目标检测之yolo系列
YOLO v.s Faster R-CNN
1.统一网络:YOLO没有显示求取region proposal的过程。Faster R-CNN中尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络.相对于R-CNN系列的"看两眼"(候选框提取与分类),YOLO只需要Look Once.
2. YOLO统一为一个回归问题,而R-CNN将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
YOLOv1
论文下载:http://arxiv.org/abs/1506.02640
代码下载:https://github.com/pjreddie/darknet
核心思想:将整张图片作为网络的输入(类似于Faster-RCNN),直接在输出层对BBox的位置和类别进行回归。
实现方法
- 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。
- 每个网络需要预测B个BBox的位置信息和confidence(置信度)信息,一个BBox对应着四个位置信息和一个confidence信息。confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息:
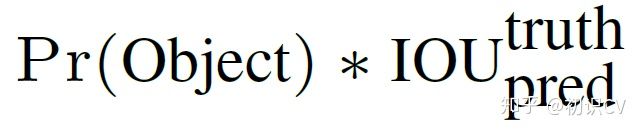
其中如果有object落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。
- 每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。(注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。)
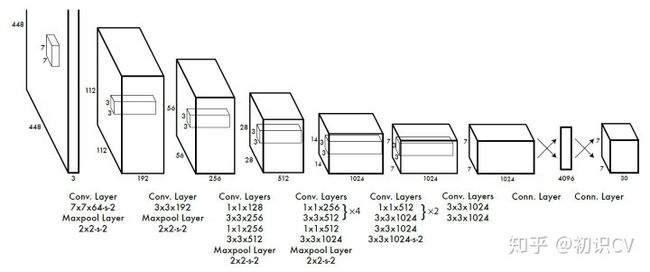
- 举例说明: 在PASCAL VOC中,图像输入为448x448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。整个网络结构如下图所示:
- 在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:

等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。
- 得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
简单的概括就是:
(1) 给个一个输入图像,首先将图像划分成7*7的网格
(2) 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)
(3) 根据上一步可以预测出7*7*2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可
损失函数
在实现中,最主要的就是怎么设计损失函数,让这个三个方面得到很好的平衡。作者简单粗暴的全部采用了sum-squared error loss来做这件事。
这种做法存在以下几个问题:
- 第一,8维的localization error和20维的classification error同等重要显然是不合理的;
- 第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
解决办法:
- 更重视8维的坐标预测,给这些损失前面赋予更大的loss weight。
- 对没有object的box的confidence loss,赋予小的loss weight。
- 有object的box的confidence loss和类别的loss的loss weight正常取1。
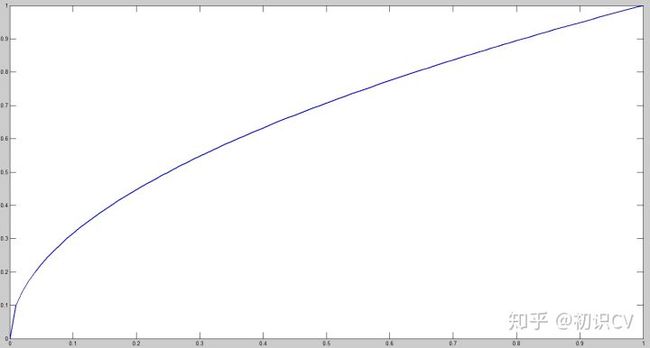
对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点肯定更不能被忍受的。而sum-square error loss中对同样的偏移loss是一样。
为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。这个参考下面的图很容易理解,小box的横轴值较小,发生偏移时,反应到y轴上相比大box要大。(也是个近似逼近方式)
一个网格预测多个box,希望的是每个box predictor专门负责预测某个object。具体做法就是看当前预测的box与ground truth box中哪个IoU大,就负责哪个。这种做法称作box predictor的specialization。
最后整个的损失函数如下所示:

这个损失函数中:
- 只有当某个网格中有object的时候才对classification error进行惩罚。
- 只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个cell的所有box中最大。
其他细节,例如使用激活函数使用leak RELU,模型用ImageNet预训练等等
优点
- 快速,pipline简单.
- 背景误检率低。
- 通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
缺点
- 由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。
- 虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷。
- YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
YOLOv2(YOLO9000)
论文地址:https://arxiv.org/abs/1612.08242
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO9000。
文章提出了一种新的训练方法–联合训练算法,这种算法可以把这两种的数据集混合到一起。使用一种分层的观点对物体进行分类,用巨量的分类数据集数据来扩充检测数据集,从而把两种不同的数据集混合起来。
联合训练算法的基本思路就是:同时在检测数据集和分类数据集上训练物体检测器(Object Detectors ),用检测数据集的数据学习物体的准确位置,用分类数据集的数据来增加分类的类别量、提升健壮性。
YOLO9000就是使用联合训练算法训练出来的,他拥有9000类的分类信息,这些分类信息学习自ImageNet分类数据集,而物体位置检测则学习自COCO检测数据集。
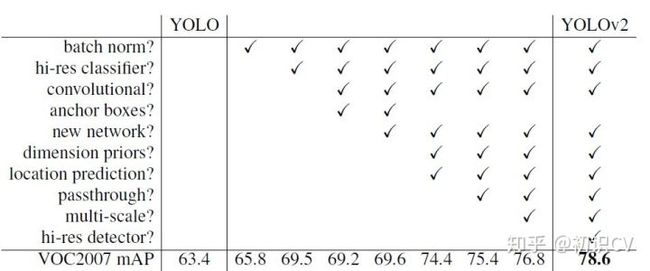
YOLOv2相比YOLOv1的改进策略
改进:
Batch Normalization(批量归一化)mAP提升2.4%。
批归一化有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果(YOLO2不再使用dropout),从而能够获得更好的收敛速度和收敛效果。
通常,一次训练会输入一批样本(batch)进入神经网络。批规一化在神经网络的每一层,在网络(线性变换)输出后和激活函数(非线性变换)之前增加一个批归一化层(BN),BN层进行如下变换:①对该批样本的各特征量(对于中间层来说,就是每一个神经元)分别进行归一化处理,分别使每个特征的数据分布变换为均值0,方差1。从而使得每一批训练样本在每一层都有类似的分布。这一变换不需要引入额外的参数。②对上一步的输出再做一次线性变换,假设上一步的输出为Z,则Z1=γZ + β。这里γ、β是可以训练的参数。增加这一变换是因为上一步骤中强制改变了特征数据的分布,可能影响了原有数据的信息表达能力。增加的线性变换使其有机会恢复其原本的信息。
关于批规一化的更多信息可以参考 Batch Normalization原理与实战。
High resolution classifier(高分辨率图像分类器)mAP提升了3.7%。
图像分类的训练样本很多,而标注了边框的用于训练对象检测的样本相比而言就比较少了,因为标注边框的人工成本比较高。所以对象检测模型通常都先用图像分类样本训练卷积层,提取图像特征。但这引出的另一个问题是,图像分类样本的分辨率不是很高。所以YOLO v1使用ImageNet的图像分类样本采用 224*224 作为输入,来训练CNN卷积层。然后在训练对象检测时,检测用的图像样本采用更高分辨率的 448*448 的图像作为输入。但这样切换对模型性能有一定影响。
所以YOLO2在采用 224*224 图像进行分类模型预训练后,再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。
Convolution with anchor boxes(使用先验框)
召回率大幅提升到88%,同时mAP轻微下降了0.2。
YOLOV1包含有全连接层,从而能直接预测Bounding Boxes的坐标值。 Faster R-CNN的方法只用卷积层与Region Proposal Network来预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。作者发现通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易。
借鉴Faster RCNN的做法,YOLO2也尝试采用先验框(anchor)。在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。
之前YOLO1并没有采用先验框,并且每个grid只预测两个bounding box,整个图像98个。YOLO2如果每个grid采用9个先验框,总共有13*13*9=1521个先验框。所以最终YOLO去掉了全连接层,使用Anchor Boxes来预测 Bounding Boxes。作者去掉了网络中一个Pooling层,这让卷积层的输出能有更高的分辨率。收缩网络让其运行在416*416而不是448*448。
由于图片中的物体都倾向于出现在图片的中心位置,特别是那种比较大的物体,所以有一个单独位于物体中心的位置用于预测这些物体。YOLO的卷积层采用32这个值来下采样图片,所以通过选择416*416用作输入尺寸最终能输出一个13*13的Feature Map。 使用Anchor Box会让精确度稍微下降,但用了它能让YOLO能预测出大于一千个框,同时recall达到88%,mAP达到69.2%。
Dimension clusters(聚类提取先验框的尺度信息)
之前Anchor Box的尺寸是手动选择的,所以尺寸还有优化的余地。 YOLO2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的度。YOLO2的做法是对训练集中标注的边框进行K-mean聚类分析,以寻找尽可能匹配样本的边框尺寸。如果我们用标准的欧式距离的k-means,尺寸大的框比小框产生更多的错误。因为我们的目的是提高IOU分数,这依赖于Box的大小,所以距离度量的使用:
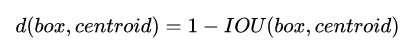
centroid是聚类时被选作中心的边框,box就是其它边框,d就是两者间的“距离”。IOU越大,“距离”越近。YOLO2给出的聚类分析结果如下图所示:
通过分析实验结果(Figure 2),左图:在model复杂性与high recall之间权衡之后,选择聚类分类数K=5。右图:是聚类的中心,大多数是高瘦的Box。Table1是说明用K-means选择Anchor Boxes时,当Cluster IOU选择值为5时,AVG IOU的值是61,这个值要比不用聚类的方法的60.9要高。选择值为9的时候,AVG IOU更有显著提高。总之就是说明用聚类的方法是有效果的。
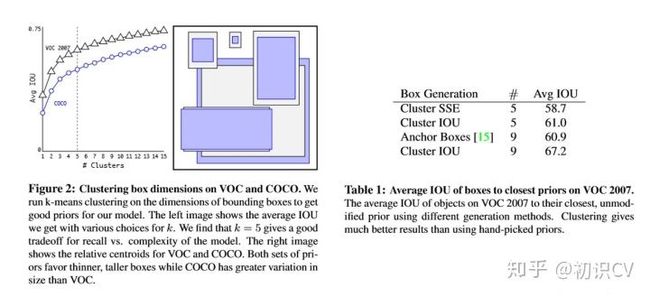
Direct location prediction(约束预测边框的位置)
借鉴于Faster RCNN的先验框方法,在训练的早期阶段,其位置预测容易不稳定。其位置预测公式为:

由于 tx,ty的取值没有任何约束,因此预测边框的中心可能出现在任何位置,训练早期阶段不容易稳定。YOLO调整了预测公式,将预测边框的中心约束在特定gird网格内。

因为使用了限制让数值变得参数化,也让网络更容易学习、更稳定。
Fine-Grained Features(passthrough层检测细粒度特征)
passthrough层检测细粒度特征使mAP提升1。
对象检测面临的一个问题是图像中对象会有大有小,输入图像经过多层网络提取特征,最后输出的特征图中(比如YOLO2中输入416*416经过卷积网络下采样最后输出是13*13),较小的对象可能特征已经不明显甚至被忽略掉了。为了更好的检测出一些比较小的对象,最后输出的特征图需要保留一些更细节的信息。
YOLO2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是26*26*512,将其1拆4,直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。

具体怎样1拆4,下面借用一副图看的很清楚。图中示例的是1个4*4拆成4个2*2。因为深度不变,所以没有画出来。

另外,根据YOLO2的代码,特征图先用1*1卷积从 26*26*512 降维到 26*26*64,再做1拆4并passthrough。下面图6有更详细的网络输入输出结构。
Multi-ScaleTraining(多尺度图像训练)
作者希望YOLO v2能健壮的运行于不同尺寸的图片之上,所以把这一想法用于训练model中。
区别于之前的补全图片的尺寸的方法,YOLO v2每迭代几次都会改变网络参数。每10个Batch,网络会随机地选择一个新的图片尺寸,由于使用了下采样参数是32,所以不同的尺寸大小也选择为32的倍数{320,352…..608},最小320*320,最大608*608,网络会自动改变尺寸,并继续训练的过程。
这一政策让网络在不同的输入尺寸上都能达到一个很好的预测效果,同一网络能在不同分辨率上进行检测。当输入图片尺寸比较小的时候跑的比较快,输入图片尺寸比较大的时候精度高,所以你可以在YOLO v2的速度和精度上进行权衡。
Figure4,Table 3:在voc2007上的速度与精度

hi-res detector(高分辨率图像的对象检测)
图1表格中最后一行有个hi-res detector,使mAP提高了1.8。因为YOLO2调整网络结构后能够支持多种尺寸的输入图像。通常是使用416*416的输入图像,如果用较高分辨率的输入图像,比如544*544,则mAP可以达到78.6,有1.8的提升。
Hierarchical classification(分层分类)
作者提出了一种在分类数据集和检测数据集上联合训练的机制。使用检测数据集的图片去学习检测相关的信息,例如bounding box 坐标预测,是否包含物体以及属于各个物体的概率。使用仅有类别标签的分类数据集图片去扩展可以检测的种类。
作者通过ImageNet训练分类、COCO和VOC数据集来训练检测,这是一个很有价值的思路,可以让我们达到比较优的效果。 通过将两个数据集混合训练,如果遇到来自分类集的图片则只计算分类的Loss,遇到来自检测集的图片则计算完整的Loss。
但是ImageNet对应分类有9000种,而COCO则只提供80种目标检测,作者使用multi-label模型,即假定一张图片可以有多个label,并且不要求label间独立。通过作者Paper里的图来说明,由于ImageNet的类别是从WordNet选取的,作者采用以下策略重建了一个树形结构(称为分层树):
- 遍历Imagenet的label,然后在WordNet中寻找该label到根节点(指向一个物理对象)的路径;
- 如果路径直有一条,那么就将该路径直接加入到分层树结构中;
- 否则,从剩余的路径中选择一条最短路径,加入到分层树。
这个分层树我们称之为 WordTree,作用就在于将两种数据集按照层级进行结合。

分类时的概率计算借用了决策树思想,某个节点的概率值等于该节点到根节点的所有条件概率之积。最终结果是一颗 WordTree (视觉名词组成的层次结构模型)。用WordTree执行分类时,预测每个节点的条件概率。如果想求得特定节点的绝对概率,只需要沿着路径做连续乘积。例如,如果想知道一张图片是不是“Norfolk terrier ”需要计算:

另外,为了验证这种方法作者在WordTree(用1000类别的ImageNet创建)上训练了Darknet-19模型。为了创建WordTree1k,作者天添加了很多中间节点,把标签由1000扩展到1369。训练过程中ground truth标签要顺着向根节点的路径传播。例如,如果一张图片被标记为“Norfolk terrier”,它也被标记为“dog” 和“mammal”等。为了计算条件概率,模型预测了一个包含1369个元素的向量,而且基于所有“同义词集”计算softmax,其中“同义词集”是同一概念的下位词。
softmax操作也同时应该采用分组操作,下图上半部分为ImageNet对应的原生Softmax,下半部分对应基于WordTree的Softmax:

通过上述方案构造WordTree,得到对应9418个分类,通过重采样保证Imagenet和COCO的样本数据比例为4:1。
YOLOv3
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
YOLO v3的模型比之前的模型复杂了不少,可以通过改变模型结构的大小来权衡速度与精度。
速度对比如下:

简而言之,YOLOv3 的先验检测(Prior detection)系统将分类器或定位器重新用于执行检测任务。他们将模型应用于图像的多个位置和尺度。而那些评分较高的区域就可以视为检测结果。此外,相对于其它目标检测方法,我们使用了完全不同的方法。我们将一个单神经网络应用于整张图像,该网络将图像划分为不同的区域,因而预测每一块区域的边界框和概率,这些边界框会通过预测的概率加权。我们的模型相比于基于分类器的系统有一些优势。它在测试时会查看整个图像,所以它的预测利用了图像中的全局信息。与需要数千张单一目标图像的 R-CNN 不同,它通过单一网络评估进行预测。这令 YOLOv3 非常快,一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍。
改进之处
- 多尺度预测 (引入FPN)。
- 更好的基础分类网络(darknet-53, 类似于ResNet引入残差结构)。
- 分类器不在使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
- Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。
- Softmax可被独立的多个logistic分类器替代,且准确率不会下降。
分类损失采用binary cross-entropy loss。
多尺度预测
每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3个尺度.
- 尺度1: 在基础网络之后添加一些卷积层再输出box信息.
- 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.
- 尺度3: 与尺度2类似,使用了32x32大小的特征图.
参见网络结构定义文件yolov3.cfg
基础网络 Darknet-53

darknet-53
仿ResNet, 与ResNet-101或ResNet-152准确率接近,但速度更快.对比如下:

主干架构的性能对比
检测结构如下:

YOLOv3在[email protected]及小目标APs上具有不错的结果,但随着IOU的增大,性能下降,说明YOLOv3不能很好地与ground truth切合.
边框预测

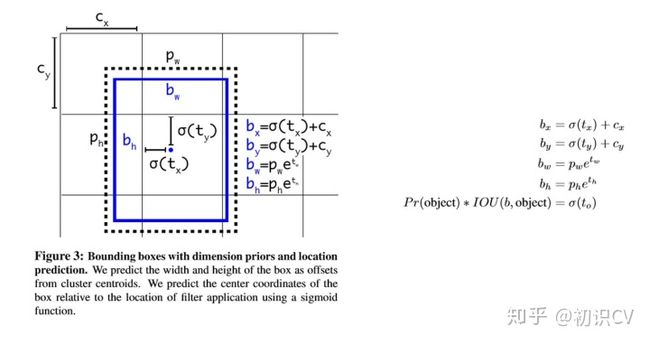
图 2:带有维度先验和定位预测的边界框。我们边界框的宽和高以作为离聚类中心的位移,并使用 Sigmoid 函数预测边界框相对于滤波器应用位置的中心坐标。
仍采用之前的loss,其中cx,cy是网格的坐标偏移量,pw,ph是预设的anchor box的边长.最终得到的边框坐标值是b*,而网络学习目标是t*,用sigmod函数、指数转换。
多尺度预测:更好地对应不同大小的目标物体
每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3个尺度.
- 尺度1: 在基础网络之后添加一些卷积层再输出box信息.
- 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.
- 尺度3: 与尺度2类似,使用了32x32大小的特征图.
参见网络结构定义文件yolov3.cfg
通常一幅图像包含各种不同的物体,并且有大有小。比较理想的是一次就可以将所有大小的物体同时检测出来。因此,网络必须具备能够“看到”不同大小的物体的能力。并且网络越深,特征图就会越小,所以越往后小的物体也就越难检测出来。SSD中的做法是,在不同深度的feature map获得后,直接进行目标检测,这样小的物体会在相对较大的feature map中被检测出来,而大的物体会在相对较小的feature map被检测出来,从而达到对应不同scale的物体的目的。
然而在实际的feature map中,深度不同所对应的feature map包含的信息就不是绝对相同的。举例说明,随着网络深度的加深,浅层的feature map中主要包含低级的信息(物体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信息:狗,猫,汽车等等)。因此在不同级别的feature map中进行检测,听起来好像可以对应不同的scale,但是实际上精度并没有期待的那么高。
在YOLOv3中,这一点是通过采用FPN结构来提高对应多重scale的精度的。
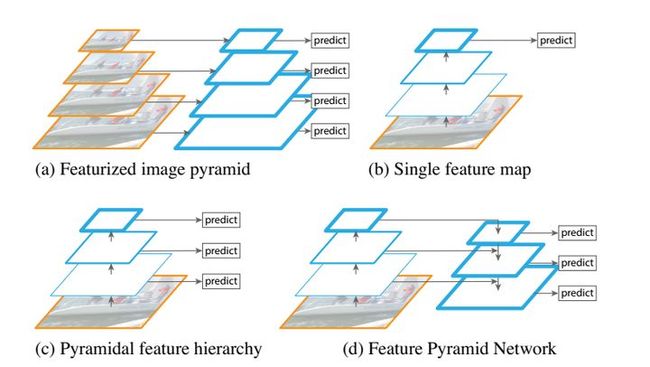
如上图所示,对于多重scale,目前主要有以下几种主流方法。
(a) Featurized image pyramid: 这种方法最直观。首先对于一幅图像建立图像金字塔,不同级别的金字塔图像被输入到对应的网络当中,用于不同scale物体的检测。但这样做的结果就是每个级别的金字塔都需要进行一次处理,速度很慢。
(b) Single feature map: 检测只在最后一个feature map阶段进行,这个结构无法检测不同大小的物体。
(c) Pyramidal feature hierarchy: 对不同深度的feature map分别进行目标检测。SSD中采用的便是这样的结构。每一个feature map获得的信息仅来源于之前的层,之后的层的特征信息无法获取并加以利用。
(d) Feature Pyramid Network 与(c)很接近,但有一点不同的是,当前层的feature map会对未来层的feature map进行上采样,并加以利用。这是一个有跨越性的设计。因为有了这样一个结构,当前的feature map就可以获得“未来”层的信息,这样的话低阶特征与高阶特征就有机融合起来了,提升检测精度。
ResNet残差结构:更好地获取物体特征
YOLOv3中使用了ResNet结构(对应着在上面的YOLOv3结构图中的Residual Block)。Residual Block是有一系列卷基层和一条shortcut path组成。shortcut如下图所示。

图中曲线箭头代表的便是shortcut path。除此之外,此结构与普通的CNN结构并无区别。随着网络越来越深,学习特征的难度也就越来越大。但是如果我们加一条shortcut path的话,学习过程就从直接学习特征,变成在之前学习的特征的基础上添加某些特征,来获得更好的特征。这样一来,一个复杂的特征H(x),之前是独立一层一层学习的,现在就变成了这样一个模型。H(x)=F(x)+x,其中x是shortcut开始时的特征,而F(x)就是对x进行的填补与增加,成为残差。因此学习的目标就从学习完整的信息,变成学习残差了。这样以来学习优质特征的难度就大大减小了。
替换softmax层:对应多重label分类
Softmax层被替换为一个1x1的卷积层+logistic激活函数的结构。使用softmax层的时候其实已经假设每个输出仅对应某一个单个的class,但是在某些class存在重叠情况(例如woman和person)的数据集中,使用softmax就不能使网络对数据进行很好的拟合。
改进之处
- 多尺度预测 (引入FPN)。
- 更好的基础分类网络(darknet-53, 类似于ResNet引入残差结构)。
- 分类器不在使用Softmax,分类损失采用binary cross-entropy loss(二分类交叉损失熵)
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
- Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。
- Softmax可被独立的多个logistic分类器替代,且准确率不会下降。
分类损失采用binary cross-entropy loss。YOLOv3相比之前的版本确实精度提高了不少,但是相应的变慢了一些。不过还好作者发布了一个轻量级的TinyYOLOv3,网络结构如下:

YOLOv4
YOLOv4: Optimal Speed and Accuracy of Object Detection
论文:https://arxiv.org/abs/2004.10934
代码:https://github.com/AlexeyAB/darknet
YOLOv4!
YOLOv4 在COCO上,可达43.5% AP,速度高达 65 FPS!
YOLOv4的特点是集大成者,俗称堆料。但最终达到这么高的性能,一定是不断尝试、不断堆料、不断调参的结果,给作者点赞。下面看看堆了哪些料:
- Weighted-Residual-Connections (WRC)
- Cross-Stage-Partial-connections (CSP)
- Cross mini-Batch Normalization (CmBN)
- Self-adversarial-training (SAT)
- Mish-activation
- Mosaic data augmentation
- CmBN
- DropBlock regularization
- CIoU loss
本文的主要贡献如下:
1. 提出了一种高效而强大的目标检测模型。它使每个人都可以使用1080 Ti或2080 Ti GPU 训练超快速和准确的目标检测器(牛逼!)。
2. 在检测器训练期间,验证了SOTA的Bag-of Freebies 和Bag-of-Specials方法的影响。
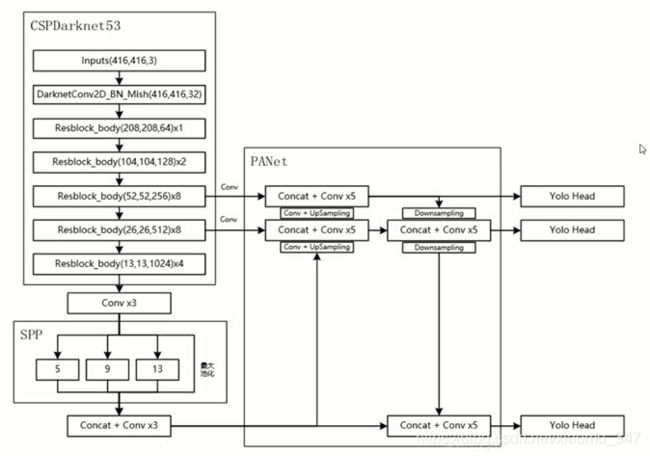
3. 改进了SOTA的方法,使它们更有效,更适合单GPU训练,包括CBN [89],PAN [49],SAM [85]等。文章将目前主流的目标检测器框架进行拆分:input、backbone、neck 和 head.
具体如下图所示:
- 对于GPU,作者在卷积层中使用:CSPResNeXt50 / CSPDarknet53
- 对于VPU,作者使用分组卷积,但避免使用(SE)块-具体来说,它包括以下模型:EfficientNet-lite / MixNet / GhostNet / MobileNetV3
作者的目标是在输入网络分辨率,卷积层数,参数数量和层输出(filters)的数量之间找到最佳平衡。
总结一下YOLOv4框架:
- Backbone:CSPDarknet53
- Neck:SPP,PAN
- Head:YOLOv3
- 其他:数据BOF,损失函数CIOU,激活函数mish,SOFT-NMS/DIOU-NMS,cbam attention






YOLOv4 = CSPDarknet53+SPP+PAN+YOLOv3
其中YOLOv4用到相当多的技巧:
- 用于backbone的BoF:CutMix和Mosaic数据增强,DropBlock正则化,Class label smoothing
- 用于backbone的BoS:Mish激活函数,CSP,MiWRC
- 用于检测器的BoF:CIoU-loss,CmBN,DropBlock正则化,Mosaic数据增强,Self-Adversarial 训练,消除网格敏感性,对单个ground-truth使用多个anchor,Cosine annealing scheduler,最佳超参数,Random training shapes
- 用于检测器的Bos:Mish激活函数,SPP,SAM,PAN,DIoU-NMS
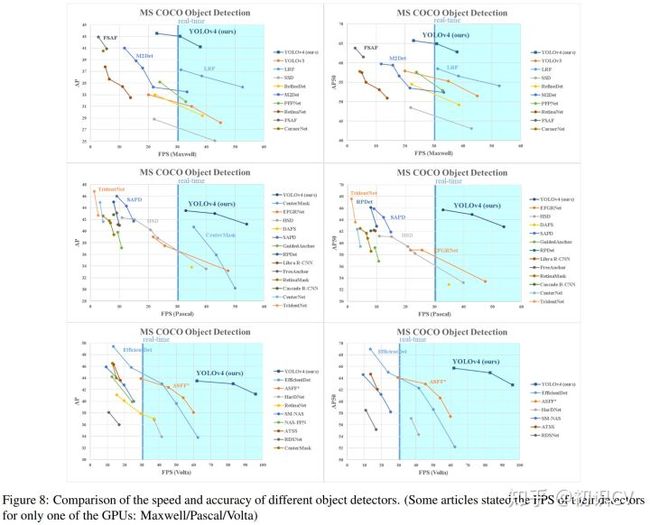
看看YOLOv4部分组件,感受一下YOLOv4实验的充分性(调参的艺术):
YOLOv5:
2020年2月YOLO之父Joseph Redmon宣布退出计算机视觉研究领域,2020 年 4 月 23 日YOLOv4 发布,2020 年 6 月 10 日YOLOv5发布。

YOLOv5源代码:
https://github.com/ultralytics/yolov5github.com
他们公布的结果表明,YOLOv5 的表现要优于谷歌开源的目标检测框架 EfficientDet,尽管 YOLOv5 的开发者没有明确地将其与 YOLOv4 进行比较,但他们却声称 YOLOv5 能在 Tesla P100 上实现 140 FPS 的快速检测;相较而言,YOLOv4 的基准结果是在 50 FPS 速度下得到的,参阅:https://blog.roboflow.ai/yolov5-is-hereState-of-the-Art

不仅如此,他们还提到「YOLOv5 的大小仅有 27 MB。」对比一下:使用 darknet 架构的 YOLOv4 有 244 MB。这说明 YOLOv5 实在特别小,比 YOLOv4 小近 90%。这也太疯狂了!而在准确度指标上,「YOLOv5 与 YOLOv4 相当」。
因此总结起来,YOLOv5 宣称自己速度非常快,有非常轻量级的模型大小,同时在准确度方面又与 YOLOv4 基准相当。
大家对YOLOV5命名是争议很大,因为YOLOV5相对于YOLOV4来说创新性的地方很少。不过它的性能应该还是有的,现在kaggle上active检测的比赛小麦检测前面的选手大部分用的都是YOLOV5的框架。总的来说,YOLO V4 在性能上优于YOLO V5,但是在灵活性与速度上弱于YOLO V5。由于YOLO V5仍然在快速更新,因此YOLO V5的最终研究成果如何,还有待分析。个人觉得对于这些对象检测框架,特征融合层的性能非常重要,目前两者都是使用PANET,但是根据谷歌大脑的研究,BiFPN才是特征融合层的最佳选择。谁能整合这项技术,很有可能取得性能大幅超越。

尽管YOLO V5目前仍然计逊一筹,但是YOLO V5仍然具有以下显著的优点:
-
使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLO V4采用的Darknet框架,Pytorch框架更容易投入生产
-
代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴
-
不仅易于配置环境,模型训练也非常快速,并且批处理推理产生实时结果
-
能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输入进行有效推理
-
能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端
-
最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒
YOLO-LITE
YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers
作者:Jonathan Pedoeem, Rachel Huang
单位:佐治亚理工学院等
论文:https://arxiv.org/abs/1811.05588
引用 | 73
代码:https://reu2018dl.github.io/
Star | 336
时间:2018年11月14日
YOLO-LITE 是 YOLOv2-tiny 的Web实现,在 MS COCO 2014 和 PASCAL VOC 2007 + 2012 数据集上训练。在 Dell XPS 13 机器上可达到 21 FPS ,VOC 数据集上达到33.57 mAP。

Spiking-YOLO
Spiking-YOLO: Spiking Neural Network for Energy-Efficient Object Detection
作者:Seijoon Kim, Seongsik Park, Byunggook Na, Sungroh Yoon
单位:首尔大学
论文:https://arxiv.org/abs/1903.06530
引用 | 3
备注:AAAI 2020
解读:Spiking-YOLO : 前沿!脉冲神经网络在目标检测的首次尝试
时间:2019年3月12日
该文第一次将脉冲神经网络用于目标检测,虽然精度不高,但相比Tiny_YOLO 耗能更少。(研究意义大于实际应用意义)
DC-SPP-YOLO
DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection
作者:Zhanchao Huang, Jianlin Wang
单位:北京化工大学
论文:https://arxiv.org/abs/1903.08589
引用 | 8
时间:2019年3月20日
该作提出一种DC-SPP-YOLO(基于YOLO的密集连接和空间金字塔池化技术)的方法来改善YOLOv2的目标检测精度。

SpeechYOLO
SpeechYOLO: Detection and Localization of Speech Objects
作者:Yael Segal, Tzeviya Sylvia Fuchs, Joseph Keshet
单位:巴伊兰大学
论文:https://arxiv.org/abs/1904.07704
引用 | 2
时间:2019年4月14日
YOLO算法启发的语音处理识别算法。
SpeechYOLO的目标是在输入信号中定位语句的边界,并对其进行正确分类。受YOLO算法在图像中进行目标检测的启发所提出的方法。
Complexer-YOLO
Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds
作者:Martin Simon, Karl Amende, Andrea Kraus, Jens Honer, Timo Sämann, Hauke Kaulbersch, Stefan Milz, Horst Michael Gross
单位:伊尔梅瑙工业大学等
论文:https://arxiv.org/abs/1904.07537
引用 | 24
时间:2019年4月16日
Complex-YOLO的改进版,用于实时点云3D目标检测与跟踪,推断速度加速20%,训练时间减少50%。

SlimYOLOv3
SlimYOLOv3: Narrower, Faster and Better for UAV Real-Time Applications
作者:Pengyi Zhang, Yunxin Zhong, Xiaoqiong Li
单位:北理工
论文:https://arxiv.org/abs/1907.11093
引用 | 18
解读:SlimYOLOv3:更窄、更快、更好的无人机目标检测算法
代码:https://github.com/PengyiZhang/SlimYOLOv3
Star | 953
时间:2019年7月15日
该文对YOLOv3的卷积层通道剪枝,大幅削减了模型的计算量(~90.8% decrease of FLOPs)和参数量( ~92.0% decline of parameter size),剪枝后的模型在基本保持原模型的检测精度同时,运行速度约为原来的两倍。

REQ-YOLO
REQ-YOLO: A Resource-Aware, Efficient Quantization Framework for Object Detection on FPGAs
作者:Caiwen Ding, Shuo Wang, Ning Liu, Kaidi Xu, Yanzhi Wang, Yun Liang
单位:北大;东北大学;鹏城实验室
论文:https://arxiv.org/abs/1909.13396
引用 | 14
时间:2019年9月29日
Tiny-YOLO的 FPGA 实现,REQ-YOLO速度可高达200~300 FPS!

YOLO Nano
YOLO Nano: a Highly Compact You Only Look Once Convolutional Neural Network for Object Detection
作者:Alexander Wong, Mahmoud Famuori, Mohammad Javad Shafiee, Francis Li, Brendan Chwyl, Jonathan Chung
单位:滑铁卢大学;DarwinAI Corp
论文:https://arxiv.org/abs/1910.01271
引用 | 6
时间:2019年10月3日
YOLO Nano 比 Tiny YOLOv2 和 Tiny YOLOv3更小,更快,mAP更高!模型仅4.0MB。在 NVIDIA Jetson Xavier上速度竟高达26.9~48.2 FPS!

xYOLO
xYOLO: A Model For Real-Time Object Detection In Humanoid Soccer On Low-End Hardware
作者:Daniel Barry, Munir Shah, Merel Keijsers, Humayun Khan, Banon Hopman
单位:坎特伯雷大学
论文:https://arxiv.org/abs/1910.03159
引用 | 3
时间:2019年10月7日
该工作所提出的 xYOLO 是从 YOLO v3 tiny 变化而来,xYOLO比Tiny-YOLO快了70倍!在树莓派3B上速度9.66 FPS!模型仅0.82 MB大小,这可能是速度最快模型最小的YOLO变种。

IFQ-Tinier-YOLO
IFQ-Net: Integrated Fixed-point Quantization Networks for Embedded Vision
作者:Hongxing Gao, Wei Tao, Dongchao Wen, Tse-Wei Chen, Kinya Osa, Masami Kato
单位:Canon Information Technology (Beijing) Co., LTD;Device Technology Development Headquarters, Canon Inc.
论文:https://arxiv.org/abs/1911.08076
引用 | 4
时间:2019年11月19日
该工作一部分基于YOLOv2,设计了IFQ-Tinier-YOLO人脸检测器,它是一个定点网络,比Tiny-YOLO减少了256倍的模型大小(246k Bytes)。

DG-YOLO
WQT and DG-YOLO: towards domain generalization in underwater object detection
作者:Hong Liu, Pinhao Song, Runwei Ding
单位:北大;鹏城实验室
论文:https://arxiv.org/abs/2004.06333
时间:2020年4月14日
该工作旨在研究水下目标检测数据,因为水下目标的数据比较少,提出了新的水质迁移的数据增广方法和YOLO新变种:DG-YOLO ,该算法由 YOLOv3, DIM 和 IRM penalty 组成。

Poly-YOLO
Poly-YOLO: higher speed, more precise detection and instance segmentation for YOLOv3
作者:Petr Hurtik, Vojtech Molek, Jan Hula, Marek Vajgl, Pavel Vlasanek, Tomas Nejezchleba
单位:奥斯特拉发大学;Varroc Lighting Systems
论文:https://arxiv.org/abs/2005.13243
解读:mAP提升40%!YOLO3改进版—— Poly-YOLO:更快,更精确的检测和实例分割
代码:https://gitlab.com/irafm-ai/poly-yolo
时间:2020年5月27日
基于YOLOv3,支持实例分割,检测mAP提升40%!

E-YOLO
Expandable YOLO: 3D Object Detection from RGB-D Images
作者:Masahiro Takahashi, Alessandro Moro, Yonghoon Ji, Kazunori Umeda
单位:(日本)中央大学;RITECS Inc
论文:https://arxiv.org/abs/2006.14837
时间:2020年6月26日
YOLOv3的变种,构建了一个轻量级的目标检测器,从RGBD-D立体摄像机输入深度和彩色图像。该模型的处理速度为44.35fps(GPU: NVIDIA RTX 2080 and CPU: Intel Core i7 8700K)。

PP-YOLO
PP-YOLO: An Effective and Efficient Implementation of Object Detector
作者:Xiang Long, Kaipeng Deng, Guanzhong Wang, Yang Zhang, Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, Shumin Han, Errui Ding, Shilei Wen
单位:百度
论文:https://arxiv.org/abs/2007.12099
解读:https://zhuanlan.zhihu.com/p/163565906
代码:https://github.com/PaddlePaddle/PaddleDetection
时间:2020年7月23日
PP-YOLO由在YOLOv3上添加众多tricks“组合式创新”得来,从下图前两列中可看到其使用的技术:
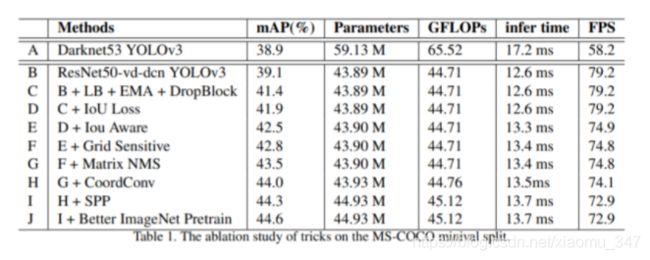
PP-YOLO在精度和效率之间取得更好的平衡,在COCO数据集上达到45.2% mAP,并且速度72.9 FPS!,超越YOLOv4和谷歌EfficientDet,是更加实用的目标检测算法。

参考链接:
1、目标检测之YOLO算法:YOLOv1,YOLOv2,YOLOv3,TinyYOLO,YOLOv4,YOLOv5,YOLObile,YOLOF,YOLOX详解 - 知乎
2、深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎
3、YOLO 系目标检测算法家族全景图!