bert textcnn用于文本分类
bert
1. load bert 方式
tf bert源代码
tf keras_bert
tf tensorflow_hub
tf bert-as-service
torch tf-->torch(用transformers库把tf-bert模型转成torch) pytorch_pretrained_bertinput_ids
input_mask
segment_ids2.preprocess our data
1. lowercase our text (for:EN)
2. Tokenize it(i.e. "sally says hi" -> ["sally", "says", "hi"])
3. break words into wordpieces
4. map our words to indexes using a vocab file that bert provides
5. add special 'CLS' and 'SEP' token
6. append 'index' and 'segment' tokens to each input (see the [BERT paper](https://arxiv.org/pdf/1810.04805.pdf))
bert fine-tune
bert 得到特征进行下游任务
一、当作文本特征提取的工具,类似Word2vec模型一样
二、作为一个可训练的层,后面可接入客制化的网络,做迁移学习
使用keras_bert来加载构建bert模型
import codecs
import pandas as pd
import numpy as np
from keras.utils import to_categorical, multi_gpu_model
from keras.preprocessing.text import Tokenizer
from keras.models import Model
from keras.layers import Layer, Input, Dense, Conv1D, GlobalMaxPooling1D, Concatenate,Dropout
from keras.optimizers import Adam
import keras_bert
from keras_bert import Tokenizer
from sklearn import metrics
import os
os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID'
os.environ['CUDA_VISIBLE_DEVICE'] = '0,1,2'
#bert后面接textcnn需要NonMasking
class NonMasking(Layer):
def __init__(self, **kwargs):
self.supports_masking = True
super(NonMasking, self).__init__(**kwargs)
def build(self, input_shape):
input_shape = input_shape
def compute_mask(self, input, input_mask=None):
# do not pass the mask to the next layers
return None
def call(self, x, mask=None):
return x
def get_output_shape_for(self, input_shape):
return input_shape
def get_model(config_path, checkpoint_path):
bert_model = keras_bert.load_trained_model_from_checkpoint(
config_path, checkpoint_path)
for l in bert_model.layers:
l.trainable = False
T1 = Input(shape=(512,))
T2 = Input(shape=(512,))
T = bert_model([T1, T2])
T = NonMasking()(T)
convs = []
for kernel_size in [3, 4, 5]:
c = Conv1D(128, kernel_size, activation='relu',padding='same')(T)
c = GlobalMaxPooling1D()(c)
convs.append(c)
x = Concatenate()(convs)
x = Dropout(0.2)(x)
output = Dense(37, activation='softmax')(x)
model = Model([T1, T2], output)
model.summary()
#用2个gpu
model = multi_gpu_model(model, gpus=2)
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(1e-5),
metrics=['accuracy']
)
model.summary()
return model
# BERT_PATH = r'./chinese_L-12_H-768_A-12'
# config_path = os.path.join(BERT_PATH, 'bert_config.json')
# checkpoint_path = os.path.join(BERT_PATH, 'bert_model.ckpt')
BERT_PATH = r'./chinese_wwm_ext_L-12_H-768_A-12'
config_path = os.path.join(BERT_PATH, 'bert_config.json')
checkpoint_path = os.path.join(BERT_PATH, 'bert_model.ckpt')
#seq_len=200,output_layer_num=4,training=False,trainable=False
model_clf = get_model(config_path, checkpoint_path)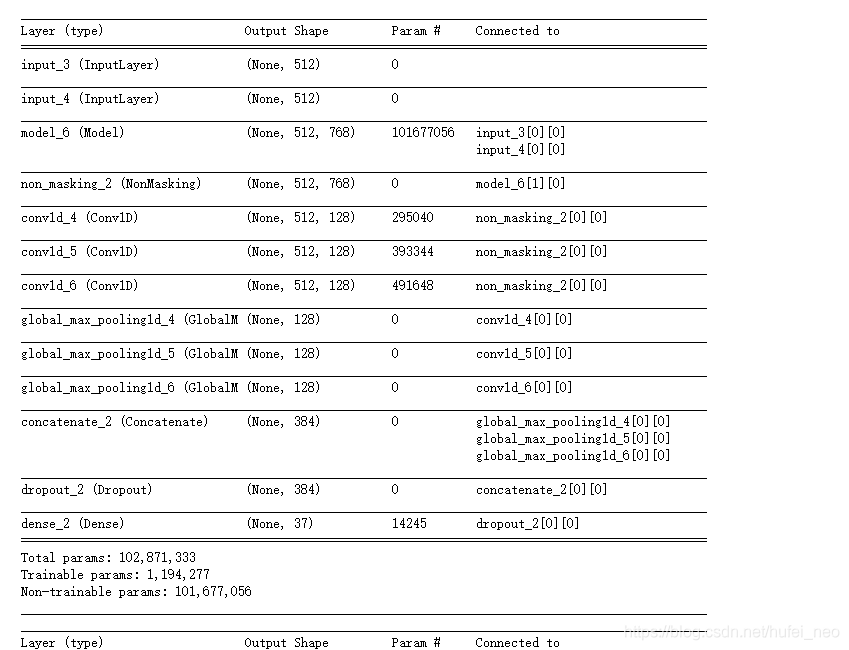
#样本处理
df =pd.read_excel(r'./data/train.xlsx')
import codecs
vocab_path = os.path.join(BERT_PATH, 'vocab.txt')
token_dict = {}
with codecs.open(vocab_path, 'r', 'utf8') as reader:
for line in reader:
token = line.strip()
token_dict[token] = len(token_dict)
from keras_bert import Tokenizer
def token_inde(text):
tokenizer = Tokenizer(token_dict)
indices, segments = tokenizer.encode(text, max_len=512)
return indices
def token_segm(text):
tokenizer = Tokenizer(token_dict)
indices, segments = tokenizer.encode(text, max_len=512)
return segments
# tokenizer = Tokenizer(token_dict)
# 进行bert token处理
# df['cutted'] = df['text'].apply(lambda x: tokenizer.tokenize(x))
df['indices']=df['text'].apply(token_inde)
df['segments']=df['text'].apply(token_segm)
# label类别处理(y值即label的映射,label的数量) eg:'体育':1 1:'新闻'
label = list(set(df['label'].tolist()))
dig_lables = dict(enumerate(label))
lable_dig = dict((lable, dig) for dig, lable in dig_lables.items())
print('y值处理成功类别共计***', len(lable_dig))
df['label_new'] = df['label'].apply(lambda lable: lable_dig[lable])
# 类别保存到本地
import json
item = json.dumps(dig_lables, ensure_ascii=False, indent=4)
with open('label.json','w',encoding='utf-8') as f:
f.write(item)
# 分割训练集和测试集
from sklearn.model_selection import train_test_split
train, test= train_test_split(df_pass,test_size=0.1, shuffle=True)
print('训练集数据量: ',len(train),'测试集数据量: ',len(test))
# 训练集x和y
train_data = [np.array(train['indices'].tolist()),np.array(train['segments'].tolist())]
train_lables = to_categorical(train['label'],num_classes=len(label))
# 测试集
test_data= [np.array(test['indices'].tolist()),np.array(test['segments'].tolist())]
model_clf.summary()
model_clf.fit(train_data,train_lables,epochs=7, batch_size=512)
# 测试集
from sklearn import metrics
test_predict=model_clf.predict(test_data)
test['bert_textcnn预测']=[dig_lables[test_predict[i].argmax()] for i in range(len(test_predict))]
print('result:',metrics.accuracy_score(test['text'],test['bert_textcnn预测']))