hadoop伪分布式环境搭建
hadoop伪分布式环境搭建
- 一、修改主机名,IP映射
-
-
- 修改主机名
- 修改IP映射
-
- 二、安装jdk
- 三、安装hadoop
- 四、配置hadoop
-
-
- 修改slaves
- 修改hadoop-env.sh
- 配置core-site.xml
- 配置hdfs-site.xml
- 配置mapred-site.xml
- 配置yarn-site.xml
- 关闭防火墙
- 格式化
- 启动hadoop
-
一、修改主机名,IP映射
为了在集群管理中,能够方便的对各个节点进行管理,进行批处理操作,所以需要修改主机名,同时因为很少有公司提供域名解析器,所以需要配置IP映射。
修改主机名
sudo vim /etc/sysconfig/network
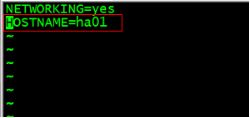
但是修改配置文件后,并不能使其立即生效
解决办法:
重启(服务器上不推荐使用)
sudo hostname 主机名,然后退出重新登录
修改IP映射
sudo vim /etc/hosts

二、安装jdk
1、使用wget命令或直接从Windows系统上传jdk压缩包到Linux;

2、解压jdk压缩包,即可完成jdk的安装
tar -zxvf jdk-7u65-linux-i586.tar.gz -C ~/app/

3、配置java环境变量
sudo vim /etc/profile
在profile文件最后添加上JAVA_HOME

要使配置文件生效,需要执行source /etc/profile重新读取配置文件
三、安装hadoop
1、使用wget命令或直接从Windows系统上传hadoop压缩包到Linux;
2、解压hadoop压缩包,即可完成hadoop的安装
tar -zxvf hadoop-2.4.1.tar.gz -C ../app/
3、配置hadoop环境变量
sudo vim /etc/profile
在profile文件最后添加上HADOOP_HOME

修改完毕后,同样需要执行source /etc/profile重新读取配置文件
四、配置hadoop
进入hadoop安装目录下的etc目录
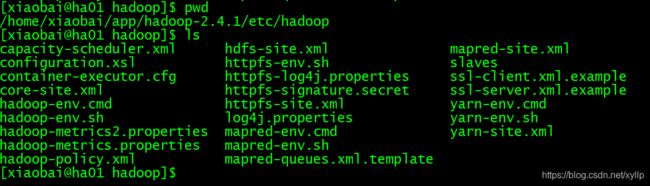
修改slaves
因为start-dfs.sh脚本启动NameNode后,需要读取slaves文件,从而知道需要启动的DataNode在哪些主机上;start-yarn.sh脚本启动resourcemanager后,需要读取slaves文件,从而知道需要启动的nodemanager在哪些主机上;
所以需要在slaves文件中加入节点的主机名,主机名列表按行分隔
主机名1
主机名2
.....
在slaves文件中加入本节点主机名
vim slaves

修改hadoop-env.sh
因为可能会因为各种原因获取系统环境变量中的JAVA_HOME时发生错误,所以直接指定JAVA_HOME位置:
vim hadoop-env.sh

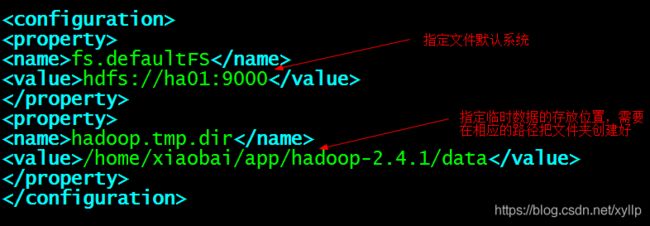
配置core-site.xml
vim core-site.xml
---------------------------------------
fs.defaultFS
hdfs://ha01:9000
hadoop.tmp.dir
/home/xiaobai/app/hadoop-2.4.1/data
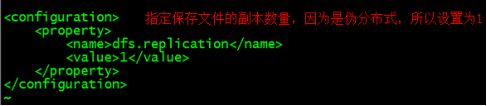
配置hdfs-site.xml
vim hdfs-site.xml
---------------------------------------
dfs.replication
1
配置完这core-site.xml和hdfs-site.xml后,ha就可以运行了,但是无法使用yarn和MapReduce功能
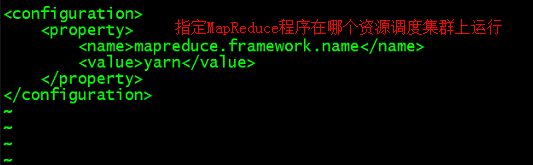
配置mapred-site.xml
配置文件夹下,是没有mapred-site.xml文件的,所以需要将mapred-site.xml.template重命名为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
---------------------------------------
mapreduce.framework.name
yarn
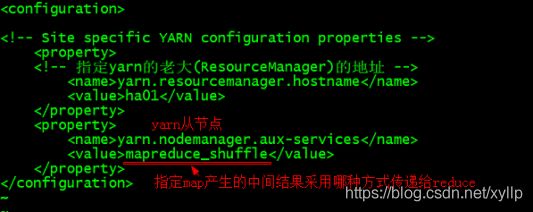
配置yarn-site.xml
vim yarn-site.xml
---------------------------------------
yarn.resourcemanager.hostname
ha01
yarn.nodemanager.aux-services
mapreduce_shuffle
关闭防火墙
因为ha是通过网络监听进行通信的,所以需要打开相应的端口。一般在公司内网进行ha的部署,所以可以采用关闭防火墙的方式来代替打开相应端口的操作。
sudo chkconfig iptables off

格式化
第一次运行hadoop需要进行格式化,以后运行hadoop不需要再进行格式化。
hdfs namenode -format
在运行结果中找到successfully formatted表示格式化成功
启动hadoop
不推荐使用start-all.sh启动所有,而是一个组件一个组件的启动
启动hdfs:
start-dfs.sh
启动yarn:
start-yarn.sh
因为hadoop启动NameNode和DataNode时采用的是远程登录到目标主机,然后运行启动命令,所以每次启动时,都会要求输入密码。可以通过配置ssh免密登录来解决该问题。
其实,伪分布式的免密登录,就是请求主机和目标主机都是本机的情况。所以直接将本机的公钥追加到 authorized_keys文件即可实现无密登录