大数据离线批处理场景化解决方案----离线处理技术框架介绍
大数据离线批处理化解决方案
HDFS概述
• HDFS(Hadoop Distributed File System)基于Google发布的GFS论文设计开发。
• 其除具备其它分布式文件系统相同特性外,HDFS还有自己特有的特性:
• 高容错性:认为硬件总是不可靠的。
• 高吞吐量:为大量数据访问的应用提供高吞吐量支持。
• 大文件存储:支持存储TB-PB级别的数据。
• 不适用场景:
• 低时间延迟数据访问的应用,例如几十毫秒范围。
原因:HDFS是为高数据吞吐量应用优化的,这样就会造成以高时间延迟为代价。
• 大量小文件 。
原因:NameNode启动时,将文件系统的元数据加载到内存,因此文件系统所能存储的文件总数受限于NameNode内存容量。 根据经验,每个文件,目录和数据块的存储信息大约占150字节,如果一百万个文件,且每个文件占一个数据块,那至少需要300MB的内存空间,但是如果存储十亿个文件,那么需要的内存空间将是非常大的。
• 多用户写入,任意修改文件。
原因:现在HDFS文件只有一个writer,而且写操作总是写在文件的末尾。
• 流式数据访问:在数据集生成后,长时间在此数据集上进行各种分析。每次分析都将涉及该数据集的大部分数据甚至全部数据,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。与流数据访问对应的是随机数据访问,它要求定位、查询或修改数据的延迟较小,比较适合于创建数据后再多次读写的情况,传统关系型数据库很符合这一点。
基本系统架构
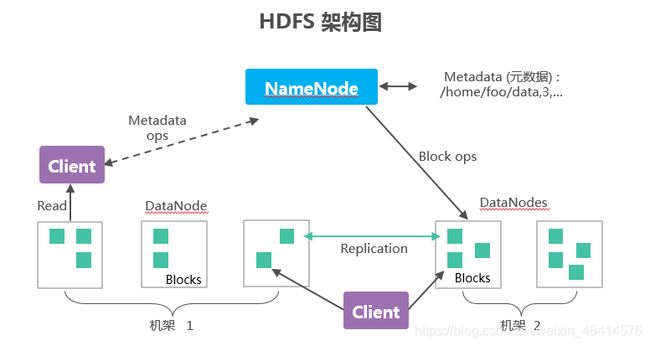
• HDFS架构包含三个部分:NameNode,DataNode,Client。
• NameNode:NameNode用于存储、生成文件系统的元数据。运行一个实例。
• DataNode:DataNode用于存储实际的数据,将自己管理的数据块上报给NameNode ,运行多个实例。
• Client:支持业务访问HDFS,从NameNode ,DataNode获取数据返回给业务。多个实例,和业务一起运行。
• Metadata:元数据
• 文件块(片)被存在哪个集群;谁有权限查看、修改这个文件;多少datanodes在集群里;集群的事物日志存储位置。
• Replication:副本 通常存储三份。
HDFS回收站机制
• 在HDFS里,删除文件时,不会真正的删除,其实是放入回收站,回收站里的文件可以用来快速恢复误删文件。
• 可以设置一个时间阀值(单位:分钟),当回收站里文件的存放时间超过这个阀值或是回收站被清空时,文件才会被彻底删除,并且释放占用的数据块。
• Hadoop回收站trash,默认是关闭的,若开启需要修改配置文件core-site.xml。
• 
• 注:value的时间单位是分钟,如果配置成0,表示不开启HDFS的回收站。
• 1440=24*60,表示的一天的回收间隔,即文件在回收站存在一天后,被清空。
• hdfs dfs –lsr /user/root/.Trash 可以找到误删的文件
Hive概述
• Hive是基于Hadoop的数据仓库软件,可以查询和管理PB级别的分布式数据。
• Hive特性:
• 灵活方便的ETL (Extract/Transform/Load)。
• 支持MapReduce、Tez、Spark多种计算引擎。
• 可直接访问HDFS文件以及HBase。
• 易用易编程。
Hive的架构

• MetaStore : 存储表、列和Partition等元数据。Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
• Driver : 管理HiveQL执行的生命周期,并贯穿Hive任务整个执行期间。
• Compiler : 编译HiveQL并将其转化为一系列相互依赖的Map/Reduce任务。
• Optimizer : 优化器,分为逻辑优化器和物理优化器,分别对HiveQL生成的执行计划和MapReduce任务进行优化。
• Executor : 按照任务的依赖关系分别执行Map/Reduce任务。
• ThriftServer : 提供thrift接口,作为JDBC和ODBC的服务端,并将Hive和其他应用程序集成起来。
• Clients : 包含命令行接口(CLI/Beeline) 和JDBC/ODBC 接口,为用户访问提供接口。
• JDBC/ODBC,通过Java代码操作,需要启动Hiveserver2,然后连接操作。
Hive的数据存储模型

• 数据库:创建表时如果不指定数据库,则默认为default数据库。
• 表:物理概念,实际对应HDFS上的一个目录。
• 分区:对应所在表所在目录下的一个子目录。
• 桶:对应表或分区所在路径的一个文件。
• 倾斜数据:数据集中于个别字段值的场景,比如按照城市分区时,80%的数据都来自某个大城市。
• 正常数据:不存在倾斜的数据。
Hive内部表和外部表的区别
• 区别:

• 查询表的类型:
•![]()
• 修改内部表tableName为外部表:
• ![]()
• 修改外部表tableName为内部表:
• ![]()
• Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
• 在删除表的时候,内部表的元数据和实际数据会被一起删除, 而外部表只删除元数据,不删除实际数据。这样外部表相对来说更加安全。
Hive内置函数
• 查看系统函数的用法:hive> show functions;
• 显示函数的用法:hive> desc function upper;
• 详细显示函数的用法:hive> desc function extended upper;
• 常用函数:
• 数学函数,如round( )、 abs( )、rand( )等。
• 日期函数,如to_date( )、current_date( )等。
• 字符串函数,如trim( )、length( )、substr( )等。
• round()–返回近似值(四舍五入)。
• abs()–计算绝对值。
• to_date( )-- yyyy-MM-dd HH:MM:ss 截取日期。
• current_date–获取当前日期,当前是 2019-07-28。
• trim( )–去除空字符串。
• length( )–求字符串长度。
• substr( )–字符串截取。
Hive自定义UDF
• 当Hive提供的内置函数无法满足业务处理需要时,此时就可以考虑使用用户自定义函数,编写处理代码并在查询中使用。
• UDF(User-Defined-Function)
o 用于接收单个数据行,并产生一个数据行作为输出。
• UDAF(User-Defined Aggregation Function)
o 用于接收多个数据行,并产生一个数据行作为输出。
• UDTF(User-Defined Table-Generating Functions)
o 用于接收单个数据行,并产生多个数据行作为输出。
• 按实现方式,UDF分如下分类:
• 普通的UDF,用于操作单个数据行,且产生一个数据行作为输出。
• 用户定义聚集函数UDAF(User-Defined Aggregating Functions),用于接受多个输入数据行,并产生一个输出数据行。
• 用户定义表生成函数UDTF(User-Defined Table-Generating Functions),用于操作单个输入行,产生多个输出行。
• 按使用方法,UDF有如下分类:
• 临时函数,只能在当前会话使用,重启会话后需要重新创建。
• 永久函数,可以在多个会话中使用,不需要每次创建。
UDF开发步骤
• 继承“org.apache.hadoop.hive.ql.exec.UDF”。
• 实现一个evaluate()方法,编写要实现的逻辑。
• 打包并上传到HDFS里。
• Hive创建临时函数。
• 调用该函数。
Hive调优
• 数据倾斜
• 数据倾斜指计算数据的时候,数据的分散度不够,导致大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢。
• 日常使用过程中,容易造成数据倾斜的原因可以归纳为如下几点:
o group by
o distinct count(distinct xx)
o join
• 举个Wordcount 的入门例子,它的map 阶段就是形成 (“aaa”,1)的形式,然后在reduce 阶段进行 value 相加,得出 “aaa” 出现的次数。若进行Wordcount 的文本有100G,其中 80G 全部是 “aaa” 剩下 20G 是其余单词,那就会形成 80G 的数据量交给一个 reduce 进行相加,其余 20G 根据 key 不同分散到不同 reduce 进行相加的情况。如此就造成了数据倾斜,临床反应就是 reduce 跑到 99%然后一直在原地等着 那80G 的reduce 跑完。
• 调优参数:
• set hive.map.aggr=true;在map中会做部分聚集操作,效率更高但需要更多的内存。
• set hive.groupby.skewindata=true;此时生成的查询计划会有两个MRJob,可实现数据倾斜时负载均衡。
• 第一MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
• map side join
• set hive.auto.convert.join=true;当连接一个较小和较大表的时候,把较小的表直接放到内存中去,然后再对较大的表进行map操作。
• join发生在map端的时候,每当扫描一个大的table中的数据,就要去查看小表的数据,哪条与之相符,继而进行连接。这里的join并不会涉及reduce操作。map端join的优势就是在于没有shuffle的过程。
• 并行化执行
• 每个查询会被Hive转化为多个阶段,当有些阶段关联性不大时,可以并行化执行,减少整个任务的执行时间。
• 开启任务并行执行:set hive.exec.parallel=true;
• 设置同一个sql允许并行任务的最大线程数(例如设置为8个):set hive.exec.parallel.thread.number=8;
HQL开发
• 场景说明
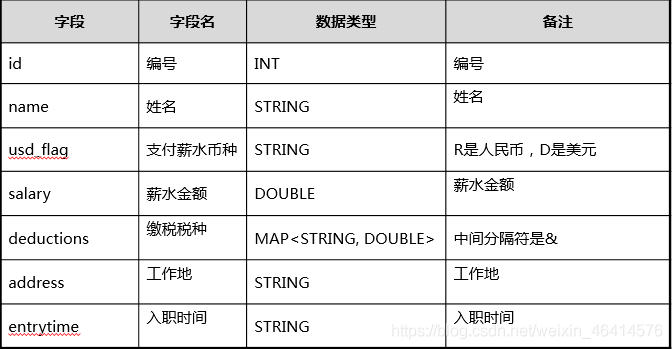
• 假定用户开发一个基于Hive的数据分析应用,用于分析企业雇员信息。
• 假定需要创建三张表:
o 雇员信息表: “employees_info”。
o 雇员联络信息表: “employees_concat”。
o 雇员信息扩展表:“employees_info_extended”。
• 
• 
• 
• 
• 统计要求
• 查看薪水支付币种为美元的雇员联系方式。
• 查询入职时间为2019年的雇员编号、姓名和电话号码字段,并将查询结果加载进表employees_info_extended对应的分区中。
• 统计表employees_info中有多少条记录。
• 查询以“cn”结尾的邮箱的员工信息。
•
• 创建雇员信息表
• 
• 创建雇员联络信息表
• 
• 创建雇员信息扩展表
• 
• 数据加载
• 从本地加载数据到雇员信息表
o 
• 从hdfs加载信息到雇员信息表
o 
• 查询
• 查看薪水支付币种为美元的雇员联系方式。
o 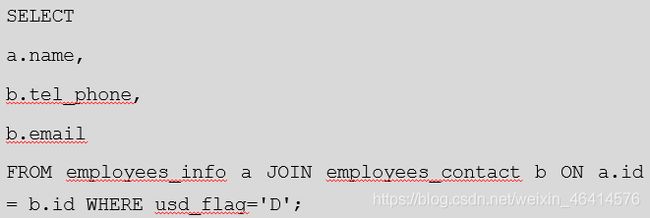
• 查询入职时间为2019年的雇员编号、姓名和电话号码字段,并将查询结果加载进表employees_info_extended中的入职时间为2019的分区中。
o 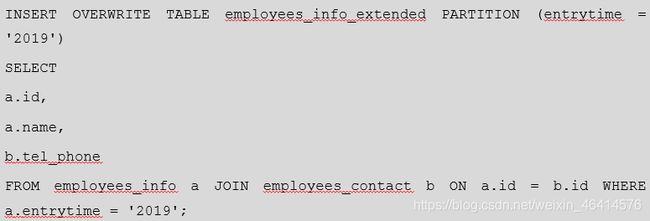
• 使用Hive中自带的函数COUNT(),统计表employees_concat中有多少条记录。
o ![]()
• 查询以“cn”结尾的邮箱的员工信息。
o

数据集市和数据仓库的区别
• 数据集市
• 数据集市(Data Mart) ,也叫数据市场,数据集市就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
• 数据仓库
• 为满足各类零散分析的需求,通过数据分层和数据模型的方式,并以基于业务和应用的角度将数据进行模块化的存储。
• 从字义上看, “仓库”可以想像成一所大房子,高高的货架,合理的出入路线,是一种集中存储货物的地方,一般顾客是不来参观访问的; 而说到“集市”,就容易联想到空旷的场地,川流不息,大小商户摆出摊子,卖衣物的、卖烧饼及卖艺的,是让顾客来消费的地方。 具体来说,数据仓库仅仅是提供存储的,提供一种面向数据管理的服务,不面向最终分析用户;而数据集市是面向分析应用的,面向最终用户。
Hive数据仓库
• 数据仓库分层:
• ODS层:原始数据层。原始的数据通常是杂乱无章的,但是又具有安全隐私考虑,通常应用侧是不能看到的。
• DWD层:结构和粒度与原始表保持一致,简单清洗。数据明细详情,去除空值,脏数据,超过极限范围的
明细解析
具体表
• DWS层:以DWD为基础,进行轻度汇总。---------->有多少个宽表?多少个字段
服务层–留存-转化-GMV-复购率-日活。
点赞、评论、收藏;。
轻度聚合对DWD。
• ADS层:为各种统计报表提供数据。做分析处理同步到RDS数据库里边。
分层的优点
• 复杂问题简单化
• 将任务分解成多个步骤完成,每一层只处理单一的步骤,比较简单,并且方便定位问题。
• 减少重复开发
• 规范数据分层,通过中间层数据,减少最大的重复计算,增加一次计算结果的复用性。
• 隔离原始数据
• 避免数据异常或者数据敏感,使真实数据与统计数据解耦。
• 我们对数据进行分层的一个主要原因就是希望在管理数据的时候,能对数据有一个更加清晰的掌控,详细来讲,主要有下面几个原因:
• 清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
• 数据血缘追踪:简单来讲可以这样理解,我们最终给业务诚信的是一能直接使用的张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
• 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
• 把复杂问题简单化。讲一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
• 屏蔽原始数据的异常。
• 屏蔽业务的影响,不必改一次业务就需要重新接入数据。
Spark简介
• Spark是基于内存的分布式批处理系统,它把任务拆分,然后分配到多个的CPU上进行处理,处理数据时产生的中间产物(计算结果)存放在内存中,减少了对磁盘的I/O操作,大大的提升了数据的处理速度,在数据处理和数据挖掘方面比较占优势。
Spark应用场景
• 数据处理(Data Processing):可以用来快速处理数据,兼具容错性和可扩展性。
• 迭代计算(Iterative Computation):支持迭代计算,有效应对复杂的数据处理逻辑。
• 数据挖掘(Data Mining):在海量数据基础上进行复杂的挖掘分析,可支持多种数据挖掘和机器学习算法。
• 流式处理(Streaming Processing):支持秒级延迟的流处理,可支持多种外部数据源。
• 查询分析(Query Analysis):支持SQL的查询分析,同时提供领域特定语言(DSL)以方便操作结构化数据,并支持多种外部数据源。
Spark对比MapReduce
• 性能上提升了100倍。
• Spark的中间数据放在内存中,对于迭代运算的效率更高;进行批处理时更高效,同时有着更低的延迟。
• Spark提供更多的数据集操作类型,编程模型比MapReduce更灵活,开发效率更高。
• 更高的容错能力(血统机制)。
RDD
• RDD是分布式弹性数据集,可以理解一个存储数据的数据结构。Spark会把所要操作的数据,加载到RDD上,即RDD所有操作都是基于RDD来进行的。RDD是只读和可分区。要想对RDD进行操作,只能重新生成一个新的RDD。
• 从HDFS输入创建,或从与Hadoop兼容的其他存储系统中输入创建。
• 从父的RDD转换的到新的RDD。
• 从数据集合转换而来,通过编码实现。
• RDD的存储:
• 用户可以选择不同的存储级别缓存RDD以便重用。
• 当前RDD默认是存储于内存,但当内存不足时,RDD会溢出到磁盘中。
• RDD(Resilient Distributed Datasets)之所以为“弹性”的特点
• 基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错);
• Task如果失败会自动进行特定次数的重试(默认4次);
• Stage如果失败会自动进行特定次数的重试(可以值运行计算失败的阶段),只计算失败的数据分片;
• 数据调度弹性:DAG TASK 和资源管理无关;
• checkpoint;
• 自动的进行内存和磁盘数据存储的切换
Shuffle
• Shuffle 是划分 DAG 中 stage 的标识,同时影响 Spark 执行速度的关键步骤
• RDD 的 Transformation 函数中,分为窄依赖(narrow dependency)和宽依赖(wide dependency)的操作.
• 窄依赖跟宽依赖的区别是是否发生Shuffle(洗牌) 操作。
窄依赖
• 窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用。
• 表现为:
• 一个父RDD的每一个分区对应于一个子RDD分区。
• 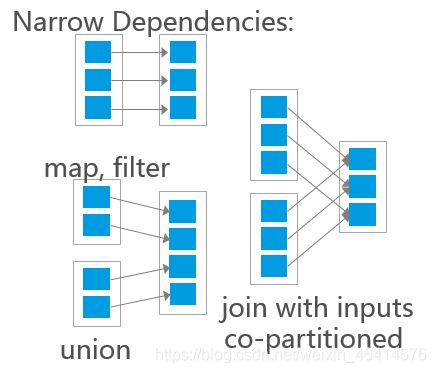
宽依赖
• 宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用。
• 表现为:
• 父RDD的每个分区都被多个子RDD分区使用
• 
o 父RDD的每个分区都有可能被多个子RDD分区使用。
o 子RDD分区通常对应父RDD所有分区。
o 一对多
o 只要遇到宽依赖就会产生Shuffle。
Stage

• 当一个任务在spark执行时,该任务会被拆分成多个Stage,然后分配到不同的节点上进行执行。一个运算结果,可能需要借助于多次转换。每一次的转换都需要上次转换后的结果。这样会很大的影响运算速度。我们可以把转过的过程拆分出去,分配到不同的RDD上进行计算。这样转换的过程可以同时运行,最后直接代入上次的转换结果来获得最后的运算结果,这样会节省到运算转换的时间。而每个转换的过程可以看成一个Stage,如下图:RDD A是一个stage,RDD B,G是一个stage,RDD C,D,E,F是一个stage)。
Transformation
• Transformation是RDD的算子类型,它的返回值还是一个RDD。
• Transformation操作属于懒操作(算子),不会真正触发RDD的处理计算。
• 变换方法的共同点:
• 不会马上触发计算。
• 每当调用一次变换方法,都会产生一个新的RDD。
• 例如:map(func),flatMap(func)
• RDD到RDD的过程就是Transformation。
• Map:参数是函数,函数应用于RDD每一个元素,返回值是新的RDD
• Flatmap:扁平化map,对RDD每个元素转换, 然后再扁平化处理
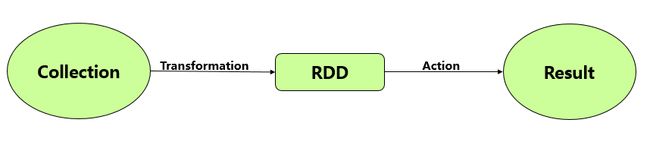
Action
• Action是RDD的算子,它的返回值不是一个RDD。Action操作是返回结果或者将结果写入存储的操作。Action是Spark应用启动执行的触发动作,得到RDD的相关计算结果或将RDD保存到文件系统中。
• 
SparkConf
• SparkConf是用来对Spark进行任务参数配置的对象。
• 是通过键值对的形式,设置Spark任务执行时所需要的参数。
• Spark读取任务参数的优先级是:
• 代码配置>动态参数>配置文件。
• 任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数。
• 初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD和共享变量。Spark shell会自动初始化一个SparkContext,在编程中的具体实现为:
• val conf = new SparkConf().setAppName(“AppName”).setMaster(“local[3] or masterIP:PORT”)。
• val sc = new SparkContext(conf)。
• SparkContext的简单构造函数为:
• val sc = new SparkContext(“local[3] or masterIP:PORT”,“AppName”)
SparkContext
• SparkContext是Spark的入口,相当于应用程序的main函数。
• SparkContext表示与Spark集群的连接,可用于在该集群上创建RDD,记录计算结果和环境配置等信息。
• 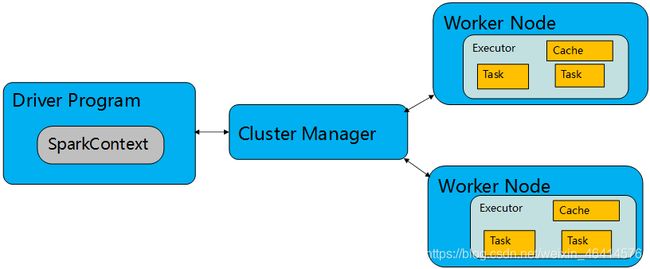
• ClusterManager负责分配资源,有点像YARN中ResourceManager那个角色,大管家握有所有的干活的资源,属于乙方的总包。
• WorkerNode是可以干活的节点,听大管家ClusterManager差遣,是真正有资源干活的主。
• Executor是在WorkerNode上起的一个进程,相当于一个包工头,负责准备Task环境和执行Task,负责内存和磁盘的使用。
• Task是施工项目里的每一个具体的任务。
• Driver是统管Task的产生与发送给Executor的,是甲方的司令员。
• SparkContext是与ClusterManager打交道的,负责给钱申请资源的,是甲方的接口人
SparkSession
• Spark2.0中引入了SparkSession的概念,为用户提供了一个统一的切入点来使用Spark的各项功能。
• 封装了SparkConf和SparkContext对象,方便用户使用Spark的各种API。
• 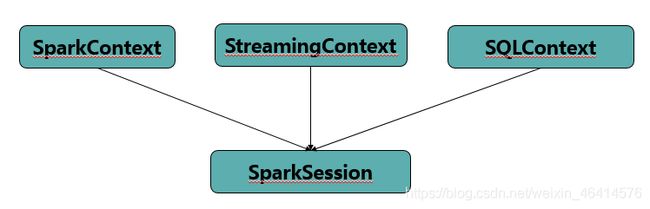
• Spark2X以后,用SparkSession代替SparkConf和SparkContext。
• 在以前的版本中,sparkcontext 是spark的入口点,因为RDD是主要的API,它是使用上下文API创建和操作的。 对于每个其他API,我们需要使用不同的context。
• 对于流式传输,我们需要streamingContext。 对于SQL sqlContext和hive hiveContext.,因为dataSet和DataFrame API正在成为新的独立API,我们需要为它们构建入口点。 因此在spark 2.0中,我们为DataSet和DataFrame API创建了一个新的入口点构建,称为Spark-Session。
SparkSQL简介
• SparkSQL是Spark用来处理结构化数据的一个模块,可以在Spark应用中直接使用SQL语句对数据进行操作。
• SQL语句通过SparkSQL模块解析为RDD执行计划,交给SparkCore执行。
• 
• SparkSQL的命令最终还会交给SparkCore去执行
• 可以看成是对Spark RDD编程接口的封装,对有SQL背景的开发人员提供了熟悉的接口。即满足了使用分布式架构,对海量结构化数据的处理需求,又实现了对已有知识积累的继承性。
SparkSQL使用方式
• 通过SparkSession提交SQL语句。任务像普通Spark应用一样,提交到集群中分布式运行。
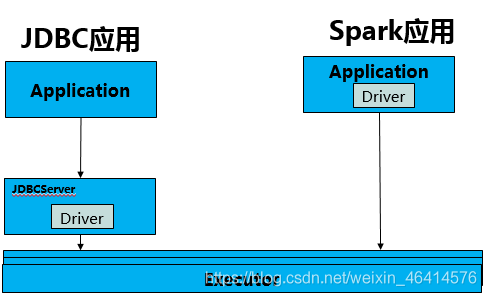
• JDBC:
• 应用加载JDBC驱动,然后统一提交到集群的JDBCServer执行。
• JDBCServer是单点服务,会成为任务执行的瓶颈,不能处理海量数据和高并发任务。
• 
SparkSQL关键概念DataSet
• DataSet:
• DataSet是一个由特定域的对象组成的强类型集合,可通过功能或关系操作并行转换其中的对象
• DataSet以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式存储,不需要反序列化就可以执行sort、filter、shuffle等操作。
• Dataset是“懒惰”的,只在执行action操作时触发计算。当执行action操作时,Spark用查询优化程序来优化逻辑计划,并生成一个高效的并行分布式的物理计
• RDD、DataFrame、Dataset是Spark三个最重要的概念,RDD和DataFrame两个概念出现的比较早,Dataset相对出现的较晚(1.6版本开始出现)
• Dataset是一个新的数据类型。Dataset与RDD高度类似,性能比较好。
• Dataset不需要反序列化就可执行大部分操作。本质上,数据集表示一个逻辑计划,该计划描述了产生数据所需的计算。
SparkSQL使用场景
• 适合:
• 结构化数据处理。
• 对数据处理的实时性要求不高的场景
• 需要处理PB级的大容量数据。
• 不适合:
• 实时数据查询。
Spark SQL简单查询
var df = spark.read.text(“/person.txt”)
• 查询:df.select(“id”,“name”).show()
• 带条件的查询:df.select( " i d " , "id", "id",“name”).where( " n a m e " = = = " b b b " ) . s h o w ( ) • 排 序 查 询 : d f . s e l e c t ( "name" === "bbb").show() • 排序查询:df.select( "name"==="bbb").show()•排序查询:df.select(“id”, " n a m e " ) . o r d e r B y ( "name").orderBy( "name").orderBy(“name”.desc).show
df.select( " i d " , "id", "id",“name”).sort($“name”.desc).show
SparkSQL开发
• 场景说明:
• 假定用户有网民网购时停留网站的日志文本,基于某些业务要求,需要开发Spark应用程序并实现如下功能:
o 统计日志文件中网购停留总时间超过2个小时的女性网民信息。
日志文本
• log1.txt:网民停留日志
• 日志文件第一列为姓名,第二列为性别,第三列为本次停留时间,单位为分钟。
• 分隔符为“,”。
LiuYang,female,20
YuanJing,male,10
GuoYijun,male,5
CaiXuyu,female,50
Liyuan,male,20
FangBo,female,50
LiuYang,female,20
YuanJing,male,10
GuoYijun,male,50
CaiXuyu,female,50
FangBo,female,60
LiuYang,female,20
YuanJing,male,10
CaiXuyu,female,50
FangBo,female,50
GuoYijun,male,5
CaiXuyu,female,50
Liyuan,male,20
CaiXuyu,female,50
FangBo,female,50
开发思路
• 目标
• 统计日志文件中网购停留总时间超过2个小时的女性网民信息。
• 大致步骤:
• 创建表,将日志文件数据导入到表中。
• 筛选女性网民,提取停留时间数据信息。
• 汇总每个女性停留总时间。
• 筛选出停留时间大于2个小时的女性网民信息。
Scala样例代码

Yarn-cluster作业提交
• 打jar包
• 上传到Linux某个目录下
• Yarn-cluster提交方式
• 
常用采集工具
• 由于大数据的数据源各种各样,由此对数据采集的挑战变的尤为突出。这里介绍几款常用数据采集工具:
• Sqoop
• Loader
• 收集工具,通常就是收集数据的,大数据里面,由于数据的来源多种多样,所以需要使用工具来收集,常用的收集工具有Loader,Sqoop,他们三个。
• 任何完整的大数据平台,一般包括以下的几个过程:数据采集–>数据存储–>数据处理–>数据展现(可视化,报表和监控)其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括:
• 数据源多种多样。
• 数据量大。
• 变化快。
• 如何保证数据采集的可靠性的性能。
• 如何避免重复数据。
• 如何保证数据的质量。
Sqoop简介
• Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
• Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(MySQL 、 PostgreSQL…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , PostgreSQL等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
• Sqoop这个工具是做数据迁移用的,是关系型数据库和Hive/Hadoop的数据迁移,方便大量数据的导入导出工作。Sqoop底层是通过MapReduce去实现的,但只有Map没有Reduce。
Sqoop应用
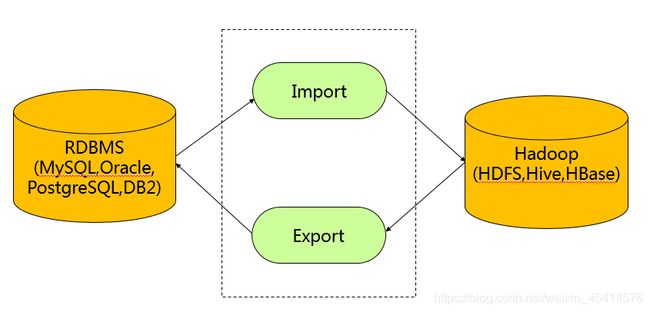
• 导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
• 导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等 Sqoop 的本质还是一个命令行工具,和 HDFS,Hive ,并没有什么高深的理论。
Sqoop原理
• Sqoop Import原理:
• Sqoop在import时,需要指定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。
• 每个map中再处理数据库中获取的一行一行的值,写入到HDFS中。
• 同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。
• Sqoop export 原理:
• 获取导出表的schema、meta信息,和Hadoop中的字段match;
• 并行导入数据: 将Hadoop 上文件划分成若干个分片,每个分片由一个Map Task进行数据导入。
Loader简介
• Loader是实现FusionInsight HD与关系型数据库、文件系统之间交换数据和文件的数据加载工具。
• 提供可视化向导式的作业配置管理界面;
• 提供定时调度任务,周期性执行Loader作业;
• 在界面中可指定多种不同的数据源、配置数据的清洗和转换步骤、配置集群存储系统等。
• 基于开源Sqoop研发,做了大量优化和扩展。
• Loader页面是基于开源Sqoop WebUI的图形化数据迁移管理工具,该页面托管在Hue的WebUI中。
Loader的应用场景

• Loader实现FusionInsight与关系型数据库、文件系统之间交换数据和文件,可以将数据从关系型数据库/文件服务器导入到FusionInsight HDFS/HBase/Hive中,或者反过来从Hadoop HDFS/HBase导出到关系型数据库/文件服务器中。
• Loader提供了本集群内部HDFS和HBase之间的数据导入/导出。
• RDB,Relational Data Base,关系型数据库。
• Customized Data Source:支持插件式,扩展外部数据源。
Loader特点

• Loader提供UI界面对作业进行管理,同时也提供了命令行接口,以满足客户调度程序或自动化脚本的需要。
• Loader使用MapReduce进行并行处理。但是在Loader的作业中,有参数会影响MapReduce分片,为了达到最高导入性能,需要选择合适的参数配置。
• Loader的安全版本是在FusionInsight统一配置的。