HBase
- HBase是Apache提供的开源的非关系型数据库。
- HBase的底层存储是基于Hadoop,是一个分布式,可扩展,大数据库数据库
- HBase能够实时读写大量的数据。单张表就可以做到10亿*百万列数据量的级别。
- Hbase是一个NOSQL(not only sql)的数据库。
- HBase是由Doug带领团队开发的。仿照了Google的
- HBase在存储的时候是采用了列存储的思想。

Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables – billions of rows X millions of columns – atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google’s Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
行存储和列存储
- 行存储在磁盘上的存储是连续的;列存储在磁盘上的存储是不连续的
- 从写入性能上对比,写入次数越少性能越高。因为针对磁盘的每一次写入,都要发生磁头调度,产生寻道时间。因为行存储是只写一次而列存储要写多次,所以行存储在写入性能上更有优势
- 从读取性能上对比:
a. 如果读取的是整表,则行存储性能较高
b. 如果是读取指定的列,则行存储会产生冗余列,而冗余列的消除是在内存中发生。而列存储则不会存在冗余列 - 在存储数据的时候,如果基于行存储,由于一行数据的字段类型可能不同,所以会产生频繁的数据类型转换;如果是基于列存储,由于同一列数据的类型一般一致,则可以避免频繁的数据类型转换,同时可以考虑一些更好的压缩算法对一列数据进行压缩
特点
- 分布式架构:HBASE是通过集群来存储数据,数据最终要落地到HDFS上
- 是一种NoSQL的非关系型数据库,不符合关系型数据库的范式
- 面向列存储,底层基于key-value结构
- 适合存储半结构化、非结构化的数据
- 适合存储稀疏的数据,空的数据不占用空间
- 提供实时的增删改查的能力,但是不提供严格的事务机制,只能在行级别提供事务
关系型和非关系性数据库
1. 传统关系型数据库的缺陷:
a. 高并发读写的瓶颈:Web 2.0网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用静态化技术,因此数据库并发负载非常高,可能峰值会达到每秒上万次读写请求。关系型数据库应付上万次SQL查询还勉强顶得住,但是应付上万次SQL写数据请求,硬盘I/O却无法承受。其实对于普通的BBS网站,往往也存在相对高并发写请求的需求,例如,人人网的实时统计在线用户状态,记录热门帖子的点击次数,投票计数等,这是一个相当普遍的业务需求
b. 可扩展性的限制:在基于Web的架构中,数据库是最难以进行横向扩展的,当应用系统的用户量和访问量与日俱增时,数据库系统却无法像Web Server和App Server那样简单地通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移,而不能通过横向添加节点的方式实现无缝扩展
c. 事务一致性的负面影响:事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。保证数据库一致性是指当事务完成时,必须使所有数据都具有一致的状态。在关系型数据库中,所有的规则必须应用到事务的修改上,以便维护所有数据的完整性,这随之而来的是性能的大幅度下降。很多Web系统并不需要严格的数据库事务,对读一致性的要求很低,有些场合对写一致性要求也不高。因此数据库事务管理成了高负载下的一个沉重负担
d. 复杂SQL查询的弱化:任何大数据量的Web系统都非常忌讳几个大表间的关联查询,以及复杂的数据分析类型的SQL查询,特别是SNS类型的网站,从需求以及产品设计角度就避免了这种情况的产生。更多的情况往往只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能被极大地弱化了,所以这部分功能不能得到充分发挥
2. NoSQL数据库的优势:
a. 扩展性强:NoSQL数据库种类繁多,但是一个共同的特点就是去掉关系型数据库的关系特性,数据之间是弱关系,非常容易扩展。一般来说,NoSql数据库的数据结构都是Key-Value字典式存储结构。例如,HBase、Cassandra等系统的水平扩展性能非常优越,非常容易实现支撑数据从TB到PB级别的过渡
b. 并发性能好:NoSQL数据库具有非常良好的读写性能,尤其在大数据量下,同样表现优秀。当然这需要有优秀的数据结构和算法做支撑
c. 数据模型灵活:NoSQL无须事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系型数据库中,增删字段是一件非常麻烦的事情。对于数据量非常大的表,增加字段简直就是一场噩梦。NoSQL允许使用者随时随地添加字段,并且字段类型可以是任意格式。
基本概念
- HBase以表的形式存储数据。表有行和列族组成。列族划分为若干个列。其结构如下:

Row Key:行键
- hbase本质上也是一种Key-Value存储系统。Key相当于RowKey,Value相当于列族数据的集合
- 与nosql数据库们一样,row key是用来检索记录的主键
- 访问hbase table中的行,只有三种方式:
a. 通过单个row key访问
b. 通过row key的range
c. 全表扫描 - Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,row key保存为字节数组
- 存储时, 数据按照Rowkey的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
列族(列簇)
- hbase表中的每个列,都归属与某个列族
- 列族是表的schema的一部分(而列不是),列族必须在使用表之前定义
- 列名都以列族作为前缀。例如courses:history , courses:math 都属于 courses 这个列族
- 访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助管理不同类型的应用:允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。
- 开发过程中,一般建议 列族的数量不要超过3个。不建议跨列族查询。
Cell与时间戳
- 由{row key, column( = + < label>), version} 唯一确定的单元
- cell中的数据是没有类型的,全部是字节码形式存贮
- 每个 cell都保存着同一份数据的多个版本,版本通过时间戳来索引
- 时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值
- 如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳
- 每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面
- 为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式:
a. 保存数据的最后n个版本
b. 保存最近一段时间内的版本(比如最近七天)
用户可以针对每个列族进行设置
启动HBase
-
conf下
vim hbase-env.sh
export JAVA_HOME=/home/presoftware/jdk1.8
export HBASE_MANAGES_ZK=false
修改后
source hbase-env.sh -
vim hbase-site.xml
<property>
<name>hbase.rootdirname>
<value>hdfs://hadoop01:9000/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181value>
property>
- vim regionservers
修改内容为三台服务器的名称
hadoop01
hadoop02
hadoop03
启动三个ZooKeeper
cd /home/software/zookeeper-3.4.8/bin/
sh zkServer.sh start
-
启动hadoop(可以是伪分布式)
-
启动第一个节点的hbase
bin下
sh start-hbase.sh
启动后,集群会自动启动另外两个节点
[root@hadoop01 bin]# sh start-hbase.sh
starting master, logging to /home/software/hbase-0.98.17-hadoop2/bin/../logs/hbase-root-master-hadoop01.out
hadoop02: starting regionserver, logging to /home/software/hbase-0.98.17-hadoop2/bin/../logs/hbase-root-regionserver-hadoop02.out
hadoop03: starting regionserver, logging to /home/software/hbase-0.98.17-hadoop2/bin/../logs/hbase-root-regionserver-hadoop03.out
hadoop01: starting regionserver, logging to /home/software/hbase-0.98.17-hadoop2/bin/../logs/hbase-root-regionserver-hadoop01.out
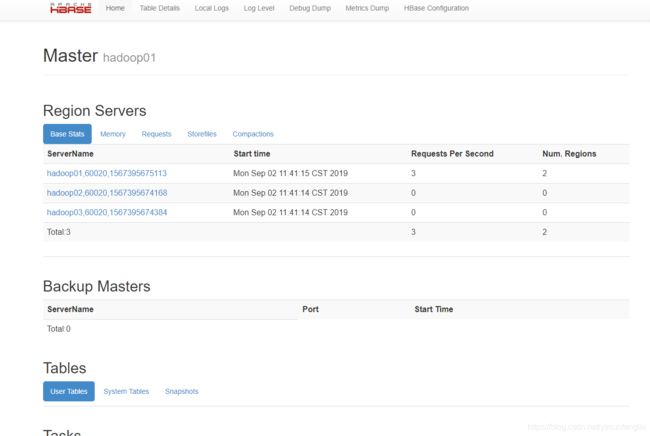
启动后访问此地址
http://hadoop01:60010/master-status
连接HBase客户端
支持的数据类型是字符串和整数
sh hbase shell
-
创建表
create ‘person’,{NAME=>‘basic’},{NAME=>‘info’} -
简写建表
create ‘student’,‘basic’,‘info’ -
列出表
list -
描述person表
desc ‘person’
如果要删除一个表,首先要禁边个表才能进行删除
- 禁用表
disable ‘person’
-删除表
drop ‘table’
| 指令 | 说明 | 示例 |
|---|---|---|
| create | 创建表,t1指表名,c1,c2 列族名,默认是在default空间下 | create ‘tab1’,‘colfamily1’,‘colfamily2’ |
| list | 查看一共有哪些表 | list |
| put | t1指表名,r1指行键名,c1指列名,value指单元格值。ts1指时间戳,一般都省略掉了。注意,行键名在一张表里要全局唯一 | put ‘tab1’,‘row-1’,‘colfamily1:co11’,‘aaa’ put ‘tab1’,‘row-1’,‘colfamily1:co12’,‘bbb’ put ‘tab1’,‘row-1’,‘colfamily2:co11’,‘ccc’ put ‘tab1’,‘row-1’,‘colfamily2:co12’,‘ddd’ |
| get | 根据表名和行键查询 | get ‘tab1’,‘row-1’ get ‘tab1’,‘row-1’,‘colfamily1’ get ‘tab1’,‘row-1’,‘colfamily1’,‘colfamily2’ get ‘tab1’,‘row-1’,‘colfamily1:co11’ |
| scan | 扫描所有数据,也可以跟指定条件 scan ‘tab1’ #扫描整表数据,会查询出所有的行数据 | scan ‘tab1’,{COLUMNS=>[‘colfamily1’]} scan ‘tab1’,{COLUMNS=>[‘cf1:name’]} scan ‘tab1’,{COLUMNS=>[‘cf1:name’,‘cf2:salary’]} scan ‘tab1’,{COLUMNS=>[‘colfamily1’,‘colfamily2’]} scan ‘tab1’,{RAW=>true,VERSIONS=>3} 可以在查询时加上RAW=>true来开启对历史版本数据的查询,VERSIONS=>3指定查询最新的几个版本的数据 |
| deleteall | 根据表名、行键删除整行数据 | deleteall ‘tab1’,‘row-1’ |
| drop | 删除表,前提是先禁用表 | drop ‘tab1’ |
| disable | 禁用表 | disable ‘tab1’ |
| create | 指令补充 建表时可以指定VERSIONS,配置的是当前列族在持久化到文件系统中时,要保留几个最新的版本数据,这并不影响内存中的历史数据版本 | create ‘tab1’,{NAME=>‘c1’,VERSIONS=>3},{NAME=>‘c2’,VERSIONS=>3} |
| exit | 推出shell客户端 | exit |
| enable | 启用表 | enable ‘tab1’ |
| 命令 | 说明 |
|---|---|
| create_namespace ‘hbasedemo’ | 创建命名空间hbasedemo |
| create ‘hbasedemo:person’,‘basic’,‘info’ | 在hbasedemo命名空间中创建表person; |
| drop_namespace ‘hbasedemo’ | 删除命名空间 |
| list_namespace | 列出命名空间 |
| put ‘person’,‘p1’,‘basic:name’,‘Amy’ | 行键是唯一的,放入一个basic列族name列为Amy的数据,行键p1 |
| list ‘hbase’ | 列出hbase下的表 |
| put ‘person’,‘p1’,‘basic:name’,‘amy’ | 向person表,p1记录,basic列族name列加入amy |
| get ‘person’,‘p1’ | 获取person表中行键为p1的数据 |
| get ‘person’,‘p1’,‘basic’ | 获取person表中行键为p1的basic列族的数据 |
| get ‘person’,‘p1’,‘basic:name’,‘info:addr’ | 取两列 |
| delete ‘person’,‘p2’,‘info:phone’ | 删除info列族的phone列p2的数据 |
| delete ‘person’,‘p2’,'info | 删除info列族的p2的数据 |
| deleteall ‘person’,‘p2’ | 删除person表p2的数据 |
| scan ‘person’ | 浏览person表的数据 |
| scan ‘person’,{COLUMNS=>[‘basic’]} | 获取person表中basic列族的数据 |
Hbase提供了完整的增删改查的能力,然而HBase底层是基于HDFS存储(HDFS是一次写入多次读取),那HBase的改的能力是如何实现?
在HBase中,会对添加的每一条数据来增加一个字段(时间戳),在Hbase中进行查找的时候,如果不指定,默认找的是最新的。这也就意味着,改的能力并不是修改原始数据,而是在文件的尾部追加数据,因为获取的是最新的数据,所以看起来像是修改。这个时间戳作为版本
关闭hbase
这个命令一般不起效。如果需要关闭hbase那么需要通过kill的方式去关闭进程。
sh stop-hbase.sh
实际情况下会自定义一个shell脚本的方式去关闭hbase
Cell
行键加列加时间戳锁定的唯一数据叫作cell单元。
在HBase中,如果不指定 ,每一个列族只允许获取1个版本的数据。在获取的时候也只能拿一个版本。如果需要拿多个版本的数据,那么在建表的时候就需要指定允许获取的版本个数。
Api操作
package demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class HBaseDemo {
private Configuration conf;
//建表
@Before
public void conn(){
//连接hbase
//获取配置
conf= HBaseConfiguration.create();
//设置连接
conf.set("hbase.zookeeper.quorum","10.42.150.237,10.42.166.167,10.42.79.132");
}
@Test
public void createTable() throws IOException {
//连接HBase,获取管理权限
HBaseAdmin admin=new HBaseAdmin(conf);
//创建一个表描述器
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("student2"));
//指定列族
HColumnDescriptor f1=new HColumnDescriptor("basic");
HColumnDescriptor f2=new HColumnDescriptor("info".getBytes());
hTableDescriptor.addFamily(f1);
hTableDescriptor.addFamily(f2);
admin.createTable(hTableDescriptor);
admin.close();
}
@Test
//添加数据(修改数据)
public void putData() throws IOException {
//获取表
HTable table=new HTable(conf, TableName.valueOf("student2"));
//创建一个put对象
Put put=new Put("s1".getBytes());
put.add("basic".getBytes(),"id".getBytes(),"s1".getBytes());
put.add("basic".getBytes(),"name".getBytes(),"sam".getBytes());
//添加数据
table.put(put);
}
@Test
public void putMillonData() throws IOException {
long begin=System.currentTimeMillis();
//获取表
HTable table=new HTable(conf, TableName.valueOf("student2"));
List<Put> puts=new ArrayList<>();
for (int i=0;i<1000000;i++){
Put put=new Put(("s"+i).getBytes());
put.add("basic".getBytes(), "id".getBytes(), ("no"+i).getBytes());
puts.add(put);
if(puts.size()>=1000){
table.put(puts);
puts.clear();
}
}
table.close();
long end=System.currentTimeMillis();
System.out.println(end-begin);
}
//删除数据
@Test
public void deleteData() throws IOException {
HTable table=new HTable(conf, "student2");
Delete delete=new Delete("s2".getBytes());
table.delete(delete);
table.close();
}
//获取单个数据
@Test
public void getData() throws IOException {
HTable table=new HTable(conf, "student2");
Get get=new Get("s3".getBytes());
// get.addColumn();
// get.addFamily();
//获取数据
Result result=table.get(get);
byte[] data=result.getValue("basic".getBytes(), "id".getBytes());
System.out.println("取到数据:"+new String(data));
table.close();
}
//获取多条数据
@Test
public void scanData() throws IOException {
HTable table=new HTable(conf, "student2");
//1无参构造,则扫描全表。2从指定的行键扫描到最后。3指定起止行键
//注意行键是按字典序排序。
Scan scan = new Scan("s999990".getBytes(),"s999999".getBytes());
ResultScanner rs = table.getScanner(scan);
//将ResultScanner转化为一个迭代器
Iterator<Result> iterator = rs.iterator();
while(iterator.hasNext()){
Result next = iterator.next();
byte[] data=next.getValue("basic".getBytes(), "id".getBytes());
System.out.println("取到数据:"+new String(data));
}
}
//删除表
@Test
public void dropTable() throws IOException {
//获取管理权
HBaseAdmin admin=new HBaseAdmin(conf);
//禁用表
admin.disableTable(TableName.valueOf("student2"));
//删除表
admin.deleteTable(TableName.valueOf("student2"));
//关流
admin.close();
}
//过滤
@Test
public void regex() throws IOException {
HTable table=new HTable(conf, "student2");
Scan scan=new Scan();
Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator(".*22222.*"));
scan.setFilter(filter);
ResultScanner rs = table.getScanner(scan);
Iterator<Result> iterator = rs.iterator();
while(iterator.hasNext()){
Result next = iterator.next();
byte[] data=next.getValue("basic".getBytes(), "id".getBytes());
System.out.println("取到数据:"+new String(data));
}
}
}