在上一篇博文《分布式机器学习中的模型聚合》(链接:https://www.cnblogs.com/orion-orion/p/15635803.html)中,我们关注了在分布式机器学习中模型聚合(参数通信)的问题,但是对每一个client具体的模型架构设计和参数优化方法还没有讨论。本篇文章我们关注具体模型结构设计和参数优化。
首先,在我follow的这篇篇论文[1]中(代码参见[2])不同的client有一个集成模型,而每一个集成模型由多个模型分量组成,可以表示为如下图:
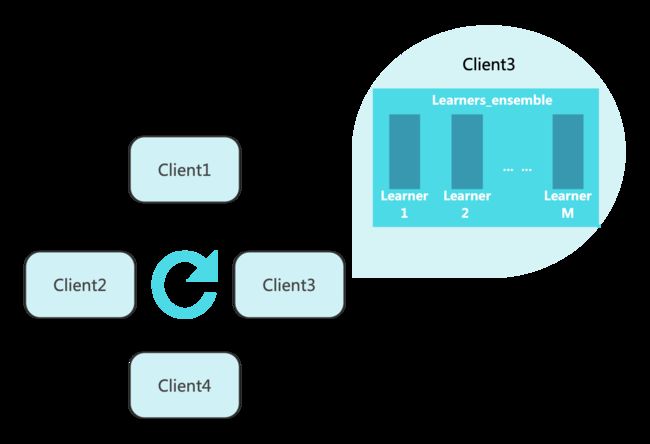
接下来我们就自顶向下地分层次展示Client、Learners_ensemble和每个Learner的设计原理。
1. Client
Client是每一个Client任务节点的类设计,它提供与模型类相似的get_next_batch()方法和step方法供我们前面在博客《分布式机器学习中的模型聚合》中讲过的aggregator类调用。但是我们需要认识到,我们在操纵Client时,实际上就在操纵其Learners_ensemble,也就是在操纵所有的Learner模型分量。
它包含的方法核心如下:

其具体代码实现如下:
class Client(object):
r"""一个Client任务节点
"""
def __init__(
self,
learners_ensemble,
train_iterator,
val_iterator,
test_iterator,
logger,
local_steps,
tune_locally=False
):
# 本地的learners_ensemble模型
self.learners_ensemble = learners_ensemble
self.n_learners = len(self.learners_ensemble)
self.tune_locally = tune_locally
# 表示是否进行本地调整,我们先化繁为简,略过这一功能
if self.tune_locally:
self.tuned_learners_ensemble = deepcopy(self.learners_ensemble)
else:
self.tuned_learners_ensemble = None
# 表示是否为二分类问题
self.binary_classification_flag = self.learners_ensemble.is_binary_classification
# 需要保存train,val,test的DataLoader(因为每个Client对应一个不同的数据集)
# 保存DataLoader的好处是只需要对象初始化时设置好DataLoader,后续step时便不用传入数据
# 这里"iterator"其实都是torch.utils.data.DataLoader对象
# 使用前需要使用iter(train_iterator)来转换为迭代器(用for迭代的话默认转型)
self.train_iterator = train_iterator
self.val_iterator = val_iterator
self.test_iterator = test_iterator
# 由train_iterator创造迭代器
self.train_loader = iter(self.train_iterator)
self.n_train_samples = len(self.train_iterator.dataset)
self.n_test_samples = len(self.test_iterator.dataset)
# 记录每一个分量模型中每一个样本的权重(0~1之间)
self.samples_weights = torch.ones(self.n_learners, self.n_train_samples) / self.n_learners
self.local_steps = local_steps
self.counter = 0 # 记录进行优化步骤step的次数
self.logger = logger
def get_next_batch(self):
"""
带异常判断(安全)地从train_loader(由train_iterator)构建的迭代器中读一个batch
如果数据集已经读至末尾,则循环读取
"""
try:
batch = next(self.train_loader)
except StopIteration:
self.train_loader = iter(self.train_iterator)
batch = next(self.train_loader)
return batch
def step(self, single_batch_flag=False, *args, **kwargs):
"""
进行client的一个训练step
:参数 single_batch_flag: 若为true, client只使用一个batch进行更新
:返回 clients_updates: ()
"""
self.counter += 1 # 迭代步数+1
self.update_sample_weights()
self.update_learners_weights()
# 最终的优化步落实到learners_ensemble上
if single_batch_flag:
batch = self.get_next_batch()
# 若已设定了一次只使用一个batch,则从train_loader中读一个batch
client_updates = \
self.learners_ensemble.fit_batch(
batch=batch,
weights=self.samples_weights
)
else:
# 否则,将迭代器train_iterator传入
client_updates = \
self.learners_ensemble.fit_epochs(
iterator=self.train_iterator,
n_epochs=self.local_steps,
weights=self.samples_weights
)
return client_updates
def write_logs(self):
r"""
记录train和test数据的loss和acc,后面控制台会打印输出。
注意,此处评估调用tuned_learners_ensemble中的evaluate_iterator()方法进行模型评估并记录,
evaluate_iterator()方法具体实现我们后面会介绍
"""
def update_sample_weights(self):
# 此方法用于更新每个样本的权重,
# 在MixtureClient任务类中重写
pass
def update_learners_weights(self):
# 此方法用于更新每个分量模型的权重,
# 在MixtureClient任务类中重写
pass
注意,以上Client类还未对update_learners_weights、update_sample_weights这两个方法进行定义。定义在如下的MixtureClient中:
class MixtureClient(Client):
def update_sample_weights(self):
all_losses = self.learners_ensemble.gather_losses(self.val_iterator)
self.samples_weights = F.softmax((torch.log(self.learners_ensemble.learners_weights) - all_losses.T), dim=1).T
def update_learners_weights(self):
self.learners_ensemble.learners_weights = self.samples_weights.mean(dim=1)
2. Learners_ensemble
Learners_ensemble是多个分量模型的集成。在优化模型时需要分别对多个模型分量进行优化。在模型输出时,采用多个分量模型加权平均的输出方式。
此外,Learners_ensemble还提供evaluate_iterator()方法来完成对模型的评估(该方法得到的评估数值是所有模型分量的平均),供上层Client类调用。
它包含的方法核心如下:

其具体代码实现如下:
class LearnersEnsemble(object):
"""
由多个分量Learners集成的LearnersEnsemble.
(是一个可迭代对象,重写了_iter_,_getitem_,_len_方法)
"""
def __init__(self, learners, learners_weights):
self.learners = learners
self.learners_weights = learners_weights
# 假设所有learners的特征维度一样
self.model_dim = self.learners[0].model_dim
# 布尔标识是分类还是回归任务
self.is_binary_classification = self.learners[0].is_binary_classification
# 默认所有learners的device和metric一样
self.device = self.learners[0].device
self.metric = self.learners[0].metric
def fit_batch(self, batch, weights):
"""
使用一个batch更新各learner分量.
:参数 batch: 元组 (x, y, indices)
:参数 weights: tensor类型,每个样本对应的权重(可为None)
:返回 client_updates: np.array类型,大小为(n_learners, model_dim): 用于衡量ensemble中每个learner的新旧参数之间的差异
"""
#记录每一个learners的参数的每一个维度的更新量
client_updates = torch.zeros(len(self.learners), self.model_dim)
for learner_id, learner in enumerate(self.learners):
old_params = learner.get_param_tensor()
if weights is not None:
learner.fit_batch(batch=batch, weights=weights[learner_id])
else:
learner.fit_batch(batch=batch, weights=None)
params = learner.get_param_tensor()
client_updates[learner_id] = (params - old_params)
return client_updates.cpu().numpy()
def fit_epochs(self, iterator, n_epochs, weights=None):
"""
多次遍历训练集(即多个epochs)更新各learner分量.
:参数 n_epochs: 使用训练集的epochs轮数
:参数 weights: tensor类型,每个样本对应的权重(可为None)
:返回 client_updates: np.array类型,大小为(n_learners, model_dim): 用于衡量ensemble中每个learner的新旧参数之间的差异
"""
client_updates = torch.zeros(len(self.learners), self.model_dim)
for learner_id, learner in enumerate(self.learners):
old_params = learner.get_param_tensor()
if weights is not None:
learner.fit_epochs(iterator, n_epochs, weights=weights[learner_id])
else:
learner.fit_epochs(iterator, n_epochs, weights=None)
params = learner.get_param_tensor()
client_updates[learner_id] = (params - old_params)
return client_updates.cpu().numpy()
def evaluate_iterator(self, iterator):
"""
用迭代器指向的数据评估learners.
:参数 iterator: yields x, y, indices
:返回: global_loss, global_acc(测试数据的)
"""
if self.is_binary_classification:
criterion = nn.BCELoss(reduction="none")
else:
criterion = nn.NLLLoss(reduction="none")
for learner in self.learners:
# 将各learner模型设置为evaluation模式
learner.model.eval()
global_loss = 0.
global_metric = 0.
n_samples = 0
with torch.no_grad():
for (x, y, _) in iterator:
x = x.to(self.device).type(torch.float32)
y = y.to(self.device)
n_samples += y.size(0)
y_pred = 0.
for learner_id, learner in enumerate(self.learners):
# 注意一,这里sigmoid和softmax写在model类外,更具灵活性,
# 但一般我们仍然将其看做分类器h(x)的一部分
# 注意二,此处实质上采用各分类器输出进行加权平均集成
if self.is_binary_classification:
y_pred += self.learners_weights[learner_id] * torch.sigmoid(learner.model(x))
else:
y_pred += self.learners_weights[learner_id] * F.softmax(learner.model(x), dim=1)
y_pred = torch.clamp(y_pred, min=0., max=1.)
if self.is_binary_classification:
y = y.type(torch.float32).unsqueeze(1)
global_loss += criterion(y_pred, y).sum().item()
y_pred = torch.logit(y_pred, eps=1e-10)
else:
global_loss += criterion(torch.log(y_pred), y).sum().item()
global_metric += self.metric(y_pred, y).item()
return global_loss / n_samples, global_metric / n_samples
def gather_losses(self, iterator):
"""
汇集各learner模型关于迭代的所有样本的losses
:参数 iterator:
:返回: tensor (n_learners, n_samples) ,各learner关于所迭代的数据集所有样本的loss
"""
n_samples = len(iterator.dataset)
all_losses = torch.zeros(len(self.learners), n_samples)
for learner_id, learner in enumerate(self.learners):
all_losses[learner_id] = learner.gather_losses(iterator)
return all_losses
def free_memory(self):
"""
释放模型权重
"""
for learner in self.learners:
learner.free_memory()
def free_gradients(self):
"""
释放模型梯度
"""
for learner in self.learners:
learner.free_gradients()
# 以下三个方法说明LearnersEnsemble是个可迭代对象
def __iter__(self):
return LearnersEnsembleIterator(self)
def __len__(self):
return len(self.learners)
def __getitem__(self, idx):
return self.learners[idx]
3. Learner
Learner相当于在具体的诸如CNN、RNN等模型之上进行的一层包装,实现了模型训练的接口,其属性Learner.model即具体的模型对象,来自类似与下列的模型类:
class CIFAR10CNN(nn.Module):
def __init__(self, num_classes):
super(CIFAR10CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 5)
self.fc1 = nn.Linear(64 * 5 * 5, 2048)
self.output = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 5 * 5)
x = F.relu(self.fc1(x))
x = self.output(x)
return x
它包含的方法核心如下:

其具体代码实现如下:
class Learner:
"""
负责训练并评估一个(深度)学习器
属性
----------
model (nn.Module): learner训练的模型
criterion (torch.nn.modules.loss): 训练`model`所用的损失函数,这里我们设置reduction="none",也就是默认一个batch的loss返回一个向量而不求和/平均
metric (fn): 模型评价指标对应的函数, 输入两个向量输出一标量
device (str or torch.device):
optimizer (torch.optim.Optimizer):
lr_scheduler (torch.optim.lr_scheduler):
is_binary_classification (bool): 是否将labels转换为float, 如果使用 `BCELoss`
(用于分类的交叉熵损失函数)这里必须要设置为True
方法
------
optimizer_step: 进行一轮优化迭代, 需要梯度已经被计算完毕
fit_batch: 对一个批量进行一轮优化迭代
fit_epoch: 单次遍历iterator中的得到的所有样本,进行一系列批量的迭代
fit_epochs: 多次遍历将从iterator指向的训练集
gather_losses:收集iterator迭代器所有样本的loss并拼接输出
get_param_tensor: 获取获取一个flattened后的`model`的参数
free_memory: 释放模型权重
free_gradients: 释放模型梯度
"""
def __init__(
self, model,
criterion,
metric,
device,
optimizer,
lr_scheduler=None,
is_binary_classification=False
):
self.model = model.to(device)
self.criterion = criterion.to(device)
self.metric = metric
self.device = device
self.optimizer = optimizer
self.lr_scheduler = lr_scheduler
self.is_binary_classification = is_binary_classification
self.model_dim = int(self.get_param_tensor().shape[0])
def optimizer_step(self):
"""
执行一轮优化迭代,调用之前需要反向传播先算好梯度(即已调用loss.backward())
"""
self.optimizer.step()
if self.lr_scheduler:
self.lr_scheduler.step()
def fit_batch(self, batch, weights=None):
"""
基于来自`iterator`的一个batch的样本执行一轮优化迭代
:参数 batch (元组(x, y, indices)):
:参数 weights(tensor): 每个样本的权重,可为none
:返回: loss.detach(), metric.detach()(训练数据)
"""
self.model.train()
x, y, indices = batch
x = x.to(self.device).type(torch.float32)
y = y.to(self.device)
if self.is_binary_classification:
y = y.type(torch.float32).unsqueeze(1)
self.optimizer.zero_grad()
y_pred = self.model(x)
loss_vec = self.criterion(y_pred, y)
metric = self.metric(y_pred, y) / len(y)
if weights is not None:
weights = weights.to(self.device)
loss = (loss_vec.T @ weights[indices]) / loss_vec.size(0)
else:
loss = loss_vec.mean()
loss.backward()
self.optimizer.step()
if self.lr_scheduler:
self.lr_scheduler.step()
return loss.detach(), metric.detach()
def fit_epoch(self, iterator, weights=None):
"""
将来自`iterator`的所有batches遍历一次,进行优化迭代
:参数 iterator(torch.utils.data.DataLoader):
:参数 weights(torch.tensor): 存储每个样本权重的向量,可为None
:return: loss.detach(), metric.detach() (训练数据)
"""
self.model.train()
global_loss = 0.
global_metric = 0.
n_samples = 0
for x, y, indices in iterator:
x = x.to(self.device).type(torch.float32)
y = y.to(self.device)
n_samples += y.size(0)
if self.is_binary_classification:
y = y.type(torch.float32).unsqueeze(1)
self.optimizer.zero_grad()
y_pred = self.model(x)
loss_vec = self.criterion(y_pred, y)
if weights is not None:
weights = weights.to(self.device)
loss = (loss_vec.T @ weights[indices]) / loss_vec.size(0)
else:
loss = loss_vec.mean()
loss.backward()
self.optimizer.step()
global_loss += loss.detach() * loss_vec.size(0)
global_metric += self.metric(y_pred, y).detach()
return global_loss / n_samples, global_metric / n_samples
def gather_losses(self, iterator):
"""
计算来自iterator的样本中的所有losses并拼接为all_losses
:参数 iterator(torch.utils.data.DataLoader):
:return: 所有来自iterator.dataset样本的losses拼成的tensor
"""
self.model.eval()
n_samples = len(iterator.dataset)
all_losses = torch.zeros(n_samples, device=self.device)
with torch.no_grad():
for (x, y, indices) in iterator:
x = x.to(self.device).type(torch.float32)
y = y.to(self.device)
if self.is_binary_classification:
y = y.type(torch.float32).unsqueeze(1)
y_pred = self.model(x)
all_losses[indices] = self.criterion(y_pred, y).squeeze()
return all_losses
def fit_epochs(self, iterator, n_epochs, weights=None):
"""
执行多个n_epochs的训练
:参数 iterator(torch.utils.data.DataLoader):
:参数 n_epochs(int):
:参数 weights: 每个样本权重的向量,可为None
:返回: None
"""
for step in range(n_epochs):
self.fit_epoch(iterator, weights)
if self.lr_scheduler is not None:
self.lr_scheduler.step()
def get_param_tensor(self):
"""
将所有模型参数做为一个flattened的一维张量输出
:返回: torch.tensor
"""
param_list = []
for param in self.model.parameters():
param_list.append(param.data.view(-1, ))
return torch.cat(param_list)
def get_grad_tensor(self):
"""
将 `model` 所有参数的梯度做为flattened的一维张量输出
:返回: torch.tensor
"""
grad_list = []
for param in self.model.parameters():
if param.grad is not None:
grad_list.append(param.grad.data.view(-1, ))
return torch.cat(grad_list)
def free_memory(self):
"""
释放模型权重
"""
del self.optimizer
del self.model
def free_gradients(self):
"""
释放模型梯度
"""
self.optimizer.zero_grad(set_to_none=True)
3. Client、Learners_ensemble、Learner的对比
三者的对比架构图如下:
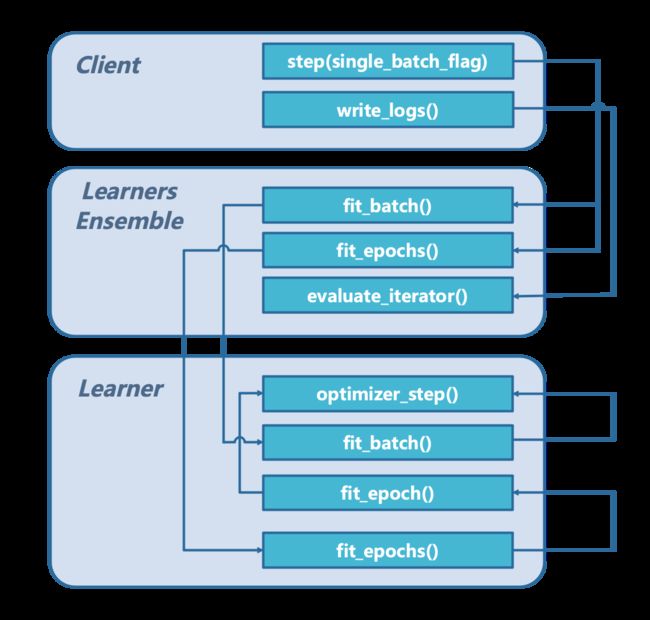
其中,\(A\)方法指向\(B\)方法的箭头代表在\(A\)方法中调用\(B\)方法。
我们可以看到,我们在上一篇博文《分布式机器学习中的模型聚合》(链接:https://www.cnblogs.com/orion-orion/p/15635803.html)中所调用的函数client.step()以及client.write_logs()下层其实还封装着这么多的实现。
需要指出的是,模型的梯度计算和参数更新最终是要落实到Learner类去完成,不过模型的评估我们直接在LearnersEnsemble类即可完成,而不需要在Learner类去单独设计一个方法。
4. 模型测试
我们采用CIFAR10 数据集对论文提出的模型进行测试,可以看到测试效果不错。预设迭代200各epoch,迭代了9各epoch我们就已经达到 Train Acc: 73.587%,Test Acc: 70.577% ,虽然和论文最终宣称的78.1%尚差距,不过最终应该能达到该精度,可见论文声称的结果很大程度上还是靠谱的。
==> Clients initialization..
===> Building data iterators..
0%| | 0/80 [00:00 Initializing clients..
0%| | 0/80 [00:00 Test Clients initialization..
===> Building data iterators..
0it [00:00, ?it/s]
0it [00:00, ?it/s]
===> Initializing clients..
0it [00:00, ?it/s]
0it [00:00, ?it/s]
++++++++++++++++++++++++++++++
Global..
Train Loss: 2.299 | Train Acc: 10.643% |Test Loss: 2.298 | Test Acc: 10.503% |
++++++++++++++++++++++++++++++++++++++++++++++++++
################################################################################
Training..
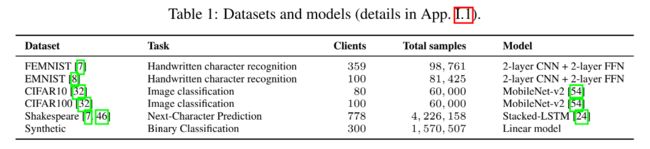
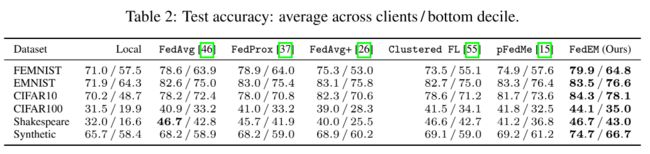
0%| | 0/200 [00:00这里附上论文中数据集和其采用模型的对应关系和论文中所声称的在以上各数据集中能达到的精度。
参考文献
- [1] Marfoq O, Neglia G, Bellet A, et al. Federated multi-task learning under a mixture of distributions[J]. Advances in Neural Information Processing Systems, 2021, 34.
- [2] https://github.com/omarfoq/FedEM