spark的累加器和自定义累加器详解
累加器:分布式共享只写变量。(Executor和Executor之间不能读数据)
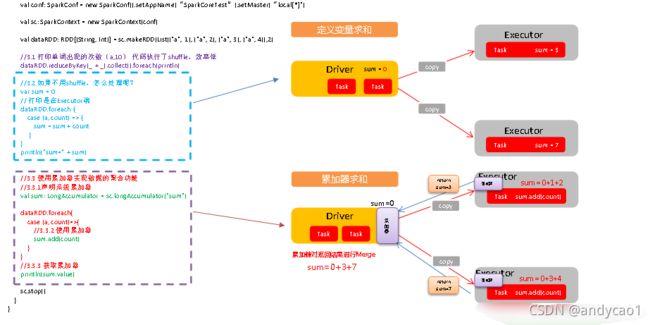
累加器用来把Executor端变量信息聚合到Driver端。在Driver中定义的一个变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行合并计算。
累加器使用
(1)累加器定义(SparkContext.accumulator(initialValue)方法)
val sum: LongAccumulator = sc.longAccumulator("sum")
(2)累加器添加数据(累加器.add方法)
sum.add(count)
(3)累加器获取数据(累加器.value)
sum.value
注意:Executor端的任务不能读取累加器的值(例如:在Executor端调用sum.value,获取的值不是累加器最终的值)。因此我们说,累加器是一个分布式共享只写变量。
累加器要放在行动算子中
因为转换算子执行的次数取决于job的数量,如果一个spark应用有多个行动算子,那么转换算子中的累加器可能会发生不止一次更新,导致结果错误。所以,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach()这样的行动算子中。
对于在行动算子中使用的累加器,Spark只会把每个Job对各累加器的修改应用一次
自定义累加器
自定义累加器类型的功能在1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。
1)自定义累加器步骤
(1)继承AccumulatorV2,设定输入、输出泛型
(2)重写6个抽象方法
(3)使用自定义累加器需要注册::sc.register(累加器,"累加器名字")
