Promethus(普罗米修斯)安装与配置
1. 普罗米修斯概述
-
Prometheus(是由go语言(golang)开发)是一套开源的监控&报警&时间序列数 据库的组合。适合监控docker容器。
-
Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包 。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区。现在,它是一个独立的开源项目,并且独立于任何公司进行维护。为了强调这一点并阐明项目的治理结构,Prometheus 于2016年加入了 Cloud Native Computing Foundation,这是继Kubernetes之后的第二个托管项目。
-
Prometheus是一个时间序列数据库。但是,它不仅仅是一个时间序列数据库。
-
它涵盖了可以绑定的整个生态系统工具集及其功能。
-
Prometheus主要用于对基础设施的监控。包括服务器,数据库,VPS,几乎所有东西都可以通过Prometheus进行监控。Prometheus希望通过对Prometheus配置中定义的某些端点执行的HTTP调用来检索度量标准。
Prometheus 的优点
- 非常少的外部依赖,安装使用超简单
- 已经有非常多的系统集成 例如:docker HAProxy Nginx JMX等等
- 服务自动化发现
- 直接集成到代码
- 设计思想是按照分布式、微服务架构来实现的
- 可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端
- 可以通过服务发现或者静态配置去获取监控的 targets。
- 有多种可视化图形界面。
- 易于伸缩。
Prometheus 的特性
- 一个多维数据模型,其中包含通过度量标准名称和键/值对标识的时间序列数据
- PromQL,一种灵活的查询语言 ,可利用此维度
- 不依赖分布式存储;单服务器节点是自治的
- 时间序列收集通过HTTP上的拉模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持模式
2. 时间序列数据
1、什么是序列数据
时间序列数据(TimeSeries Data) : 按照时间顺序记录系统、设备状态变化 的数据被称为时序数据。
应用的场景很多, 如:
无人驾驶车辆运行中要记录的经度,纬度,速度,方向,旁边物体的距 离等等。每时每刻都要将数据记录下来做分析。
某一个地区的各车辆的行驶轨迹数据
传统证券行业实时交易数据
实时运维监控数据等
2.1 时间序列数据特点
性能好
关系型数据库对于大规模数据的处理性能糟糕。NOSQL可以比较好的处理 大规模数据,让依然比不上时间序列数据库。
存储成本低
高效的压缩算法,节省存储空间,有效降低IO
Prometheus有着非常高效的时间序列数据存储方法,每个采样数据仅仅占 用3.5byte左右空间,上百万条时间序列,30秒间隔,保留60天,大概花了 200多G(来自官方数据)
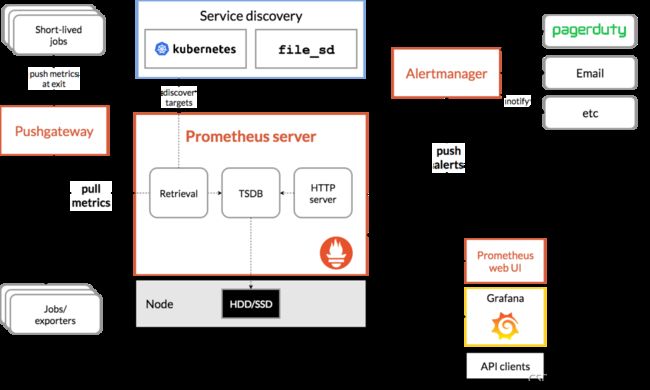
3. Prometheus原理架构图
下图说明了Prometheus的体系结构及其某些生态系统组件:
-
prometheus直接或通过中介推送网关从已检测作业中删除指标,以处理短暂的作业。它在本地存储所有报废的样本,并对这些数据运行规则,以汇总和记录现有数据中的新时间序列,或生成警报。Grafana或其他API使用者可以用来可视化收集的数据。
-
Prometheus可以很好地记录任何纯数字时间序列。它既适用于以机器为中心的监视,也适用于高度动态的面向服务的体系结构的监视。在微服务世界中,它对多维数据收集和查询的支持是一种特别的优势。
-
Prometheus的设计旨在提高可靠性,使其成为中断期间要使用的系统,以使您能够快速诊断问题。每个Prometheus服务器都是独立的,而不依赖于网络存储或其他远程服务。当基础结构的其他部分损坏时,您可以依靠它,并且无需设置广泛的基础结构即可使用它。
-
普罗米修斯重视可靠性。即使在故障情况下,您始终可以查看有关系统的可用统计信息。如果您需要100%的准确性(例如按请求计费),则Prometheus并不是一个好的选择,因为所收集的数据可能不够详细和完整。在这种情况下,最好使用其他系统来收集和分析数据以进行计费,并使用Prometheus进行其余的监视。
4. 部署Prometheus
实验环境:
| 主机名 | IP | 服务 |
|---|---|---|
| node2 | 192.168.200.154 | prometheus |
| node1 | 192.168.200.144 | node_exporter |
4.1准备工作
下载最新版的服务端prometheus和客户端node_exporter
- 服务端:https://prometheus.io/download/#prometheus
- 客户端:https://prometheus.io/download/#node_exporter
4.2下载软件包
[root@node2 ~]# wget https://github.com/prometheus/prometheus/releases/download/v2.31.1/prometheus-2.31.1.linux-amd64.tar.gz
4.3解压缩包
[root@node2 ~]# tar xf prometheus-2.31.1.linux-amd64.tar.gz -C /usr/local/
[root@node2 src]# cd /usr/local/
[root@node2 local]# ls
bin games lib libexec redis share
etc include lib64 prometheus-2.31.1.linux-amd64 sbin src
[root@node2 local]# mv prometheus-2.31.1.linux-amd64/ prometheus
4.4运行Prometheus server
[root@node2 local]# cd prometheus/
[root@node2 prometheus]# ./prometheus --config.file=prometheus.yml
4.5 配置Prometheus
在Prometheus.yml中有配置文件,我们可以对其进行配置,当然第一次安装也可以不用配置;
root@node2 prometheus]# vim /usr/local/prometheus/prometheus.yml
#全局配置
global:
scrape_interval: 15s #每隔15秒向目标抓取一次数,默认为一分钟
evaluation_interval: 15s #每隔15秒执行一次告警规则,默认为一分钟
# scrape_timeout: 600s #抓取数据的超时时间,默认为10s
#告警配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 #alertmanager所部署机器的ip和端口
#定义告警规则和阈值的yml文件
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
#收集数据配置
#以下是Prometheus自身的一个配置.
scrape_configs:
#这个配置是表示在这个配置内的时间序例,每一条都会自动添加上这个{job_name:"prometheus"}的标签.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs: #静态配置
- targets: ["localhost:9090"]
其配置大致可分为四部分:
-
global:全局配置,其中scrape_interval表示抓取一次数据的间隔时间,evaluation_interval表示进行告警规则检测的间隔时间;
-
alerting:告警管理器(Alertmanager)的配置,目前还没有安装Alertmanager;
-
rule_files:告警规则有哪些;
-
scrape_configs:抓取监控信息的目标。一个job_name就是一个目标,其targets就是采集信息的IP和端口。这里默认监控了Prometheus自己,可以通过修改这里来修改Prometheus的监控端口。Prometheus的每个exporter都会是一个目标,它们可以上报不同的监控信息,比如机器状态,或者mysql性能等等,不同语言sdk也会是一个目标,它们会上报你自定义的业务监控信息。
4.6 校验配置文件
[root@node2 prometheus]# ./promtool check config ./prometheus.yml
Checking ./prometheus.yml
SUCCESS: 0 rule files found
4.7配置service启动文件
[root@node2 prometheus]# cat > /usr/lib/systemd/system/prometheus.service <4.8启动参数介绍
##启动
/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml &
##启动参数介绍
--config.file #加载prometheus的配置文件
--web.listen-address #监听prometheus的web地址和端口
--web.enable-lifecycle #热启动参数,可以在不中断服务的情况下重启加载配置文件
--storage.tsdb.retention #数据持久化的时间
--storage.tsdb.path #数据持久化的保存路径
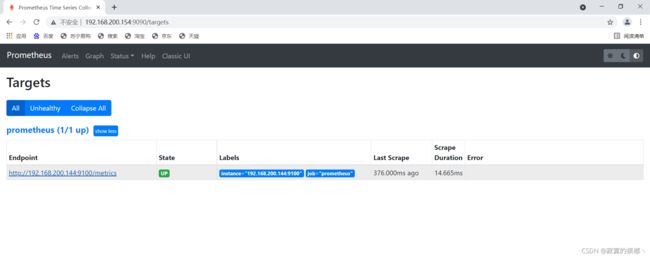
4.9访问测试
输入: “ip地址”+":9090" 在浏览器中进行访问,如果出现可视化界面说明成功;

6. node_exporter部署
6.1 下载软件包
wget https://github.com/prometheus/node_exporter/releases/download/v1.3.0/node_exporter-1.3.0.linux-amd64.tar.gz
6.2 解压软件包
[root@node1 ~]# ls
anaconda-ks.cfg node_exporter-1.3.0.linux-amd64.tar.gz
[root@node1 ~]# tar xf node_exporter-1.3.0.linux-amd64.tar.gz -C /usr/local/
[root@node1 ~]#
[root@node1 ~]# cd /usr/local/
[root@node1 local]# ls
bin games lib libexec sbin src
etc include lib64 node_exporter-1.3.0.linux-amd64 share
[root@node1 local]# mv node_exporter-1.3.0.linux-amd64/ node_exporter
[root@node1 local]#
6.4 启动参数介绍
注意:相关启动的参数
--web.listen-address #node_expoetrt暴露的端口
--collector.systemd #从systemd中收集
--collector.systemd.unit-whitelist ##白名单,收集目标
".+" #从systemd中循环正则匹配单元
"(docker|sshd|nginx).service" #白名单,收集目标,收集参数node_systemd_unit_state
6.5 配置service文件
[root@node1 local]# vi /usr/lib/systemd/system/node_exporter.service
[unit]
Description=The node_exporter Server
After=network.target
[Service]
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
RestartSec=15s
SyslogIdentifier=node_exporter
[Install]
WantedBy=multi-user.target
[root@node1 local]# systemctl daemon-reload
[root@node1 local]# systemctl enable node_exporter
[root@node1 local]# systemctl restart node_exporter
Created symlink /etc/systemd/system/multi-user.target.wants/node_exporter.service → /usr/lib/systemd/system/node_exporter.service.
[root@node1 local]# ss -antl
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 128 *:9100 *:*
[root@node1 local]#
6.6 在Prometheus主机上修改prometheus.yml配置文件
[root@node2 prometheus]# vim /usr/local/prometheus/prometheus.yml
......
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["192.168.200.144:9100"] //此处指定客户端ip和端口
6.7访问测试是否连接成功
使用Prometheus主机IP地址和端口号 http://192.168.200.154:9100/targets访问