3)
self.blocks, patches = self.__make_blocks(2*k)
self.fc = nn.Linear(patches, num_classes)
def __make_transition(self, in_chls):
out_chls = int(self.theta*in_chls)
return nn.Sequential(
BN_Conv2d(in_chls, out_chls, 1, 1, 0),
nn.AvgPool2d(2)
), out_chls
def __make_blocks(self, k0):
"""
make block-transition structures
:param k0:
:return:
"""
layers_list = []
patches = 0
for i in range(len(self.layers)):
layers_list.append(DenseBlock(k0, self.layers[i], self.k))
patches = k0+self.layers[i]*self.k # output feature patches from Dense Block
if i != len(self.layers)-1:
transition, k0 = self.__make_transition(patches)
layers_list.append(transition)
return nn.Sequential(*layers_list), patches
def forward(self, x):
out = self.conv(x)
out = F.max_pool2d(out, 3, 2, 1)
# print(out.shape)
out = self.blocks(out)
# print(out.shape)
out = F.avg_pool2d(out, 7)
# print(out.shape)
out = out.view(out.size(0), -1)
out = F.softmax(self.fc(out))
return out
搭建网络并测试:
def densenet_121(num_classes=1000):
return DenseNet([6, 12, 24, 16], k=32, theta=0.5, num_classes=num_classes)
def densenet_169(num_classes=1000):
return DenseNet([6, 12, 32, 32], k=32, theta=0.5, num_classes=num_classes)
def densenet_201(num_classes=1000):
return DenseNet([6, 12, 48, 32], k=32, theta=0.5, num_classes=num_classes)
def densenet_264(num_classes=1000):
return DenseNet([6, 12, 64, 48], k=32, theta=0.5, num_classes=num_classes)
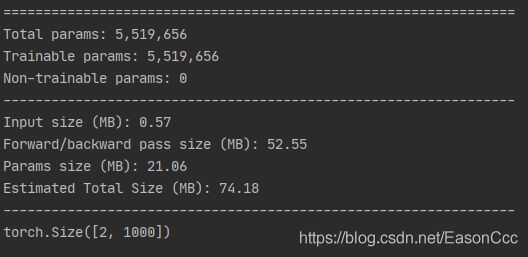
def test():
net = densenet_264()
summary(net, (3, 224, 224))
x = torch.randn((2, 3, 224, 224))
y = net(x)
print(y.shape)
test()
当k=32,θ=0.5时,DenseNet_264网络的测试结果如下图,可以看到DenseNet的参数量确实比ResNet要少得多。