蓝色车牌识别OpenCV-Python
车牌识别
- 前言
- 一、程序体会
- 二、使用步骤
-
- 1.系统分析
- 2.事前定义函数
- 3.车牌定位
- 4.字符提取
- 5.程序运行界面截图
前言
定位车牌位置有很多方法可以成功的定位,而每种方法都有各自的优缺点。
提示:以下是本篇文章正文内容,下面案例可供参考
一、程序体会

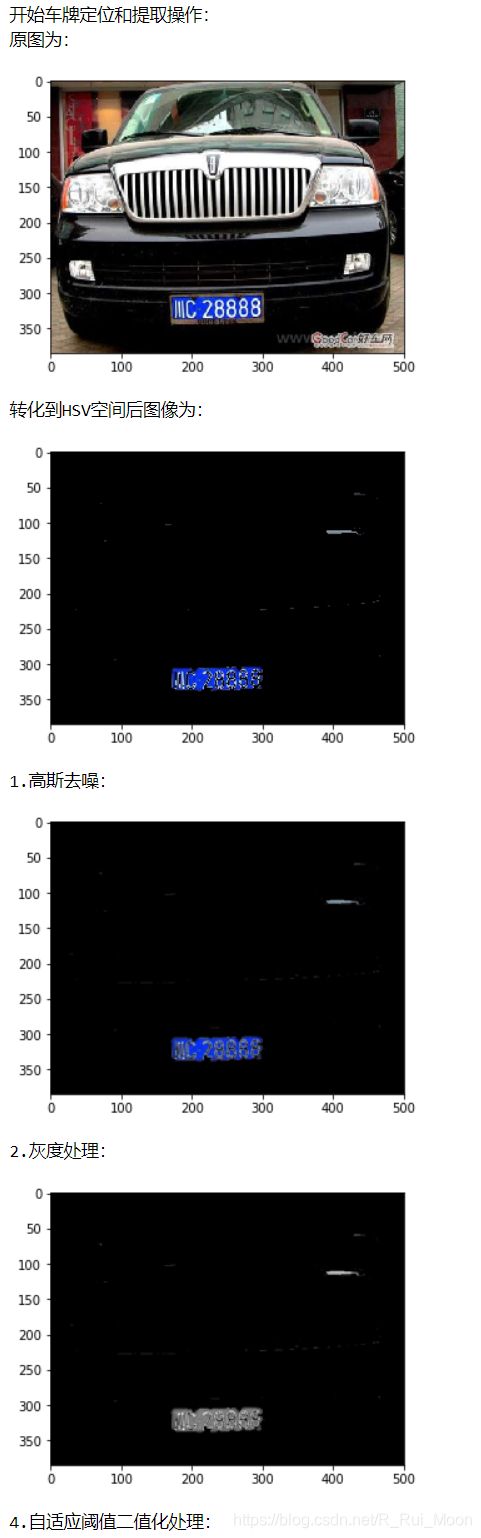
我是基于HSV转换取到大概率车牌的位置,然后高斯去噪,灰度处理,Sobel算法边缘检测(x方向检测,x方向结果较好),自适应阈值二值化处理,进行膨胀腐蚀,中值滤波去除噪点。不过HSV的mask图设置的为蓝色的阙值,只能识别蓝色车牌,如果要识别的绿色或黄色的车牌要换阙值.
形态学运算最好先为CLOSE运算,填充字块连在一起,效果不好可以调整核的大小以及迭代次数。花的最长时间在形态学的调试,要尝试不同的膨胀腐蚀的结果,达到最佳,才能定位好车牌。最后车牌轮廓检测,要选好提取轮廓的比例和矩形的大小,最好在图片处理前同一固定好图片大小,最后的到的满足条件的矩形作为车牌,最好另保存好图片,这样效果会好一点。
上面只是将车牌定位出来了,我们的目的是识别,但目前还不能直接识别出车牌里面的字符。第一次做法是对字符进行分割,然后再一个字符一个字符的识别。字符分割的方法有很多种,比如直方图切割,我们这里按比例分割:车牌样式是固定的,字符的大小也是固定的,就可以直接根据比例来分割出字符来,但是这样对上一步的要求就比较高,要求切割出来的车牌必须的方方正正的,要不然效果可能不如意。字符识别有OCR框架也有模板匹配,PIL。我选取的OCR框架识别单个字符,但效果非常差,所有最后我采取的方式是对车牌原图高斯去噪,灰度处理然后识别一次OCR得str1,二值化识别一次OCR的str2,最终车牌号为str1(汉字)+A_z(字母)+str2(数字/字母)。
图像处理的步骤有很多种方法,各有优点,大家可以自己去研究。目的就是为了找去我们要的那一块矩形区域。同时,我们用到的卷积核大小,都是自己调的,不一定要按照我这个来。
二、使用步骤
1.系统分析
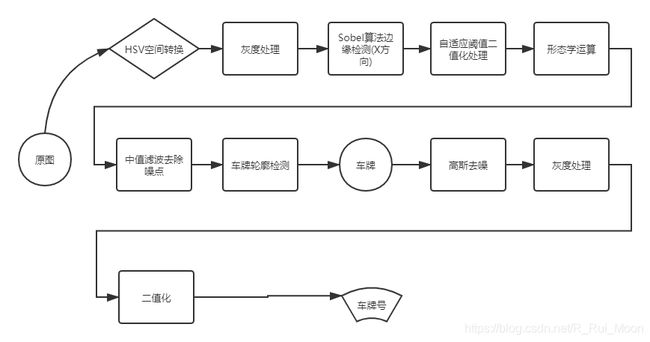
车牌识别的大体步骤:
获取图片->图像处理->车牌字符分割->字符识别

具体流程图:
2.事前定义函数
# 显示图片
def cv_show(name, img): # 生成窗口显示--opencv读取的格式是BGR
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# plt显示彩色图片
def plt_show0(img): # plt.imshow 是以RGB顺序保存
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
# plt显示灰度图
def plt_show(img):
plt.imshow(img, cmap='gray')
plt.show()
def my_cv_imread(filepath): # 解决python中OpenCV库读取图像函数不支持中文路径问题
# 使用imdecode函数进行读取
img = cv2.imdecode(np.fromfile(filepath,dtype=np.uint8),-1)
return img
3.车牌定位
def color_change(picture): # 将图片转化到HSV空间,并按位取反,突出车牌区域
#转化为HSV颜色空间
hsv=cv2.cvtColor(picture,cv2.COLOR_BGR2HSV)
# 函数通过设置不同的h、s、v的min和max阈值可以获取不同色彩的一个二值的mask图
lower_blue=np.array([100,43,46]) #蓝色阈值
upper_blue=np.array([124,255,255])
#构建掩模
mask=cv2.inRange(hsv,lower_blue,upper_blue)
#按位与操作函数
res1=cv2.bitwise_and(image,image,mask=mask)
plt_show0(res1)
# plt_show(res1) 通道数不对
return res1
def Gauss_image(img):# 高斯去噪
image = cv2.GaussianBlur(img, (3, 3), 0) # 高斯矩阵的长与宽都是3,标准差取0
plt_show0(image)
return image
def Gray_image(img): # 灰度处理
gray_image = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
plt_show(gray_image)
return gray_image
def Sobel_x_image(gray_image): # sobel算法边缘检测(x方向检测)
Sobel_x = cv2.Sobel(gray_image, cv2.CV_16S, 1, 0)
# Sobel函数求完导数后会有负值,还有会大于255的值。而原图像是uint8,即8位无符号数,所以Sobel建立的图像位数不够,会有截断。因此要使用16位有符号的数据类型
absX = cv2.convertScaleAbs(Sobel_x) # 将其转回原来的uint8形式。否则将无法显示图像,而只是一副灰色的窗口。
image1 = absX
plt_show(image)
# sobel算法边缘检测(y方向检测)
Sobel_y = cv2.Sobel(gray_image, cv2.CV_16S, 0, 1)
absY = cv2.convertScaleAbs(Sobel_y) # 将其转回原来的uint8形式。否则将无法显示图像,而只是一副灰色的窗口。
image2 = absY
plt_show(image2)
# 由于Sobel算子是在两个方向计算的,最后还需要用cv2.addWeighted(...)函数将其组合起来。
image3 = cv2.addWeighted(absX,0.5,absY,0.5,0)
plt_show(image3)
return image1
def Thre_image(sobel_img):# 自适应阈值二值化处理
ret, image = cv2.threshold(sobel_img, 0, 255, cv2.THRESH_OTSU) # image3 和 image1 结果差不多
plt_show(image)
return image
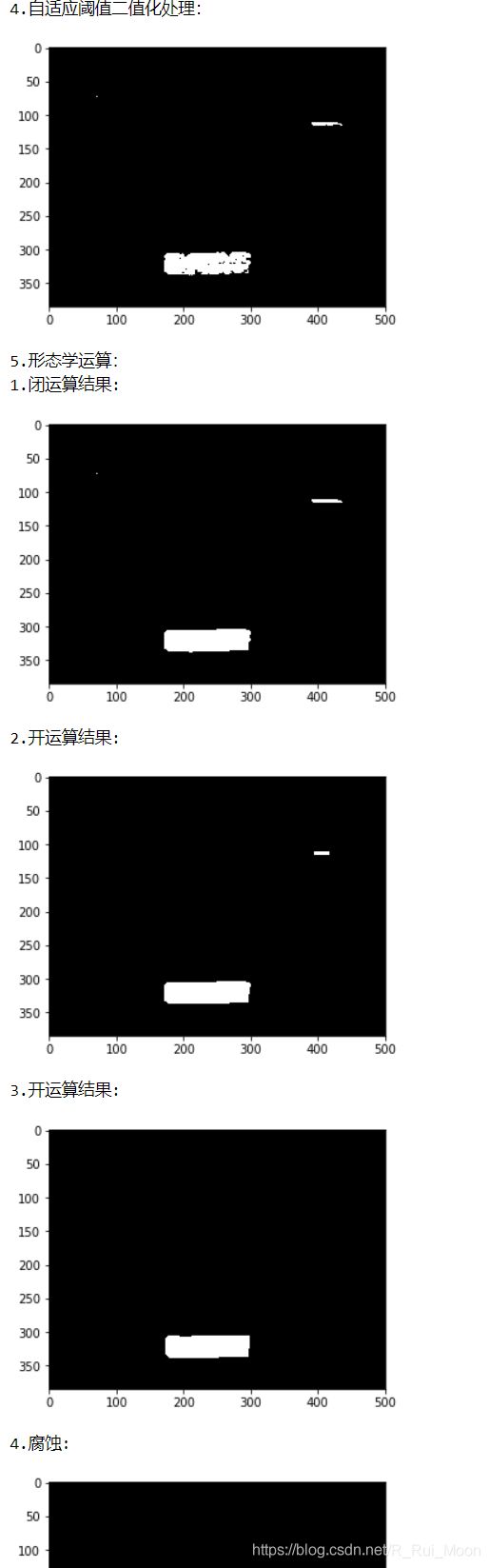
def Mor_image(binary_img): # 形态学运算
kernel = np.ones((5, 15), np.uint8)
# 先闭运算将车牌数字部分连接,再开运算将不是块状的或是较小的部分去掉
close_img = cv2.morphologyEx(binary_img, cv2.MORPH_CLOSE, kernel)
print('1.闭运算结果:')
plt_show(close_img)
open_img = cv2.morphologyEx(close_img, cv2.MORPH_OPEN, kernel)
print('2.开运算结果:')
plt_show(open_img)
kernel2 = np.ones((10, 10), np.uint8)
open_img2 = cv2.morphologyEx(open_img, cv2.MORPH_OPEN, kernel2)
print('3.开运算结果:')
plt_show(open_img2)
# 由于部分图像得到的轮廓边缘不整齐,因此再进行一次膨胀操作
element = cv2.getStructuringElement(cv2.MORPH_RECT, (4, 4)) # (2, 2)
# dilation_img = cv2.erode,dilate(open_img2, element,iterations=3) # iterations=2
dilation_img = cv2.erode(open_img2, element) # iterations=2
print('4.腐蚀:')
plt_show(dilation_img)
return dilation_img
def MB_image(image): # 中值滤波去除噪点
image = cv2.medianBlur(image, 15)
plt_show(image)
return image
def FindC_image(image, rawImage): # 车牌轮廓检测
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制轮廓
image1 = rawImage.copy()
cv2.drawContours(image1, contours, -1, (0, 255, 0), 5)
plt_show0(image1)
print ('轮廓数:', len(contours)) # 筛选出车牌位置的轮廓
i = 0
for c in contours:
x , y, w, h = cv2.boundingRect(c) # (x,y)是矩阵的左上点坐标
cv2.rectangle(image,(x,y),(x+w,y+h),(255,0,0),1)
w_rate_h = float(w/h)
#一般宽高比是3.14,(x+w,y+h)是矩阵的右下点坐标
if(w_rate_h >= 2.7 and w_rate_h <= 4): # 2.7
print('------------------')
print('宽高比:', w_rate_h)
lpimage = rawImage[y:y+h,x:x+w]
# 图片保存
plt_show0(lpimage)
# i=i+1
# path = "./car_license/"+str(i)+".png"
# print("提取车牌存放路径",path)
# cv2.imwrite(path, lpimage)
print('------------------')
else:
print('End---------------')
return lpimage
4.字符提取
def Mor_image_CN(binary_img): # 形态学运算
kernel = np.ones((1, 3), np.uint8)
img1 = cv2.morphologyEx(binary_img, cv2.MORPH_CLOSE, kernel)
print('1:')
plt_show(img1)
# kernel = np.ones((2, 2), np.uint8)
# img3 = cv2.morphologyEx(img1, cv2.MORPH_CLOSE, kernel)
# print('2:')
# plt_show(img3)
kernel = np.ones((2, 2), np.uint8)
img2 = cv2.morphologyEx(img1, cv2.MORPH_OPEN, kernel)
print('2:')
plt_show(img2)
# element = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2)) # (2, 2)
# # dilation_img = cv2.erodedilate(open_img2, element,iterations=3) # iterations=2
# dilation_img = cv2.dilate(img1, element) # iterations=2
# print('4:')
# plt_show(dilation_img)
return img2
def FindC_image_CN(image, rawImage):# 轮廓检测
# cv2.RETR_EXTERNAL 只检查外轮廓
# cv2.CHAIN_APPROX_SIMPLE 压缩垂直、水平、对角方向,只保留端点
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制轮廓
image1 = rawImage.copy()
cv2.drawContours(image1, contours, -1, (0, 255, 0), 1)
plt_show0(image1)
words = []
print ('轮廓数:', len(contours))
for item in contours:
word = []
x , y, w, h = cv2.boundingRect(item) # (x,y)是矩阵的左上点坐标
word.append(x)
print('x:', x)
word.append(y)
print('y:', y)
word.append(w)
print('w:', w)
word.append(h)
print('h:', h)
words.append(word)
words = sorted(words, key=lambda s:s[0], reverse=False)
print('words:\n', words)
i = 0
for word in words:
# if((word[3]> (word[2]*1.8)) and (word[3] <( word[2]*2.3))):
i = i+1
image = rawImage[word[1]:word[1]+word[3], word[0]:word[0]+word[2]]
plt_show0(image)
def cut_out(value1,value2):
'''
通过长宽比判断车牌的位置,并截取
'''
for contour in value1:
rect = cv2.minAreaRect(contour) #找出最小外接矩形 中心点、宽和高、角度
if rect[1][1]>rect[1][0]:
k=rect[1][1]/rect[1][0]
else:
k=rect[1][0]/rect[1][1]
if (k>2.5)&(k<5): #判断车牌的轮廓
a=cv2.boxPoints(rect) #获取外接矩形的四个点
box = np.int0(a)
aa=cv2.drawContours(value2, [box], -1, (0, 255, 0), 3) #找出车牌的位置
cv2.imwrite('aa.jpg',aa)
x=[]
y=[]
for i in range(4):
x.append(box[i][1])
y.append(box[i][0])
min_x=min(x)
max_x=max(x)
min_y=min(y)
max_y=max(y)
cut=image[min_x:max_x,min_y:max_y]
cv2.imwrite('333.jpg',cut)
return cut
def Split_image(image, image2): # 字符分割
w = int(image.shape[1]/15)
img1 = image[:image.shape[0]-1, 0:2*w]
OCR_image3(img1)
plt_show(img1)
# img2 = image[1:image.shape[0]-1, 2*w:4*w]
# OCR_image1(img2)
# plt_show(img2)
img3 = image2[:image.shape[0]-1, 5*w:]
OCR_image1(img3)
plt_show(img3)
# img4 = image[1:image.shape[0]-1, 7*w:9*w]
# OCR_image1(img4)
# plt_show(img4)
# img5 = image[1:image.shape[0]-1, 9*w:11*w]
# OCR_image1(img5)
# plt_show(img5)
# img6 = image[1:image.shape[0]-1, 9*w:11*w]
# OCR_image1(img6)
# plt_show(img6)
# img7 = image[1:image.shape[0]-1, 13*w:]
# OCR_image1(img7)
# plt_show(img7)
def OCR_image(image): # OCR直接识别
code = pytesseract.image_to_string(image)
print(f'code:+{code}+')
return code
def OCR_image1(image): # OCR-单个文本行-识别
code = pytesseract.image_to_string(image, config='--psm 7')
print(f'code:+{code}+')
return code
def OCR_image2(image): # OCR-简体汉字-单个文本行-识别
code = pytesseract.image_to_string(image, lang='chi_sim', config='--psm 7')
print(f'code:+{code}+')
return code
def OCR_image3(image): # OCR-简体汉字-单个词-识别
code = pytesseract.image_to_string(image, lang='chi_sim', config='--psm 8')
print(f'code:+{code}+')
return code
5.程序运行界面截图