2021 DevFest上海谷歌开发者节已于近期圆满落幕。格物钛与28w+ 线上观众、1300+ 线下开发者、工程师和行业重磅嘉宾一起尽享了一场技术盛宴。格物钛作为参展企业,创始人兼CEO崔运凯受邀发言,与开发者们分享了从DevOps到MLOps的进化路程,从组织变革看机器学习的最佳实践。
特斯拉的 AI 高级总监 Andrej Karpathy 定义了 Software 2.0 时代,即以 MLOps 组织开发模式为主的时代,那么它的前身 Software 1.0是什么?格物钛创始人兼CEO崔运凯从三十年前的软件开发时代讲起:在 DevOps (Software 1.0) 的开发时代,软件开发以代码为中心,通过编程语言,完全基于程序员们手动编写代码来实现某项功能。Software1.0 的演进历史分为下面四个方面:
软件发布时效的演进
以往每两年发布一次更新,用户需购买相应光盘,推演到现在每天都有新的版本发布。这样看似时间跨度小的变化从何而来?又如何推动企业发展?如果你的软件发布速度比别人快,那么你在竞争当中的优势有:
1) 也许可以尽快切入更多市场,因为你比别人较快的发布最新 features,你的 idea 比别人更早上线
2) 试错成本不断降低,因为在有限相同的时间内,你更快速的上线、下线,尝试不同的东西。

软件开发的演进
从 Waterfall 瀑布式发布流程到 Agile 敏捷式开发流程的转变中,一个显著的改进是迭代时间缩短。因为软件开发的方式是服务于软件发布是间的,而线性开发(前者)流程导致效率过低,故催生敏捷式开发的应用,其优势在于小版本快速迭代,以用户需求为核心。虽然瀑布式发布流程的模块在敏捷式开发流程种有,但是后者每次只发布少量的 features,然后通过自动化工具让流程自动化运转。如果说瀑布式是由项目经理人工推动发布的,那么敏捷式就是由流水线自然推动发布的。

于是就有了各种自动化管理工具的诞生:
协作和版本管理工具的演进
版本管理的出现主要配合协作上面提到的开发方式,尽可能实现流程自动化。以往集中式文件版本管理系统效率低、复杂,而开源的分布式版本控制具有强大的分支管理,使得协作灵活、可靠。比如git。

工具变化以后,使用工具的组织也发生了结构性变化:
软件开发组织的演进
从全员软件工程师的团队优化到软件工程师+自动化工具工程师合作的分层组织。有些工程师的工作是开发维护自动化工具,这些工具去赋能其他的软件工程师。

一句话总结 DevOps 的核心:为了让团队成员更加专注于自己的职能,需要管理跨越职能的协作。简单来讲,开发的人要懂运维,运维的人要懂开发。
回到开头,Andrew Karpathy 定义的 MLOps (Software 2.0) 的理念,是指软件开发以代码和数据为中心,通过 AI 技术寻找解决问题的方法。你定义好输入和输出,中间的逻辑和对应关系由机器学习决定。通过编程语言,以及大量相关数据,在程序空间通过随机梯度下降(Stochastic Gradient Descent, SGD) 和反向传播寻找可以完成特定任务的程序,以机器为主导,自动完成特定任务。
大家曾在学校学过典型的机器学习项目流程如图:
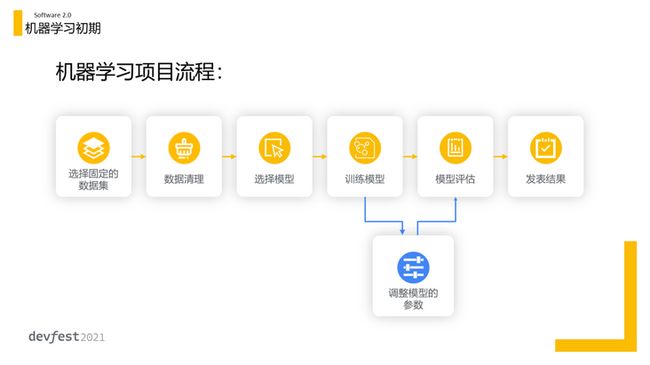
然而在工业界,随着项目体量的增加,由于数据不足,需要 Data Operation 团队来负责数据采集、数据标注和数据清洗。比如在无人驾驶领域,你可能曾用 KITTI 公开数据集进行练习,可是当进入工业界你发现数据完全不够。你需要采集数据时,而采集数据本身太复杂以至于你需要一个多层级的组织来完成。当采集的数据量超过硬盘大小时,又需要 Infrastructure Team 负责开发分布式系统。当你将数据放入模型以后,因为一直有新的模型出现,算法工程师需要不断对同一份数据尝试新的算法。每个模型又有非常多的超参,你又需要(雇人)调优不同的超参数…由于数据漂移、概念漂移,需要重新收集数据,重新训练。
由于需要的数据越来越多、工作量加大,那么跨组织的、重复性的工作希望被自动化,才能满足开发流程的需要。

那么产品开发的组织又如何升级呢?简单来说是通过多层级的组织,不同的人各司不同职能。那么组织如何流水线化?答案是需要自动化的工具 ,通过MLOps进行串联。

崔运凯认为上述公司定义的 MLOps 偏向 DevOps 风格的定义,而他创立的格物钛则在探索 MLOps 的本质与 MLOps 可提升的方向:

整个机器学习产品迭代分为两大流派
1. 以模型为中心的 AI (Model-Centric)
2. 以数据为中心的AI (Data-Centric)
大量的算法工程师倾向于通过调整模型来获得更好的效果,但实际上根据谷歌 2015年发布的一篇名为Hidden Technical Debt in Machine Learning Systems 的论文,绝大多数的工程师花了大量时间在数据上。

形象地讲,经典的 Model-Centric 是固定一组数据在多个模型种评估模型表现,而 Data-Centric 则是固定一个模型(BERT)去找更高质量的数据,使得整体系统性能更佳。
不过,上述两种模式不是非此即彼的关系,在不同的 AI 产品开发时间线条,模型的选择有讲究:早期在数据数量有限时,使用 Model-Centric的方式是为了找到一个合适的 model;当这个模型慢慢确定后,慢慢进入Data Centric 阶段,目的是通过提高数据质量来提高整体性能。

如下图所示,Data-Centric带来的性能提升显著大于 Model-Centric 所带来的。

格物钛从数据的角度给出四点 MLOps 所具有的特点
- 整个机器学习开发过程要对数据进行多次处理转换(data transforming)
- 数据转换可以手动,也可以自动化
- 整个机器学习项目有多个组织或机构参与
- 需要一个 data pipeline 来管理所有数据
如果将数据的一次变换抽象地看成对数据进行的一次操作(operation),在输入和输出的数据中应用一个黑盒/白盒变换,包括模型训练、数据采集、模型测都可以抽象成这样的单元(unit),那么可通过观察数据的流动特性去搭建 pipeline。
那么,一个理想的 pipeline 长什么样?

一个很好的参考是 Andrej Karpathy 在 CVPR 2021 Workshop 中介绍了 Tesla 的数据引擎(Data Engine),它负责实现 Autopilot 模型的迭代。这个 Data Engine 提供了业界标准的抽象,在各行各业都可以把数据闭环实现,以快速迭代。

格物钛数据平台也模块化地注入系统里去实现和 Tesla 一样的 Data Engine。格物钛可以帮助你完成 MLOps 通过
1) 数据搜索可视化发现高价值的数据:统一管理原始数据、元数据、语义数据以及来自预处理与评估服务等数据,支持扩展自定义搜索维度,实现数据的复杂场景搜索;
2)版本迭代和管理:统一的数据托管、权限控制与版本管理,实现不同角色对于数据的加工与使用相互不干扰又可以统一管理,组织的高效协同使得数据可以快速迭代
3)自动化:Action 功能通过工作流连接不同的数据处理任务和应用,统一存储与管理数据,使得数据可以在各个流程节点高效流转,实现快速搭建任意场景下的数据自动化处理流程,并且可以和用户的已有Pipeline集成。

格物钛智能科技是一家专注打造人工智能新型基础设施的初创企业,定位为面向机器学习的数据平台,帮助AI开发者解决日益增长的非结构化数据难题。借助格物钛非结构化数据平台和公开数据集社区,机器学习团队和个人可进行数据管理、查询、协同、可视化和版本控制等高效操作,降低高质量数据获取、存储和处理成本,加速AI开发和产品创新,释放海量非结构化数据的商业价值。