小白也能通俗易懂的联邦学习!
Datawhale干货
作者:知乎King James,伦敦国王大学
知乎 | https://www.zhihu.com/people/xu-xiu-jian-33
前言:联邦学习是近些年研究非常热门的领域,目前在工业界很多领域已经落地应用了。本篇文章同样面向产品运营等非专业技术人士,通俗易懂地讲解什么是联邦学习,主要解决什么问题,以及在工业界的实际落地案例。
01 联邦学习的发展历程
提到联邦(Federation),大家估计首先想到的就是英联邦或者美联邦,美国各个州组合在一起形成一个联邦。联邦学习( Federated Learning),字面直译也就是多方参与,共同学习。
1.1 最初的起源— 横向联邦学习
联邦学习最早是谷歌在2017.4月提出的,谷歌为此专门出了一个漫画来解释什么是联邦学习。(链接:https://zhuanlan.zhihu.com/p/101644082)
谷歌最开始提出联邦学习时是为了解决C端用户终端设备上模型训练的问题。C端用户手机上的智能软件提供服务时背后都得依靠模型,而模型的训练学习全部要基于用户的数据。比如手机上的输入法,基于不同人的打字拼音习惯,输入法会不停更新会慢慢和每个人的打字习惯进行匹配,用户会觉得输入法越来越智能;
那么过去这些手机输入法是如何进行模型训练的?
过去的做法: 将用户每天产生的行为数据全部上传至云端服务器,部署在服务器上的模型基于上传的数据进行训练,然后更新模型,最终实际应用时本地需要请求云端服务。大致流程如下图:

上述这种模型训练的方式,我们也叫做“集中式模型训练”,这种方式有两个弊端:
无法保证用户的数据隐私:服务商将用户的数据全部采集到了服务器上进行统一管理。这种方式在监管对个人数据隐私管控越来越严的情况下,会越来越受限;
实时性难以保证:模型在应用时需要通过网络请求云端的模型,在网络延迟或者没有网络的情况下,模型没办法发挥它的作用;
为了解决上述的弊端,谷歌提出了一种新的解决方案,并将它命名为“Federated Learning”。总的来说就是:用户数据不出本地,所有模型的训练都是在设备本地进行。本地模型训练完毕后将得到的模型参数or下降梯度,经过加密上传至云端,云端模型接收到所有上传的加密参数or梯度后,结合所有的参数值进行统一的聚合,比如通过加权平均得到新的模型参数or下降梯度,然后将新的结果再重新下发到本地,本地更新得到一个全新的模型;
这种方式我们又叫作“分布式模型训练“,大致的做法如下图:
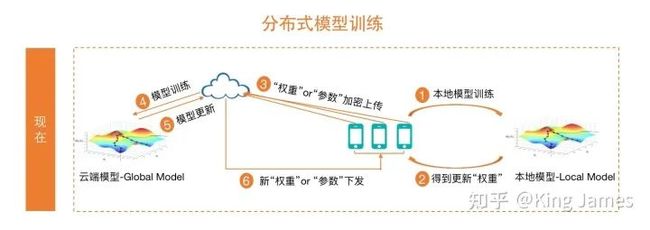
上述这种模型训练的方式有一个基本的要求:
本地模型-Local Model和云端模型- Global Model的特征必须一致:因为我们是汇总了无数本地模型的参数,基于这些参数对云端模型进行更新。如果这些模型的特征不一致,那么参数之间也没有任何参考意义。比如一个预测身高的模型,本地模型用“性别+年龄”特征,云端模型用“体重+肤色”特征,本地模型训练得到的模型参数上传到云端,云端根本毫无参考价值。
所以上述这种联邦学习我们又叫作 “横向联邦学习” ,模型之间使用的特征一致,只是使用的样本数据不一样。比如说下图本地模型使用的用户特征都是一样的,但是每个本地模型只能使用本地这一个用户的数据,无法使用其他用户的数据进行训练。
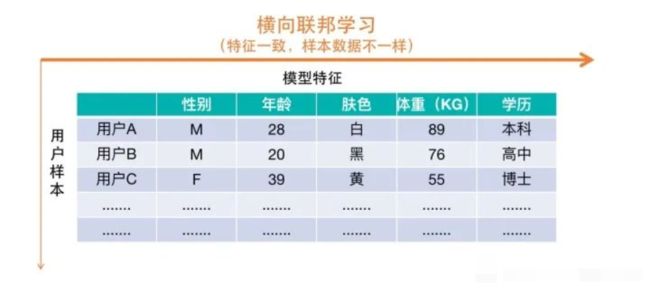
关于模型特征和模型参数不了解的读者可以阅读我这篇:https://zhuanlan.zhihu.com/p/110166255
谷歌这种“分布式模型训练”的新模式一方面保护了用户隐私,用户数据不离开本地;另一方面训练好的云端模型又下放到本地进行应用,这样即使没有网络也可以使用。读者可能还会对上述的联邦学习方案存在以下几个疑惑:
本地模型如何训练更新? 很多时候我们的手机都处于闲置的状态,这个时候本地模型就可以开始训练和上传加密参数;就像人体一样,睡眠的时候长高和做梦来更新大脑的认知系统;
模型部署本地会不会占据太多资源? 很多时候我们在云端服务器的模型都是几个G,下放本地会不会很占资源。这种模型都是需要经过压缩和部分的特征删减,确实特别大的模型无法下放本地;
上传的数据可以是模型的特征参数或模型训练的下降梯度嘛? 这二者均可,本身模型上的特征参数也是通过梯度下降法计算出来的,所以给下降梯度也是可以得到最终模型的特征参数。(对于梯度下降法不太了解的读者可以阅读:https://zhuanlan.zhihu.com/p/335191534)
上传的数据为什么还要加密?加密的数据又如何使用? 如果这些数据不进行加密的话,有可能通过这些数据进行反推导,将原始数据推导出来,当然这个难度也很大,但为了保险起见还是将所有的数据都进行加密上传。云端得到的是一个加密数据包,基于加密状态下的数据包云端模型即开始更新计算,这里面有大量密码学的知识在此不详细展开,是一种“同态加密”的算法。整个计算过程中云端模型均不知道加密数据包里面的具体内容。
1.2 B端的延伸—纵向联邦学习
联邦学习最开始被谷歌提出时是为了解决C端用户上传数据隐私问题。但是在实际工业界的问题是B端企业之间的数据孤岛问题。比如京东和腾讯之间的合作。京东和腾讯之间的用户肯定有绝大一部分是重叠的,京东有这部分用户的电商数据,腾讯有这部分用户的社交数据。如果二者将彼此之间的数据共享,那么彼此各项模型上的效果都会有大幅提升,但是实际开展时二者肯定不会共享彼此之间的数据。那么我们如何让双方在不交换源数据的前提下,彼此提升各自模型的效果了?
谷歌的联邦学习方案是“横向” 的,就像我们Part1.1里面说的,本地模型和云端模型用的特征都是一样的,模型的目标也是一样的。但是B端企业之间的模型目标不一样,特征也不一样,就像京东和腾讯,二者的用户存在重叠,但是场景不同,采集到的用户特征也存在一定差异。这种情况下的联邦学习方案我们叫做 “纵向”。
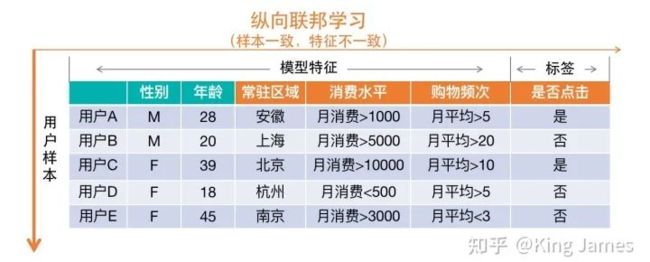
比如京东&腾讯的用户有ABCDE五个用户是重叠的,腾讯有用户的“性别”&“年龄”数据,京东有“常住区域”、“消费水平”&“购物频次”的数据,二者结合起来可以使用样本数据的所有特征建立一个效果更优的模型。纵向联邦学习的研究是由香港科技大学计算机科学与工程学系主任,第一位华人国际人工智能协会(AAAI)院士&AAAI执行委员会委员-杨强教授牵头发起的。
杨强教授的整体纵向联邦学习架构分为以下几个大的部分。
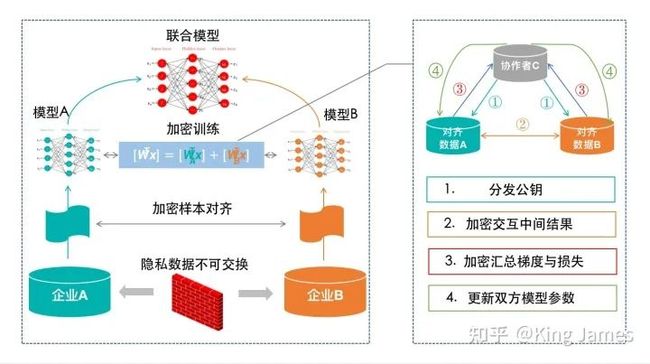
上图是杨强教授纵向联邦学习里面的架构,大家可以在众多联邦学习的文章中看到,整体还是比较抽象,我们以一个具体的案例来进行讲解。还是拿京东&腾讯合作的这个案例。
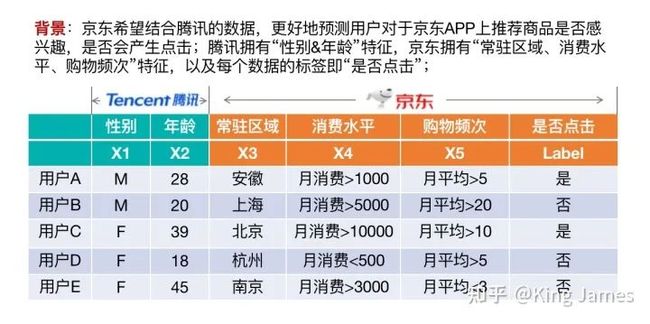
第一步:样本对齐; 腾讯和京东肯定都不会愿意暴露自己的原始数据。所以二者要在一起联合建模,首先需要对齐二者重叠的样本数据;在不暴露原始数据的前提下,双方如何对齐重叠的样本数据了,其实就是对齐哪些用户是共有的。这里同样需要应用到一种基于加密的用户ID对齐技术;
第二步:标签统一; 样本对齐以后,因为这个场景下我们是结合腾讯的数据来训练京东的模型,所以整个训练过程中数据的标签即“是否点击”Label由京东侧管控。
第三步:加密训练; 最终要构建的联合模型是拥有X1-X5所有特征的,但是X1-X2特征数据在腾讯侧,X3-X5特征数据在京东侧,同时Label在京东侧。所以在模型最开始训练时,两边模型各自使用自己有的特征和数据,初始化自己的参数w,然后开始计算。整个训练我们需要引入一个第三方也就是“协作者C”,这里的“协作者C”,并不是说要引入一家新的公司来参与到训练中,一个中间可以处理数据的地方即可。“协作者C”最开始需要下发一个公钥给到腾讯和京东,腾讯计算出来的中间结果经过公钥加密发给京东,京东也是如此。然后彼此再计算各自的下降梯度,再进行加密上传给协作者C,这中间一般京东&腾讯都会加一些随机数防止C直接获取梯度信息,协作者C进行解密后汇总双方结果得到一个最终的梯度值然后再回传给京东&腾讯,二者收到后减去最开始加上的随机数得到真实最终的梯度值,再更新模型的参数;

第四步:训练结束,联合模型更新; 步骤三重复循环,直到最终模型收敛训练完毕,最终京东&腾讯侧的模型参数都更新完毕,二者结合在一起就是一个联合模型。后面京东侧就使用该联合模型来进行线上应用。后续有用户来访问京东APP,如果该用户在二者重叠的样本中就访问联合模型来从京东&腾讯两侧获取加密数据,最终给出预测结果。
1.3 进一步延伸—联邦迁移学习
联邦迁移学习其实就是将联邦学习的思想和迁移学习的思想结合在了一起。横向联邦学习是特征一样,样本数据不一样。纵向联邦学习是样本有重叠,但是特征不一样。实际工业界还会有一些情况就是特征不一样,样本数据还没有重叠,这种情况下我们能不能联合建模?传统的方式其实就是迁移学习了,将这些数据进行升维或者降维,在子空间中可能会存在特征重叠或者用户重叠。子空间中的交互就可以进行迁移学习。那如何在迁移学习过程中保护各方的数据隐私,这时候引入联邦学习的思想即可。关于迁移学习后续会专门写一篇文章进行讲解,欢迎大家持续关注。
02 联邦学习概述
上面介绍了联邦学习的发展起源和各种分类,下面我们正式对于联邦学习进行一下定义。
2.1 联邦学习的定义
我们采用微众银行发布的《联邦学习白皮书》里面的定义:

2.2 联邦学习的特征
通过我们总结一下联邦学习的主要特征
多方协作: 有两个或以上的联邦学习参与方协作构建一个共享的机器学习模型。每一个参与方都拥有若干能够用来训练模型的训练数据。
各方平等: 联邦学习的参与方各方之间都是平等的,并不存在高低贵贱;
数据隐私保护: 在联邦学习模型的训练过程中,每一个参与方拥有的数据都不会离开该参与方,即数据不离开数据拥有者。
数据加密: 联邦学习模型相关的信息能够以加密方式在各方之间进行传输和交换,并且需要保证任何一个参与方都不能推测出其他方的原始数据。
2.3 联邦学习涉及到的学科
联邦学习的框架中涉及到了各种各样的学科,需要各个方面一起进步进而推动联邦学习的发展;
基本的机器学习算法
分布式机器学习;
加密算法;
模型压缩;
数据通信;
经济学;
2.4 联邦学习的激励机制
如何更好地激励联邦学习中作出重要贡献的参与方?虽然参与的各方都是平等的,但是各方的贡献是完全不一样的。比如阿里和一些很小的互联网公司合作一起建立一个联邦学习模型,肯定阿里的用户数据更加丰富和更有价值,如何去激励这些在联邦学习生态中做出更多贡献的参与方,如何建立一种激励机制,这也是联邦学习未来重点研究的方向。
3 联邦学习落地案例
联邦学习目前在工业界落地最大的两个领域就是广告&金融风控;
3.1 广告领域
互联网企业中的RTB广告,基于用户的实时请求为用户推荐他感兴趣的商品,这里面的推荐模型就需要大量用到用户的特征数据。就像Part1.2中介绍的,很多互联网企业只拥有用户的一部分特征数据,如果可以接入更多其他互联网企业的数据或者是投放广告主关于用户的数据,那么将大幅提升广告推荐的效果,既能提升点击率也可以提升广告主的ROI;联邦学习的出现就很好的解决了这个问题;
3.2 金融风控领域
金融领域同样如此,很多用户在多家银行拥有信贷记录,甚至在一些互联网金融机构上拥有借贷记录。单个金融机构需要对该用户做出全面客观的资质评判就需要结合用户历史所有的金融记录才可以。但是各大金融机构之间除了央行统一管理的个人征信,其他数据之间彼此是不互通的,这些数据既是用户的个人隐私也是银行重要的资产。联邦学习的出现同样让各大金融机构之间可以联合建模,对于用户的资质进行全面客观的评价,降低贷款的违约率和资产的不良率。
关于更多案例可以详细阅读文章最后的引用《联邦学习白皮书》;
4.横向联邦学习和边缘计算的区别
有些小伙伴可能会把横向联邦学习和边缘计算混淆,尤其是看了谷歌的这个漫画以后,觉得横向联邦学习和边缘计算有点像。横向联邦学习的出现是为了解决数据隐私的问题,将一些敏感数据在不离开数据原有方的基础上,让模型在本地完成训练后,然后上传加密的参数。而边缘计算的本意是将计算能力部署在设备上,设备请求实时响应,减少云计算中的网络延迟,这其中确实数据本身也不离开本地也保护了数据隐私。虽然二者有些交集但是出发点完全不一样。横向联邦学习是为了保护用户数据隐私,而边缘计算是为了确保服务可以及时响应降低减少云计算中的网络延迟。
最后感谢大家对于原创的支持,希望大家一键三连~
参考文献:
联邦学习诞生1000天的真实现状:https://www.leiphone.com/category/DataSecurity%20/rfPSGIjbS38DqTsm.html
关于联邦学习建模过程中算法交互内容的研究:https://youwuqiong.top/325471.html
纵向联邦学习简介及实现:https://segmentfault.com/a/1190000024464891
联邦学习白皮书-微众银行.pdf:https://pan.baidu.com/link/zhihu/7BhFzRuVhrijStITJTSTJt0CVDNOd1QwdFVn==
相关推荐:通俗讲解深度学习和神经网络!

整理不易,点赞三连↓