win10上成功运行faster-rcnn.pytorch-1.0
血泪踩坑史
win10 + Anaconda3 + python3.6 + cuda10.1 update2 + pytorch1.4
- 环境配置
-
- 1 CUDA
- 2 虚拟环境
- 3 安装pytorch
- 4 安装依赖包
- 5 编译CUDA依赖环境
- 训练自己的数据集
-
- 1 试跑公共数据集
- 2 准备自己的数据集
- 3 网络参数修改
- 4 命令行运行
环境配置
源码:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
遇到报错时可参考其他贴子:
安装faster-rcnn pytorch1.0.0版本以及importerror cannot import name ‘_mask’
win10和win7系统配置faster rcnn(pytorch)
Faster RCNN pytorch 1.0版调试(踩坑)过程记录
1 CUDA
卸载cuda:教程
安装cuda10.1 update2(又叫cuda10.1.243):下载地址 + 教程
注意不要勾选Visual Studio Integration 以及 当前版本比新版本高的Driver
安装cudnn:下载地址 + 教程
安装CUDA时出现的问题:
The following processes must be stopped before the Nsight Systems
installation can proceed: Microsoft Visual Studio 2019 (Process ID:
15576)
解决:
关闭VS, 关不掉的话重启计算机
2 虚拟环境
删除旧环境
conda remove -n your_env_name --all
创建新环境
conda create --name your_env_name python=3.6
激活环境
activate your_env_name
3 安装pytorch
conda install pytorch==1.4.0 torchvision==0.5.0 cudatoolkit=10.1 -c pytorch
4 安装依赖包
cd F:\code\faster-rcnn.pytorch-pytorch-1.0 // 来到源码中requirements.txt所在的目录下
pip install -r requirements.txt
5 编译CUDA依赖环境
cd lib
python setup.py build develop
出现以下提示说明编译成功(为啥字体变黄了…
Installed f:\code\faster-rcnn.pytorch-pytorch-1.0\lib Processing
dependencies for faster-rcnn0.1 Finished processing dependencies for
faster-rcnn0.1
pytorch-0.4到这一步就卡住了,所以不建议使用
训练自己的数据集
1 试跑公共数据集
【下载Pascal_VOC数据集】(也可以直接训练自己的数据
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
解压
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tar
【准备权重文件】:
地址,源码的作者已经贴出来了
深度学习常用预训练网络模型的下载地址
在faster-rcnn.pytorch-pytorch-1.0文件夹下创建data,data文件夹下创建pretrained_model,把下好的权重文件放里面
【配置pycharm】
File-settings-python interpreter
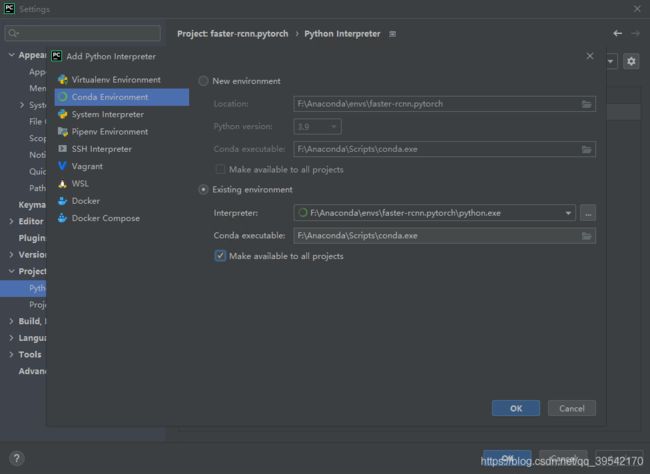
【问题】
ModuleNotFoundError: No module named ‘pycocotools._mask’
解决:安装COCO API
cd data
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI
make
若安装时报错,可参考解决方案
【问题】
ImportError: cannot import name ‘imread’
解决:将scipy降级
pip install scipy==1.2.1
【问题】
RuntimeError: Not implemented on the CPU (ROIAlign_backward at
/faster-rcnn.pytorch/lib/model/csrc/ROIAlign.h:44)
解决:打开cmd
python trainval_net.py --cuda
2 准备自己的数据集
【数据集结构】:
真正有用的就这些

【每次更新训练数据集都需要删缓存】
faster-rcnn.pytorch/output/vgg16/voc_2007_trainval/default
faster-rcnn.pytorch/data/cache
faster-rcnn.pytorch/data/VOCdevkit2007/annotations_cache
重点是data/cache/voc_2007_trainval_gt_roidb.pkl
【参考代码】出处忘记了
YOLO格式转换为VOC格式
# yolo格式的换成voc
import os
import xml.etree.ElementTree as ET
from PIL import Image
import numpy as np
img_path = 'F:/data/VOC2007/JPEGImages/' #原图.jpg文件的路径
labels_path = 'F:/data/VOC2007/Annotations五项/txt/' #labels中.txt文件的路径
annotations_path = 'F:/data/VOC2007/Annotations五项/xml/' #生成的xml文件需要保存的路径
labels = os.listdir(labels_path)
clsnames_path = 'F:/data/VOC2007/Annotations五项/classes.txt' #names文件的路径
with open(clsnames_path,'r') as f:
classes = f.readlines()
classes = [cls.strip('\n') for cls in classes]
def write_xml(imgname,filepath,labeldicts): #参数imagename是图片名(无后缀)
root = ET.Element('Annotation') #创建Annotation根节点
ET.SubElement(root, 'filename').text = str(imgname) #创建filename子节点(无后缀)
sizes = ET.SubElement(root,'size') #创建size子节点
ET.SubElement(sizes, 'width').text = '1280' #没带脑子直接写了原图片的尺寸......
ET.SubElement(sizes, 'height').text = '720'
ET.SubElement(sizes, 'depth').text = '3' #图片的通道数:img.shape[2]
for labeldict in labeldicts:
objects = ET.SubElement(root, 'object') #创建object子节点
ET.SubElement(objects, 'name').text = labeldict['name'] #BDD100K_10.names文件中
#的类别名
ET.SubElement(objects, 'pose').text = 'Unspecified'
ET.SubElement(objects, 'truncated').text = '0'
ET.SubElement(objects, 'difficult').text = '0'
bndbox = ET.SubElement(objects,'bndbox')
ET.SubElement(bndbox, 'xmin').text = str(int(labeldict['xmin']))
ET.SubElement(bndbox, 'ymin').text = str(int(labeldict['ymin']))
ET.SubElement(bndbox, 'xmax').text = str(int(labeldict['xmax']))
ET.SubElement(bndbox, 'ymax').text = str(int(labeldict['ymax']))
tree = ET.ElementTree(root)
tree.write(filepath, encoding='utf-8')
for label in labels: #批量读.txt文件
with open(labels_path + label, 'r') as f:
img_id = os.path.splitext(label)[0]
contents = f.readlines()
labeldicts = []
for content in contents:
img = np.array(Image.open(img_path+label.strip('.txt') + '.jpg'))
sh,sw = img.shape[0],img.shape[1] #img.shape[0]是图片的高度720
#img.shape[1]是图片的宽度720
content = content.strip('\n').split()
x=float(content[1])*sw
y=float(content[2])*sh
w=float(content[3])*sw
h=float(content[4])*sh
new_dict = {
'name': classes[int(content[0])],
'difficult': '0',
'xmin': x+1-w/2, #坐标转换公式看另一篇文章....
'ymin': y+1-h/2,
'xmax': x+1+w/2,
'ymax': y+1+h/2
}
labeldicts.append(new_dict)
write_xml(img_id, annotations_path + label.strip('.txt') + '.xml', labeldicts)
VOC数据集制作——ImageSets\Main里的四个txt文件
# VOC数据集制作——ImageSets\Main里的四个txt文件
# 0.6 : 0.2 : 0.2
import os
import random
trainval_percent = 0.8
train_percent = 0.75
xmlfilepath = 'F:/data/VOC2007/Annotations'
txtsavepath = 'F:/data/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
3 网络参数修改
参考:
Faster-RCNN.pytorch的搭建、使用过程详解(适配PyTorch 1.0以上版本)
faster-rcnn.pytorch-1.0的jwyang当前最火版本代码复现与讲解
1)"/faster-rcnn.pytorch/lib/datasets/pascal_voc.py"
self._classes = ('__background__', # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor','plane')
2)demo.py
同理
4 命令行运行
不知道为啥,pycharm运行老是报错…
训练命令行示例:
python trainval_net.py --cuda
CUDA_VISIBLE_DEVICES=0,1 python trainval_net.py --dataset pascal_voc --net res101 --cuda
使命令永久的在后台执行:
nohup python trainval_net.py --dataset pascal_voc --net res101 --epochs 10 --bs 4 --lr 0.01 --lr_decay_step 8 --cuda &
测试命令行示例:
python test_net.py --dataset pascal_voc --net res101 --checksession 1--checkepoch 3--checkpoint 10021--cuda
其中,checksession = 1,checkepoch = 3, checkpoint = 10021,对应到模型“faster_rcnn_1_3_10021”
model测试示例:
python demo.py --net res101 --checksession 1 --checkepoch 20 --checkpoint 233 --cuda --load_dir '/usr/detectron/faster-rcnn.pytorch-pytorch-1.0/tools/models/'