前言
ViT通过简单地将图像分割成固定长度的tokens,并使用transformer来学习这些tokens之间的关系。tokens化可能会破坏对象结构,将网格分配给背景等不感兴趣的区域,并引入干扰信号。
为了缓解上述问题,本文提出了一种迭代渐进采样策略来定位区分区域。在每次迭代中,当前采样步骤的嵌入被馈送到transformer编码层,并预测一组采样偏移量以更新下一步的采样位置。渐进抽样是可微的。当与视觉transformer相结合时,获得的PS-ViT网络可以自适应地学习到哪里去看。
PS-ViT既有效又高效。在ImageNet上从头开始训练时,PS-VIT的TOP-1准确率比普通VIT高3.8%,参数减少了大约4倍,FLOP减少了10倍。
本文来自公众号CV技术指南的
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。

论文:Vision Transformer with Progressive Sampling
代码:https://github.com/yuexy/PS-ViT
Background
transformer最初是为处理中等大小的序列而量身定做的,并且具有二次计算复杂度。序列长度。它们不能直接用于处理具有大量像素的图像。
为了克服计算复杂性问题,ViT采用了一种朴素的标记化(tokenization)方案,该方案将一幅图像分割成一系列规则间隔的patches,这些patches被线性投影到tokens中。通过这种方式,图像被转换成数百个视觉tokens,这些视觉tokens被馈送到transformer编码层的堆栈中进行分类。ViT取得了很好的效果,特别是在大规模数据集上进行了预训练,这证明了全transformer结构是一种很有前途的视觉任务替代方案。然而,这种tokens化方案的局限性是显而易见的。

首先,硬分割可能会分离出一些高度相关的区域,这些区域应该用同一组参数建模,这破坏了固有的对象结构,并使输入patches的信息量变得较少。图显示猫头被分成几个部分,导致仅基于一个部分的识别挑战。其次,tokens被放置在规则网格上,而与底层图像内容无关。图显示,大多数网格聚焦在不感兴趣的背景上,这可能导致感兴趣的前景对象淹没在干扰信号中。
创新思路
人类视觉系统以一种完全不同的方式组织视觉信息,而不是一次不加区别地处理整个场景。取而代之的是,它循序渐进地、选择性地将注意力集中在视觉空间的有趣部分,无论何时何地需要它,而忽略不感兴趣的部分,随着时间的推移,结合来自不同注视的信息来理解场景。
受上述过程的启发,论文提出了一种新的基于transformer的渐进采样(Progressive Sampling)模块,该模块能够学习从哪里看图像,以缓解ViT中简单的tokens化方案带来的问题。

论文提出的模块不是从固定位置采样,而是以迭代的方式更新采样位置。如图所示,在每次迭代中,当前采样步骤的tokens被馈送到transformer编码层,并预测一组采样偏移量以更新下一步的采样位置。该机制利用transformer的能力来捕获全局信息,通过结合本地上下文和当前tokens的位置来估计对感兴趣区域的偏移量。这样,注意力就会像人类视觉一样,一步一步地集中到图像的可辨别区域。
Methods

Progressive Sampling
ViT规则地将一幅图像分成16×16块,这些块被线性投影到一组标记中,而不考虑图像区域的内容重要性和对象的整体结构。为了更好地关注图像的感兴趣区域,减轻图像结构破坏的问题,提出了一种新的渐进式采样模型。由于它的可微性,它是通过后续基于vision transformer的图像分类任务自适应驱动的。

![]()
渐进式采样模块的体系结构
在每个迭代中,给定采样位置Pt和特征映射F,对初始Tokens T't和特征映射F进行采样,并将其与基于pt生成的位置编码Pt和上一次迭代的输出Tokens Tt−1进行元素级相加,然后送入一个编码层来预测当前迭代的Tokens Tt.。通过一个基于Tt的全连接层预测偏移量矩阵,将Tt与Pt相加,得到下一次迭代的采样位置Pt+1。上面的过程迭代了N次。
在每次迭代中,通过将采样位置与上次迭代的偏移向量相加来更新采样位置。Pt+1 = Pt + Ot, 其中Ot表示在迭代t处预测的采样位置矩阵和偏移矩阵。对于第一次迭代,我们将p1初始i化为规则间隔的位置,就像在ViT中所做的那样。具体地说,第i个位置由

![]()
其中π和π将位置索引分别映射到行索引和列索引。Sh和Sw分别为其轴向和轴向的步长。然后在输入特征图的采样位置对初始tokens进行采样,如下所示
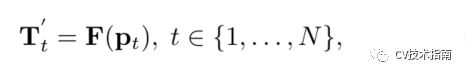
![]()
由于Pt的元素是小数,所以采样是通过双线性插值运算来实现的,该运算是可微的。输入特征图F和采样位置Pt。初始采样tokens、上次迭代的输出tokens和当前采样位置的位置编码在被馈送到一个编码层以获得当前迭代的输出tokens之前,被进一步以元素方式相加。

将采样位置的归一化绝对坐标投影到一个嵌入空间作为位置嵌入。最后,预测除上一次迭代之外的下一次迭代的采样位置偏移量,如下所示

其中Mt是用于预测采样偏移矩阵的可学习线性变换。
Overall Architecture

![]()
渐进式采样Vision Transformer(PS-VIT)的总体架构
在给定输入图像的情况下,首先提取其特征图F。然后,在渐进式采样模块中的自适应位置pi处,对tokens Ti进行渐进式和迭代式采样。渐进采样模块的最终输出tokens TN被填充分类tokens Tcls,并进一步馈送到vision tranformer模块以细化Tcls,最终在分类模块中进行分类。

Conclusion
论文提出的渐进式采样是可区分的,并且可以很容易地插入ViT而不是硬分裂,以构建端到端的vision transformer,并使用称为PSViT的渐进式采样网络来构建端到端的vision transformer。由于任务驱动的训练,PS-ViT倾向于对与语义结构相关的对象区域进行采样。此外,与简单的tokens化相比,它更关注前景对象,而对模糊背景的关注较少。
1. 当在ImageNet上从头开始训练时,提出的PS-VIT优于当前基于transformer的SOTA方法。具体地说,它在ImageNet上达到了82.3%的TOP1准确率,在只有Deit约1/4参数和1/2 FLOP的情况下,准确率比Deit更高。如图所示,论文观察到,与基于transformer的SOTA网络ViT和Deit相比,PS-ViT明显更好、更快、参数效率更高。

2. 与其他SOTA 的对比

3.比较PS-VIT和SOTA网络在FLOP和速度方面的效率。

4. 渐进式采样模块中抽样位置的可视化。箭头的起点是初始采样位置(P1),而箭头的终点是最终采样位置(P4)。

欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章