Spark学习笔记(三)——SparkSQL(DataSet、DataFrame、hive集成、连接mysql)
Spark SQL
- Spark SQL精华及与Hive的集成
-
- 一、Spark SQL简介
-
- 1、SQL on Hadoop
- 2、Spark SQL前身
- 3、Spark SQL架构
- 4、Spark SQL运行原理
- 5、Catalyst优化器
- 二、Spark Dataset API
-
- 1、创建
- 2、Dataset
- 3、演练
- 三、Spark DataFrame API
-
- 1、介绍
- 2、对比
- 3、创建
- 4、常用操作
- 5、RDD和DataFrame转换
- 四、Spark SQL操作外部数据源
-
- 1、Parquet文件
- 2、集成hive
- 3、RDBMS表
Spark SQL精华及与Hive的集成
一、Spark SQL简介
1、SQL on Hadoop
- SQL是一种传统的用来进行数据分析的标准
- Hive是原始的SQL-on-Hadoop解决方案
- Impala:和Hive一样,提供了一种可以针对已有Hadoop数据编写SQL查询的方法
- Presto:类似于Impala,未被主要供应商支持
- Shark:Spark SQL的前身,设计目标是作为Hive的补充
- Phoenix:基于HBase的开源SQL查询引擎
2、Spark SQL前身
- Shark的初衷:让Hive运行在Spark之上
- 是对Hive的改造,继承了大量Hive代码,给优化和维护带来了大量的麻烦

3、Spark SQL架构
- Spark SQL是Spark的核心组件之一(2014.4 Spark1.0)
- 能够直接访问现存的Hive数据
- 提供JDBC/ODBC接口供第三方工具借助Spark进行数据处理
- 提供了更高层级的接口方便地处理数据
- 支持多种操作方式:SQL、API编程
- 支持多种外部数据源:Parquet、JSON、RDBMS等
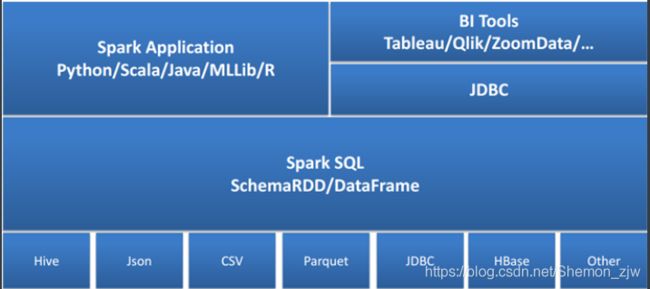
4、Spark SQL运行原理
- Catalyst优化器是Spark SQL的核心

Catalyst Optimizer:Catalyst优化器,将逻辑计划转为物理计划
5、Catalyst优化器
- 逻辑计划
SELECT name FROM
(
SELECT id, name FROM people
) p
WHERE p.id = 1
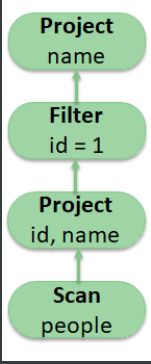
<=逻辑计划
- 优化
1、在投影上面查询过滤器
2、检查过滤是否可下压
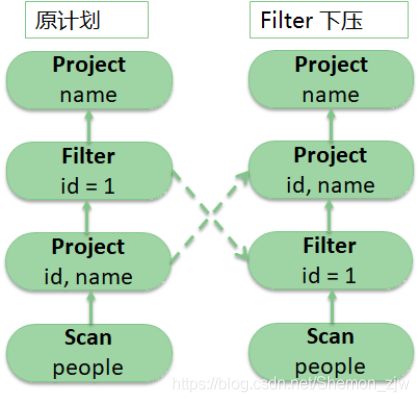
- 物理计划

二、Spark Dataset API
1、创建
- SparkContext
- SQLContext
- Spark SQL的编程入口
- HiveContext
- SQLContext的子集,包含更多功能
- SparkSession(Spark 2.x推荐)
- SparkSession:合并了SQLContext与HiveContext
- 提供与Spark功能交互单一入口点,并允许使用DataFrame和Dataset API对Spark进行编程
2、Dataset
- Dataset (Spark 1.6+)
- 特定域对象中的强类型集合
scala> spark.createDataset(1 to 3).show
scala> spark.createDataset(List(("a",1),("b",2),("c",3))).show
scala> spark.createDataset(sc.parallelize(List(("a",1,1),("b",2,2)))).show
1、createDataset()的参数可以是:Seq、Array、RDD
2、上面三行代码生成的Dataset分别是:
Dataset[Int]、Dataset[(String,Int)]、Dataset[(String,Int,Int)]
3、Dataset=RDD+Schema,所以Dataset与RDD有大部共同的函数,如map、filter等
- 使用Case Class创建Dataset
case class Point(label:String,x:Double,y:Double)
case class Category(id:Long,name:String)
val points=Seq(Point("bar",3.0,5.6),Point("foo",-1.0,3.0)).toDS
val categories=Seq(Category(1,"foo"), Category(2,"bar")).toDS
points.join(categories,points("label")===categories("name")).show
Scala中在class关键字前加上case关键字 这个类就成为了样例类,样例类和普通类区别:
(1)不需要new可以直接生成对象
(2)默认实现序列化接口
(3)默认自动覆盖 toString()、equals()、hashCode()
//典型应用场景RDD->Dataset
case class Point(label:String,x:Double,y:Double)
case class Category(id:Long,name:String)
val pointsRDD=sc.parallelize(List(("bar",3.0,5.6),("foo",-1.0,3.0)))
val categoriesRDD=sc.parallelize(List((1,"foo"),(2,"bar")))
val points=pointsRDD.map(line=>Point(line._1,line._2,line._3)).toDS
val categories=categories.map(line=>Category(line._1,line._2)).toDS
points.join(categories,points("label")===categories("name")).show
3、演练
- 需求说明
- 完成数据装载
- 使用RDD装载零售商店业务数据
- customers.csv、orders.csv、order_items.csv、products.csv
- 定义样例类
- Customer、Order、OrderItem、Product
- 将RDD转换为Dataset
- 使用RDD装载零售商店业务数据
- 请找出
- 谁的消费额最高?
- 哪个产品销量最高?
- 完成数据装载
import com.sun.org.apache.xalan.internal.xsltc.compiler.util.IntType
import org.apache.spark.sql.SparkSession
import org.apache.spark.{
SparkConf, SparkContext}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.catalyst.expressions.Cast
import org.apache.spark.sql.types.IntegerType
object mythirdspark {
case class Userinfos(userid:String,fname:String,lname:String, tel:String,tel2:String,addr:String,city:String,state:String,zip:String)
case class Orders(ordid:String,orddate:String,userid:String,ordstatu:String)
case class Products(proid:String,protype:String,title:String,price:String,img:String)
case class OrderItems(id:String,ordid:String,proid:String,buynum:String,countPrice:String,price:String)
def main(args: Array[String]): Unit = {
//读取数据生成对应的RDD
// val conf = new SparkConf().setMaster("local[*]").setAppName("myshops")
// val sc = new SparkContext(conf)
val spark = SparkSession.builder().master("local[*]").appName("myshops").getOrCreate()
val users = spark.sparkContext.textFile("file:///d:/study files/Spark/test/test01/customers.csv").cache()
val ords = spark.sparkContext.textFile("file:///d:/study files/Spark/test/test01/orders.csv").cache()
val pros = spark.sparkContext.textFile("file:///d:/study files/Spark/test/test01/products.csv").cache()
val itms = spark.sparkContext.textFile("file:///d:/study files/Spark/test/test01/order_items.csv").cache()
import spark.implicits._
val uss = users.map(line=>{
val e = line.replaceAll("\"","").split(",");
Userinfos(e(0),e(1),e(2),e(3),e(4),e(5),e(6),e(7),e(8))}).toDS()
val orders = ords.map(line=>{
val e = line.replaceAll("\"","").split(",");
Orders(e(0),e(1),e(2),e(3))}).toDS()
val products = pros.map(line=>{
val e = line.replaceAll("\"","").split(",");
Products(e(0),e(1),e(2),e(3),e(4))}).toDS()
val items = itms.map(line=>{
val e = line.replaceAll("\"","").split(",");
OrderItems(e(0),e(1),e(2),e(3),e(4),e(5))}).toDS()
//谁的消费额最高?
// items.groupBy("ordid").agg(sum("countPrice").as("cp"))
// .join(orders,"ordid").groupBy("userid").agg(sum("cp").as("cp"))
// .orderBy(desc("cp")).limit(1)
// .join(uss,"userid").show()
//哪个产品销量最高
// items.groupBy("proid").agg(sum("buynum").as("sum"))
// .orderBy(desc("sum")).limit(1).show()
val money = items.groupBy("ordid").agg(count($"buynum").as("buynum"))
val ordd = orders.select($"ordid",dayofweek($"orddate").as("zj"))
money.join(ordd,"ordid").groupBy("zj").agg(sum("buynum").as("bm")).show()
}
}
三、Spark DataFrame API
1、介绍
-
DataFrame (Spark 1.4+)
- DataFrame=Dataset[Row]
- 类似传统数据的二维表格
- 在RDD基础上加入了Schema(数据结构信息)
- DataFrame Schema支持嵌套数据类型
- struct
- map
- array
- 提供更多类似SQL操作的API
2、对比
- RDD与DataFrame对比
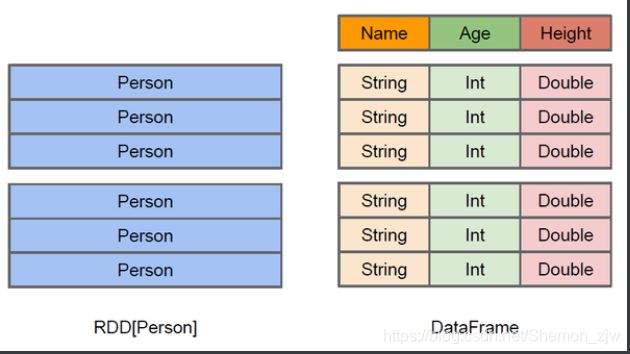
3、创建
object CreateDataFrame extends App {
//todo:1、创建一个SparkSession对象
val spark = SparkSession.builder().master("local[*]").appName("test01").getOrCreate()
//导包
import spark.implicits._
val sc = spark.sparkContext
private val jsontoDF: DataFrame = spark.read.json("src/data/people.json")
jsontoDF.show()
}
//输出
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
4、常用操作
- DataFrame API常用操作
val df = spark.read.json("file:///home/hadoop/data/people.json")
// 使用printSchema方法输出DataFrame的Schema信息
df.printSchema()
// 使用select方法来选择我们所需要的字段
df.select("name").show()
// 使用select方法选择我们所需要的字段,并未age字段加1
df.select(df("name"), df("age") + 1).show()
// 使用filter方法完成条件过滤
df.filter(df("age") > 21).show()
// 使用groupBy方法进行分组,求分组后的总数
df.groupBy("age").count().show()
//sql()方法执行SQL查询操作
df.createOrReplaceTempView("people")
spark.sql("SELECT * FROM people").show

5、RDD和DataFrame转换
- RDD->DataFrame
//方式一:通过反射获取RDD内的Schema
case class Person(name:String,age:Int)
import spark.implicits._
val people=sc.textFile("file:///home/hadooop/data/people.txt")
.map(_.split(","))
.map(p => Person(p(0), p(1).trim.toInt)).toDF()
people.show
people.createOrReplaceTempView("people")
val teenagers = spark.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
teenagers.show()
//方式二:通过编程接口指定Schema
case class Person(name:String,age:Int)
val people=sc.textFile("src/data/people.txt")
// 以字符串的方式定义DataFrame的Schema信息
val schemaString = "name age"
//导入所需要的类
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{
StructType, StructField, StringType}
// 根据自定义的字符串schema信息产生DataFrame的Schema
val schema = StructType(schemaString.split(" ").map(fieldName =>StructField(fieldName,StringType, true)))
//将RDD转换成Row
val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// 将Schema作用到RDD上
val peopleDataFrame = spark.createDataFrame(rowRDD, schema)
// 将DataFrame注册成临时表
peopleDataFrame.createOrReplaceTempView("people")
val results = spark.sql("SELECT name FROM people")
results.show
- DataFrame ->RDD
/** people.json内容如下
* {"name":"Michael"}
* {"name":"Andy", "age":30}
* {"name":"Justin", "age":19}
*/
val df = spark.read.json("src/data/people.txt")
//将DF转为RDD
df.rdd.collect
- 创建表
object RDDToDataFrame2 extends App {
val spark = SparkSession.builder().appName("mytest").master("local[3]").getOrCreate()
val sc = spark.sparkContext
import spark.implicits._
private val textRDD: RDD[Array[String]] = sc.textFile("src/data/people.txt").map(_.split(","))
//todo:定义scheme信息
private val schema = StructType(Array(
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
//todo: 把rdd转换成row
private val mapRDD: RDD[Row] = textRDD.map(x=>Row(x(0),x(1).trim.toInt))
//todo:把RDD转换成DataFrame
private val df1: DataFrame = spark.createDataFrame(mapRDD,schema)
df1.printSchema()
df1.show()
private val rddres: RDD[Row] = df1.rdd
println(rddres.collect().mkString(" "))
}
//输出结果
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
+--------+---+
| name|age|
+--------+---+
|zhangsan| 29|
| lisi| 30|
| wangwu| 19|
+--------+---+
[zhangsan,29] [lisi,30] [wangwu,19]
四、Spark SQL操作外部数据源
1、Parquet文件
- Parquet文件:是一种流行的列式存储格式,以二进制存储,文件中包含数据与元数据
object ParquetDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("mytest").master("local[3]").getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
val rdd1 = sc.parallelize(List(
("zhangsan","green",Array(3,5,6,9)),
("zhangsan",null,Array(3,5,6,10)),
("lisi","red",Array(3,5,6,33)),
("zhangsan2","green",Array(3,5,223,9)),
("zhangsan3","green",Array(3,43,44,9))
))
//todo:设置schema
val structType = StructType(Array(
StructField("name", StringType),
StructField("color", StringType),
StructField("numbers", ArrayType(IntegerType))
))
val worRdd = rdd1.map(p=>Row(p._1,p._2,p._3))
val df = spark.createDataFrame(worRdd,structType)
//TODO:读写
// df.write.parquet("src/data/user")
//todo:读取parquet格式文件
val parquetRDD = spark.read.parquet("src/data/user")
parquetRDD.printSchema()
parquetRDD.show()
// df.show()
}
}
2、集成hive
在hive中创建表:
#创建一个Hive表
hive>create table toronto(full_name string, ssn string, office_address string);
hive>insert into toronto(full_name, ssn, office_address) values('John S. ', '111-222-333 ', '123 Yonge Street ');
将hive-site.xml拖进spark的conf:然后添加配置:
<property>
<name>hive.metastore.uris</name>
<value>thrift://zjw:9083</value>
</property>
//集成Hive后spark-shell下可直接访问Hive表
val df=spark.table("toronto")
df.printSchema
df.show
scala> df.printSchema
root
|-- full_name: string (nullable = true)
|-- ssn: string (nullable = true)
|-- office_address: string (nullable = true)
scala> df.show
+---------+------------+-----------------+
|full_name| ssn| office_address|
+---------+------------+-----------------+
| John S. |111-222-333 |123 Yonge Street |
+---------+------------+-----------------+
将hive-site.xml拖进idea的resource里面
//IDEA中使用,需将hive-site.xml拷贝至resources
val spark = SparkSession.builder()
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
val df = spark.sql("select * from toronto")
df.filter($"ssn".startsWith("111")).write.saveAsTable("t1")
Spark SQL与Hive集成:
1、hive-site.xml拷贝至${SPARK_HOME}/conf下
2、检查hive.metastore.uris是否正确
3、启动元数据服务:$hive service metastore
object HiveonSparkDemo extends App {
val spark = SparkSession.builder()
.master("local[*]")
.appName("mytest")
.enableHiveSupport()
.config("hive.metastore.uris","thrift://192.168.253.150:9083")
.getOrCreate()
import spark.implicits._
val df = spark.sql("select * from mydemo.xxx")
// df.filter($"ssn".startsWith("111")).write.saveAsTable("t1")
df.printSchema()
df.show()
}
3、RDBMS表
$spark-shell --jars /opt/spark/ext_jars/mysql-connector-java-5.1.38.jar
//通过--jars指定MySQL驱动文件,需要下载
val url = "jdbc:mysql://localhost:3306/metastore"
val tableName = "TBLS"
// 设置连接用户、密码、数据库驱动类
val prop = new java.util.Properties
prop.setProperty("user","hive")
prop.setProperty("password","mypassword")
prop.setProperty("driver","com.mysql.jdbc.Driver")
// 取得该表数据
val jdbcDF = spark.read.jdbc(url,tableName,prop)
jdbcDF.show
//DF存为新的表
jdbcDF.write.mode("append").jdbc(url,"t1",prop)
scala> val url= "jdbc:mysql://zjw:3306/zjw"
url: String = jdbc:mysql://zjw:3306/zjw
scala> val prop = new java.util.Properties
prop: java.util.Properties = {}
scala> prop.setProperty("user","root")
res5: Object = null
scala> prop.setProperty("password","ok")
res6: Object = null
scala> prop.setProperty("driver","com.mysql.jdbc.Driver")
res7: Object = null
scala> spark.read.jdbc(url,"t1",prop)
2020-08-13 10:58:09 WARN HiveConf:2753 - HiveConf of name hive.server2.thrift.client.user does not exist
2020-08-13 10:58:09 WARN HiveConf:2753 - HiveConf of name hive.metastore.local does not exist
2020-08-13 10:58:09 WARN HiveConf:2753 - HiveConf of name hive.server2.thrift.client.password does not exist
res4: org.apache.spark.sql.DataFrame = [id: int, name: string]
scala> val df = spark.read.jdbc(url,"t1",prop)
df: org.apache.spark.sql.DataFrame = [id: int, name: string]
scala> df.show
+---+----+
| id|name|
+---+----+
| 1| zs|
| 2| ww|
+---+----+
object MysqlDemo extends App {
val spark = SparkSession.builder().master("local[*]").appName("mysql").getOrCreate()
val url = "jdbc:mysql://zjw:3306/zjw"
val tableName = "t1"
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","ok")
prop.setProperty("driver","com.mysql.jdbc.Driver")
//todo:spark连接mysql 读取mysql表中数据
private val frame: DataFrame = spark.read.jdbc(url,tableName,prop)
frame.show()
}