数据库并发控制、锁的简单理解
数据库并发控制、锁的简单理解
- 并发控制
-
- 并发优点
- 三大并发问题
- 结果可串行化
- 锁
-
- 锁简介
- 封锁协议解决三大并发问题
- 两段锁协议
- 防——死锁预防
- 治——死锁检测
- 并发控制、锁小结
并发控制
并发优点
为什么要并发,或者说并发有什么好处?
1、并发可以改善CPU等资源的资源利用率,提高系统效率。(这里类比操作系统,有些进程在等待IO的时候,可以把CPU让出来给别的进程用)
2、不同事物可能访问数据库的不同内容,这样可以提高数据库的利用率。(数据库里面那么多表,一个事物也就访问几个或者十几个,不并发太浪费了些)
三大并发问题
刚刚说了并发的好处,在提到第二个好处的时候,对于“访问数据库不同的内容”,如果两个事物访问数据库的内容有交叉怎么办?以下图为例:
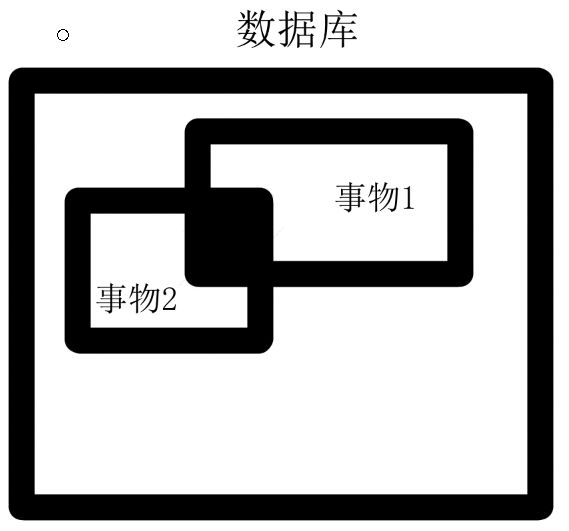
因此在并发过程中会遇到并发冲突的问题,只有解决好了这些问题,并发才能较为顺利的完成。
- 1、
丢失修改——写-写冲突 - 2、
读脏数据——写-读冲突 - 3、
不可重复读——读-写冲突
接下来分析一下这三个并发问题:
- 1.丢失修改。也就是说:其中一个事物对数据库的修改会被另一个并发事务覆盖,从而导致这个事务所作的修改被覆盖了。举个例子:
| 事务T1 | 事务T2 |
|---|---|
| Read(x) | … |
| … | Read(x) |
| x = x+2 | … |
| … | x = 5*x |
| write(x) | … |
| … | write(x) |
假设x的初值为6,事务T1修改完x之后,x的值为8,之后被写回到数据库中。但是刚写回数据库,就被事务T2计算的x结果30覆盖了,就好像T1这个事务啥都没干一样。
- 2、读脏数据。所谓读脏数据,就是读取正在更新的数据。因为事务在进行一半的时候,很有可能因为故障或者因为其他原因要进行回退的,如果另一个事务T2读了事务T1正在更新的数据,就会因为T1的回退而产生多米诺效应,也要跟着回退。举个例子:
| 事务T1 | 事务T2 | 事务T3 |
|---|---|---|
| … | … | … |
| write(x) | … | … |
| … | read(x) | … |
| … | y = x+1 | … |
| … | write(y) | … |
| … | … | read(y) |
| … | … | z = y+2 |
| … | … | write(y) |
| 故障 -> RollBack | … | … |
当事务T1出现故障需要滚回的时候,事务T2要受到事务T1的影响滚回,同时事务T3也要受到事务T2的影响滚回,整个恢复过程就会出现多米诺现象。
- 3、不可重复读。就是事务在工作过程中,在前面读取的内容和在后面读取的内容不相同。举个例子:
| 事务T1 | 事务T2 |
|---|---|
| Read(x) | … |
| temp = x +3 | write(x) |
| Read(x) | … |
| x = x +1 | … |
| write(x) | … |
上面这个例子中,事务T1在前面读取了x的内容用于计算,后面又想修改x的内容于是又读了一次x,结果后面读的x和前面读的x内容不一样了,那数据库的可信度就受到了质疑。
结果可串行化
正是因为上述的问题会给事务并发带来严重的不良影响,所以我们肯定想尽可能的避免出现上面的问题。但避免之前,我们要知道我们的事务并发会不会出现上述的问题,即要先判断出来有没有出现上述问题,之后才能进行进一步的处理。
这个判断的方法就是 结果可串行化。它是判断并发运行事务对数据库产生结果是否正确的准则。
那么什么是结果可串行化呢?在了解这个概念之前,需要了解另一个概念——并发的特点。
并发有一个特点:交给计算机并发执行的内容,执行结果与它们的执行顺序无关。什么意思呢?举个例子
现在有三个程序A、B、C,A是对 学生表 写东西,B是读 玩具表 中的内容,C是从 西瓜表 中读取西瓜信息。那么这三个程序谁先执行谁后执行那都无所谓吧,它们的结果都是一样的。
前面提到的下面这个过程:
| 事务T1 | 事务T2 |
|---|---|
| Read(x) | … |
| … | Read(x) |
| x = x+2 | … |
| … | x = 5*x |
| write(x) | … |
| … | write(x) |
事务T1和T2执行先后顺序不同,它的结果也是不一样的。即(假设x初始为6)
T1->T2 x结果是 5*8 = 40
T2->T1 x结果是 30+2 = 32
那么这两个事务就不能丢给计算机并发处理。
OK在了解完上述并发的特点之后,我们就可以提出结果可串行化的概念了。
结果可串行化:如果n个事务并发的结果是这n个事务串行结果中的一种,那么这n个事务就是结果可串行化的。举个例子:
现在有T1、T2、T3三个事务,它们的串行结果就是它们的排列组合的结果,结果有3!种 = 6种。下面列出它们排列组合的结果:
1、T1->T2->T3
2、T1->T3->T2
3、T2->T1->T3
4、T2->T3->T1
5、T3->T1->T2
6、T3->T2->T1
假设把这三个事务拿去并发,最后结果就是5的结果(这6种中的一种),OK那这三个事务就是结果可串行化的。
锁
OK在上面的内容中我们已经能够判断出事务并发会不会出问题了,那下面我们就用锁解决那些会出问题的并发事务。
锁简介
上锁指的是对资源的一种控制方式。锁大致分为三种锁:共享锁S,排他锁X,更新锁U。
其中共享锁S和排他锁X是基本的封锁类型。共享锁又称读锁,排他锁又称写锁。U锁在读之后写之前可以当作共享锁,在准备写的时候升级成排他锁。这样在写之前其他想读的事物也可以读,推迟排他的时间。
用行表示一个数据对象上已经拥有的锁,用列表示某个事务要新申请的锁,表格里的内容表示能否申请成功,做出下面的相容矩阵
| \ | 没有锁 | S锁 | U锁 | X锁 |
|---|---|---|---|---|
| S锁 | Y | Y | Y | N |
| U锁 | Y | Y | N | N |
| X锁 | Y | N | N | N |
这里可以理一下这张表的逻辑,结合后面深入分析之后再过来看这张表会有一个更清晰的认识。
用好锁,可以使得资源可以被很好的分配而不产生冲突。但是锁如果使用不当则会出现以下两种情况:
- 活锁
- 死锁
活锁,类似于操作系统中进程的“饥饿”现象。一个事务等待别的事物释放锁的时间过长,甚至出现永远等待的情况。举个例子:
| 事件 | 事件 |
|---|---|
| T1对资源x申请S锁 | … |
| T2对资源x申请S锁 | T对资源x申请X锁 |
| T1对资源x释放S锁 | T等待 |
| T3对资源x申请S锁 | T等待 |
| T2对资源x释放S锁 | T等待 |
| T4对资源x申请S锁 | T等待 |
| T5对资源x申请S锁 | T等待 |
| T3对资源x释放S锁 | T等待 |
| … | T等待 |
这里发现明明T申请锁的时间在很前面,但是它就是用不到锁,等待时间过长。(确实很气)
死锁,就是事物在等待资源的过程中形成了等待环路。死锁如果不加以干涉,事物就永远无法进行下去。举个例子:
| 事务Ta | 事务Tb |
|---|---|
| 对R1资源申请X锁 | 对R2资源申请X锁 |
| … | … |
| … | 对R1资源申请X锁 |
| 对R2资源申请X锁 | 事务Tb等待Ta锁释放 |
| 事务Ta等待Tb锁释放 | 事务Tb等待Ta锁释放 |
这样双方互相等待形成死循环。
封锁协议解决三大并发问题
封锁协议是针对共享锁S和排他锁X提出的解决三大并发问题的方法。
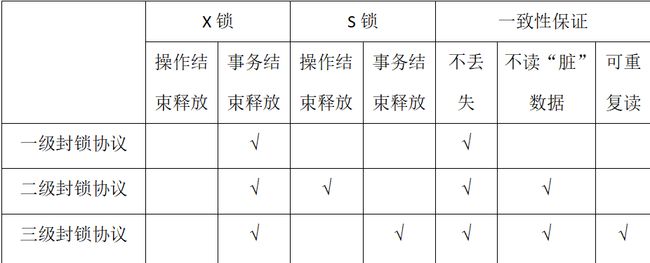
一共有三个级别的封锁:
一级封锁协议:事物T在修改数据R之前必须先对其加X锁,直到事物结束才能释放。二级封锁协议:在一级基础上增加事物T在读数据R之前必须对其加S锁,读完后可立刻释放S锁。三级封锁协议:在一级基础上增加事物T在读数据R之前必须对其加S锁,直到事物结束才释放。
给个表加以理解:
两段锁协议
为了保证并发的正确性,数据库管理系统通过两段锁协议的方法实现并发调度的可串行性,即 若并发的所有事务均遵循两段锁协议,那么对这些事务的任何并发调度策略都是可串行化的。(用反证法可以证明)
那么两段锁协议的内容又是什么呢?所谓两段锁协议是指所有事物必须分为两个阶段对数据项进行加锁和解锁。
扩展阶段:在对任何数据进行读、写操作之前,首先要申请并获得对该数据的封锁。收缩阶段:在释放一个封锁之后,事物不再申请和获得任何其他封锁。
遵循两段锁协议有没有可能发生死锁呢?这里要和后面的一次封锁法做区分,两段锁协议是可能发生死锁的,比如下例:
| 事务T1 | 事务T2 |
|---|---|
| 对B申请S锁 | … |
| … | 对A申请S锁 |
| … | … |
| 对A申请X锁 | … |
| 等待事务T2释放 | 对A申请X锁 |
| 等待事务T2释放 | 等待事务T1释放 |
防——死锁预防
防的思想主要在于:破坏死锁产生的必要条件,比如不让死锁形成环。
防的方法主要有以下三种方法:
- 1、一次封锁法。
- 2、顺序封锁法。
- 3、事务重试法(Transaction Retry)。
其中前两种方法在操作系统中也提到过,但是不适合现代数据库,第三种方法在实际数据库中有使用。下面对这三种方法进行如下分析:
1.一次封锁法:在事务的最开始就获得所有的锁,不然事务不继续运行。即对所有要用到的数据在最开始就进行加锁。这样做扩大封锁的范围降低了系统的并发度;而且事先很难精确要加锁的数据(可能有的数据要用到别的数据),因此要进一步扩大封锁范围,也要降低系统并发性。
2.顺序封锁法:给资源排序,所有的事物都按这个顺序进行封锁。但是就拿表资源来说,一个数据库中有成千上万个表,对这么多表进行排序本身就会有开销,而且数据库更新、删除表的操作很频繁,因此这样的排序及其不稳定;而且事物的封锁请求也是随着事物的执行动态决定的,很难预知。所以不太可行。
3.事务重试法:给每个事物安排一个时间戳作为TID,之后通过比较事物的年龄决定哪个事物优先获得资源。核心思想为年龄大的事务先获得资源。事务重试法分为两种情况:等待死亡法和基伤等待法。
-
a)
等待死亡法:Ta -> Tb即Ta等待Tb只有当Ta的年龄比Tb大的时候才等待。如果Ta比Tb小,而且Ta要等待Tb,那么Ta就会把自己滚回然后sleep挂起,等待一段时间之后再以原来的时间戳再次运行。(这样这个年轻的事务到后面还是会变成元老,这样它就不用再把自己滚回了)通过这种方式只有 年老 -> 年轻 单方向的等待,就不会产生死锁。当然活锁也不会产生,因为那个刚开始年轻的事务的时间戳是不变的,当比它更老的事务完成以后,它就是最老的了。 -
b)
基伤等待法:Ta -> Tb即Ta等待Tb只有当Ta的年龄比Tb小的时候才等待。否则Ta会把Tb滚回(kill掉),之后Tb自己sleep挂起,然后Ta把资源抢过来。和等待死亡法核心思想一样。
治——死锁检测
治的思想主要在于:允许死锁发生,但是我要把死锁检测出来,同时经过处理把死锁断开。
治的方法主要有以下两种:
- 1.超时法。
- 2.等待图法。
超时法顾名思义就是设置一个timeout时限,如果一个事务的等待超过了规定时限就认为发现死锁。由于这个时限不好设置,一些小系统可以用,大系统一般用不了。
等待图法就是创建一个有向图G=
那环路是什么时候去检测呢? 出现新的边的时候 或者 周期性检查。
在检查出有环路之后如何解决死锁问题呢?——选择一个“牺牲者”,一般来说选择一个处理死锁代价最小的事务,将其撤销,释放该事务持有的所有的锁,使得其他事务运行下去,最后将被撤销的事务恢复。
并发控制、锁小结
1、对于并发控制来说,结果可串行化可以用来判断是否出现了并发的三大问题(可串行化证明一定可以并发,所以一定没有三大问题),并发的三大问题分别是:丢失修改、读脏数据和不可重复读。
2、锁:基本锁有两种,X锁和S锁。如果锁使用不当会出现死锁和活锁现象。了解三大封锁协议是如何解决三大并发问题的。
3、两段锁协议是结果可串行化的充分条件。
4、了解死锁预防的三种方法和死锁检测的两种方法。