三-1,使用 Java 操作 HBase API
文章目录
- 三, HBase API 入门
-
- 3.1 API 基本使用
-
- 3.1.0 环境准备
- 3.1.1 HBase API-->DDL操作
-
- 1. 判断hbase中的某张表是否存在(admin.tableExists(TableName)) && 获取Configuration 对象 + 获取 HBaseAdmin 对象
- 1.1 改进上一节-->静态代码块的恰当应用
- 2. 创建表(admin.createTable(tableName, cf))
- 3. 创建命名空间
- 3.1.2 HBase API-->DML操作
-
- 1. 向表中插入一行数据(put)
- 2. 获取一行数据或多行数据(get)
- 3. 获取表的所有数据(scan)
- 4. 删除表中的数据
三, HBase API 入门
3.1 API 基本使用
3.1.0 环境准备
-
引入HBase 相关的依赖
- habse-server, hbase-client
<dependencies>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>2.3.7version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>2.3.7version>
dependency>
dependencies>
3.1.1 HBase API–>DDL操作
1. 判断hbase中的某张表是否存在(admin.tableExists(TableName)) && 获取Configuration 对象 + 获取 HBaseAdmin 对象
- 获取conf对象(作为客户端实例化对象的参数) + 获取对表进行访问和修改的 HBaseAdmin 客户端;
public class connecTest{
public static boolean isTableExists(String tableName)){
//1. 创建Configuration 对象, 设置一些必要的参数
//HBaseConfiguration conf = new HBaseConfiguration(); //过时
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "bigdata01,bigdata02,bigdata03")
//2. 获取HBaseAdmin 对象, 通过hbaseAdmin 对象完成对表的访问和修改
// HBaseAdmin admin = new HBaseAdmin(configuration); //过时
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
//3. 判断表是否存在
boolean exist = admin.tableExists(TableName.valueOf(tableName));
//4. 关闭连接
admin.close();
return exist;
}
}
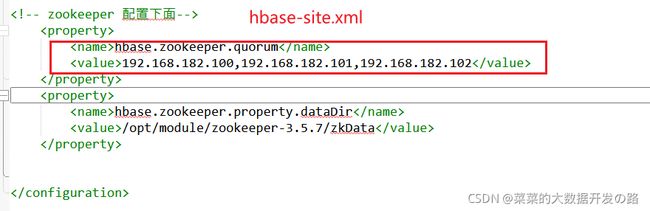
用API连接HBase, configuration对象的必须参数–
hbase.zookeeper.quorum
1.1 改进上一节–>静态代码块的恰当应用
为了方便使用, 通常把初始化连接放在静态代码块中, 关闭资源也由此设置为一个独立的方法
为什么关闭资源有必要设置为独立方法? 因为在静态代码块中我们初始化了连接和admin对象, 在下面的几个方法中都是共用这些对象, 需要统一等这些方法运行完毕后, 再去调用我们独立出的close(), 关闭 connec 对象和 admin 对象;
/**
手撕顺序:
1. 静态代码块初始化配置, 初始化连接, 补齐缺失的全局变量;
2. 把关闭资源(connection 和 admin 对象)独立为一个方法
3. 利用admin对表进行的一系列操作
4. main方法中调用3, 然后调用2, 关闭资源;
**/
package cn.xxx;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
public class StaticConnecTest {
// 配置对象和admin对象
static Admin admin = null;
static Connection connection = null;
//初始化连接(创建配置对象, 创建客户端对象(admin))
static{
//配置对象
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","bigdata01,bigdata02,bigdata03");
//创建连接, 传入配置对象, 获取admin对象
try {
Connection connection = ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
//把关闭资源独立设为一个方法
public static void close(){
if(admin != null){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(connection != null){
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static boolean isExists(String tableName) throws IOException {
//连接connec已初始化, admin对象也已经初始化
boolean b = admin.tableExists(TableName.valueOf(tableName));
return b;
}
public static void main(String[] args) throws IOException {
//判断表是否存在
System.out.println("在hbase中表'person' 是否存在? -->" + StaticConnecTest.isExists("person"));
//关闭资源
StaticConnecTest.close();
}
}
2. 创建表(admin.createTable(tableName, cf))
HBase 2.0 以后使用HTableDescriptor与HColumnDescriptor时提示不推荐使用了,并且在3.0.0版本将删除,而是使用TableDescriptorBuilder和ColumnFamilyDescriptorBuilder
// 表名
String TABLE_NAME = "WATER_BILL";
// 列蔟名
String COLUMN_FAMILY = "C1";
// 1. 判断表是否存在
if(admin.tableExists(TableName.valueOf(TABLE_NAME))) {
return;
}
// 2. 构建表描述构建器
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(TABLE_NAME));
// 3. 构建列蔟描述构建器
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(COLUMN_FAMILY));
// 4. 构建列蔟描述
ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build();
// 5. 构建表描述
// 添加列蔟
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
// 6. 创建表
admin.createTable(tableDescriptor);
来个稍微复杂点的, 跟上面的简化版不同在于, 传入的列族是一个string数组, 需要借助list存储列族描述构建器
public static void createTable(String tableName, String[] columnFamily) throws IOException {
//0. 判断列族是否传入
if(columnFamily.length < 0){
System.out.println("请设置相应的列族!");
return;
}
//1. 判断表是否存在
if(isExists(tableName)){
System.out.println("表"+tableName+"已经存在了. 创建失败.");
}else{
/创建表的关键流程
//0. 把外界传入的表名进行处理, 转为TableName对象
// 为什么处理? 感觉像是包装类的装箱, 我也没搞懂.. 先死记
TableName table = TableName.valueOf(tableName);
//2. 创建表描述构造器( TableDescriptorBuilder.newBuilder())
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(table);
//3. 创建列族描述构造器(ColumnFamilyDescriptorBuilder.newBuilder()) + 构造列族 ( xx.build())
// 3.1. 新建一个列族集合 cfList, 用于遍历传入的字符串数组, 把传入的cf转为字节数组后, 直接传入列族的构造器, 构造出列族描述对象
List<ColumnFamilyDescriptor> cfList = new ArrayList<>();
for(String cf : columnFamily){
//构建列族( 列族构造器对象.new Builder(列族字节数组).build() )
ColumnFamilyDescriptor cFDescriptor = ColumnFamilyDescriptorBuilder.newBuilder(cf.getBytes()).build();
cfList.add(cFDescriptor);
}
//5. 构建表
TableDescriptor tableDescriptor = tableDescriptorBuilder.setColumnFamilies(cfList).build();
//4. 创建表
admin.createTable(tableDescriptor);
}
3. 创建命名空间
//5. 创建命名空间
public static void createNS(String ns){
// 1. 创建命名空间描述器
NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create(ns).build();
try {
//2. 创建命名空间
//如果命名空间已经存在, 这里就会发生异常
admin.createNamespace(namespaceDescriptor);
} catch(NamespaceExistException e){
System.out.println("命名空间"+ns+"已经存在了");
} catch(IOException e) {
e.printStackTrace();
}
}
3.1.2 HBase API–>DML操作
1. 向表中插入一行数据(put)
- 在shell中, 获取一行数据的指令为:
>put '表名', 'rowKey', '列族CF:列CN', 'value' - 同样的, 在API中, 我们也需要给方法传入上述参数, 并在获取表对象之后, 获取put对象, 并利用put对象的相关方法, 取得传入的rowkey, cf,cn等参数, 然后使用表对象.put(put对象)即可.
Q: HBase如何获取表对象table? connection.getTable(TableName) (connection是Connection的实例对象), 这是专门用于管理表中数据(DML)的类, 而前面提到的 connection.getAdmin()是对表操作(DDL)的对象
Q: 如何获取Put对象? new Put(传入Rowkey)
//往表中插入一行数据
public static void putData(String table, String rowKey, String cf, String cn, String value) throws IOException {
//0. 转换为TableName 对象
TableName tn = TableName.valueOf(table);
//1. 获取表对象
Table tb = connection.getTable(tn);
//3. 由2知需要put对象, new一个呗
Put putObj = new Put(Bytes.toBytes(rowKey));
//4. 给put对象赋值
putObj.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn),Bytes.toBytes(value));
//2.插入数据
tb.put(putObj);
//关闭表连接
tb.close();
}
2. 获取一行数据或多行数据(get)
//从表中取出一行数据
public static void getData(String tableName, String rowKey, String cf, String cn) throws IOException {
//0. 装箱
TableName table = TableName.valueOf(tableName);
//1. 获取表对象
Table tb = connection.getTable(table);
//3. new 一个get对象
Get get = new Get(Bytes.toBytes(rowKey));
//2. 获取指定rowkey的数据
Result result = tb.get(get);
//2-1. 我们还可以获取某个列族的这个rowkey对应的值
get.addFamily(Bytes.toBytes(cf));
//2-2 当然我们也可以进一步指定某一列族下的某一列
get.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn))
//2-3. 我们也可以对获取到的数据进行版本控制(被废弃了, 不说了)
//4. 对Result进行解析
for (Cell cell : result.rawCells()) {
//5.
//利用CellUtil.clonexx() 得到各个属性的值
String rw = Bytes.toString(CellUtil.cloneRow(cell));
String cf = Bytes.toString( CellUtil.cloneFamily(cell));
String cn = Bytes.toString( CellUtil.cloneQualifier(cell));
String val = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(
"rowKey: "+ rw + ","+ cf+":"+ cn + ", value="+val
);
//6. 关闭表的连接
tb.close();
}
3. 获取表的所有数据(scan)
public static void scan(String tableName) throws IOException {
//0. 转为TableName类
TableName table = TableName.valueOf(tableName);
//1. 获取表对象
Table tb = connection.getTable(table);
//2.获取扫描相关的类
Scan sc = new Scan();
ResultScanner resultScanner = tb.getScanner(sc);
//3. 解析resultScanner
for (Result result : resultScanner) {
for (Cell cell : result.rawCells()) {
//5.
//利用CellUtil.clonexx() 得到各个属性的值
String rw1 = Bytes.toString(CellUtil.cloneRow(cell));
String cf1 = Bytes.toString( CellUtil.cloneFamily(cell));
String cn1 = Bytes.toString( CellUtil.cloneQualifier(cell));
String val = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(
"rowKey: "+ rw1 + ","+ cf1+":"+ cn1 + ", value="+val
);
}
}
}
4. 删除表中的数据
//删除表中的一行数据
public static void deleteData(String tableName, String rowKey, String cf, String cn) throws IOException {
//1. 获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//3. 实例化delete,由于hbase都是对字节数组进行操作, 所以rowkey要转为字节数组
Delete delete = new Delete(Bytes.toBytes(rowKey));
//3-1, 根据列族, 列名进一步的删除数据
//
// //删除当前rowkey, cf:cn的最新版本, 旧版本数据不删除, 慎用, 容易导致刷写前后数据不一致问题
// delete.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn));
delete.addColumns(Bytes.toBytes(cf), Bytes.toBytes(cn));//删除本rowkey, cf:cn的所有数据版本
//2. 进行删除, 发现需要delete对象, new 一个呗
table.delete(delete);
System.out.println("删除已完成!");
table.close();
}
拓展:
在HBase的删除API或是Shell命令中, 使用不同参数的删除命令, 会在历史版本数据scan '表名', {RAW=true,VERSIONS=5}中留下不同的标记;
[deleteFamily]-删除列族:
-
在shell命令中,
deleteall '表名','rowkey'或者deleteall '表名','rowkey', '列族'用于删除某一 rowkey对应的所有数据(多版本删除)
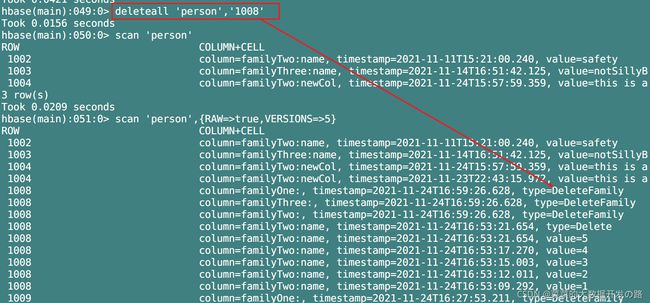
-
类似的, 当JavaAPI中, 如果仅为自定义的删除方法传入tableName和rowkey, 也会产生跟上面一样的标志.(多版本删除)
[deleteColumn]- 删除列:
- 在Java API中, 如果我们给自定义的删除方法传入列族和列名, 通过实例化Delete对象后, 利用
对象.addColumns(Bytes.toBytes(cf), Bytes.toBytes(cn), 可以删除rowkey相同时, 所有版本的数据都将会被删除, 并且会产生’deleteColumn’标记.(多版本删除)

[delete]-删除单元格
-
在shell命令中,
delete '表名','rowkey', '列族:列'用于删除某一 rowkey对应的所有数据,
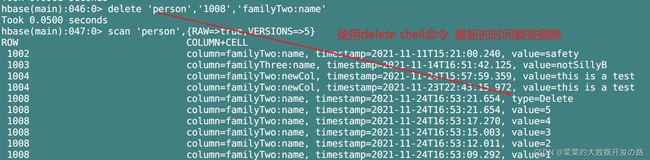
-
类似的, 当JavaAPI中, 如果我们给自定义的删除方法传入列族和列名, 通过实例化Delete对象后, 利用
对象.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn), 可以删除给定rowkey的最新时间戳的数据;