运用R和Python进行简单的拉钩网数据分析
本次数据分析主要涉及到以下几个步骤:
1.Python爬虫进行数据采集,并存储到数据库中
2.通过Python和数据库连接,取出数据
3.数据字段的理解和初步观察
4.借助R对数据进行预处理,缺失值、异常值处理,数据分组等
5.使用R对数据可视化展示和结论
6.总结
import requests
import json
import time
import pymysql
import random
# 请求网页
def get_html(n):
print('开始请求第%d页信息' % n)
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false&isSchoolJob=0'
data = {'first':'false','pn':n,'kd':'数据分析师'}
proxy = ['1.196.135.109:38882','101.132.121.157:9000','118.212.137.135:31288','58.216.202.149:8118','122.114.31.177:808','114.215.95.188:3128']
headers = {'origin': "https://www.lagou.com",
'Host':'www.lagou.com',
'Accept-Encoding': "gzip, deflate, br",
'Accept-Language': "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8",
'Accept': "application/json, text/javascript, */*; q=0.01",
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=',
'Connection': "keep-alive"}
try:
res = requests.post(url,data=data,headers=headers,proxies={'https:':random.choice(proxy)})
res.encoding = 'utf-8'
except:
print('第%d页信息请求失败' % n)
pass
else:
html = res.json()
print('第%d页信息请求完毕' % n)
time.sleep(20)
return html
#采集信息
def get_message(html,n):
msg = html['content']['positionResult']['result']
print('开始采集第%d页信息' % n)
msg_all = []
for item in msg:
positionName = item['positionName']
companyName = item['companyFullName']
salary = item['salary']
workyear = item['workYear']
education = item['education']
jobNature = item['jobNature']
city = item['city']
createtime = item['createTime']
financeStage = item['financeStage']
industryField = item['industryField']
companySize = item['companySize']
positionAdvantage = item['positionAdvantage']
messaege = (positionName,companyName,salary,workyear,education,jobNature,city,createtime,financeStage,industryField,companySize,positionAdvantage)
msg_all.append(messaege)
print('第%d页信息采集完毕' % n)
return msg_all
# 存储信息
def save_msg(msg_all,n):
coon = pymysql.connect(host='localhost', user='root', passwd='123456', db='dy',charset='utf8')
cur=coon.cursor()
for item in msg_all:
sql = '''insert into `lagou`(`positionName`,`companyName`,`salary`,`workyear`,`education`,
# `jobNature`,`city`,`createtime`,`financeStage`,`industryField`,`companySize`,`positionAdvantage`) VALUES(%s,%s,%s,%s,%s,%s,%s,
# %s,%s,%s,%s,%s)'''
cur.execute(sql,item)
coon.commit()
print('第%d页信息存储完成' % n)
coon.close()
if __name__ == '__main__':
for i in range(1,31):
html_1 = get_html(i)
msg_all_1 = get_message(html_1,i)
save_msg(msg_all_1,i)
print('信息完成收集')将爬取的信息存储在MySQL数据库中,我们通过MySQL的导出功能,将数据库中的文件导为csv格式的文件。这样数据源就解决好了。
在开始数据分析之前,首先要明确几个目标:
1.上海地区数据分析师的薪资水平处于何种程度
2.企业对工作多少年的数据分析师需求较多
3.企业对数据分析师的受教育程度要求是怎样的
4.招聘数据分析师的企业规模是有怎样的分布规律的
5.薪资与工作年限的关系
6.企业提供的福利待遇怎样
数据处理:这里采用R和Python进行分析
步骤1:加载原始数据
这里提供一种快速导入操作,采用RStudio中的file中的import database进行导入操作
步骤2:观察数据,对数据进行预处理
View(lagou)数据集的各字段名称解释如下
index:编号
positionName:职位名称
companyName:公司名称
salary:薪资
workyear:工作年限
education:受教育程度
jobNature:工作性质(全职或者兼职)
city:工作地点(本例全为上海地区)
createtime:招聘发布时间
financeStage:公司性质
industryField:公司所处领域
companySize:公司规模
positionAdvantage:公司福利
数据缺失值、异常值、重复值的检查及清洗
> dim(lagou) #采集的数据量较少,因为拉钩只允许爬取30页内容[1] 450 13> sum(is.na(lagou)) #查看是否具有缺失数据
[1] 0> sum(duplicated(lagou)) #查看是否有重复数据
[1] 0> length(unique(lagou$salary)) #查看数据集各字段的的维度,发现薪资的维度比较多,79项,需要处理
[1] 79处理过程如下:
#由于薪资是以'10k-15k'这种形式存储的,我们对薪资剔除'k'后取中间值得到新的薪资字段
sal_1<-strsplit((lagou$salary),'-')
sal_min<-sapply(sal_1,'[',1)
sal_max<-sapply(sal_1,'[',2)
sal_min<-sub('[kK]','',sal_min)
sal_max<-sub('[kK]','',sal_max)
sal_min_1<-as.numeric(sal_min)
sal_max_1<-as.numeric(sal_max)
sal_mean<-(sal_max_1+sal_min_1)/2
lagou$salary<-sal_mean #至此已完成处理,可以进行分析了数据分析结果展示
1.上海地区数据分析师的薪资水平处于何种程度
> library(ggplot2)
> ggplot(data = lagou,aes(x=salary,y=..count..))+geom_histogram(fill='#BC8F8F',colour='#B8860B',bins = 15)
- 总的来说数据分析师的平均薪资比较好,薪资主要分布在5k-35k之间,其中又以10k-20k的居多
2.企业对工作多少年的数据分析师需求较多
> ggplot(data=lagou,aes(x=workyear,y=..count..))+geom_bar(fill='lightblue',width = 0.5)
- 以工作1-3年和3-5年的需求量最大,10年以上的招聘很少,可以理解为这是个年轻人居多的行业,这对于转型进入数据分析的人来说不是一个好的消息
- 转行需要更有充足的准备,且要不断寻找能够积累经验的项目来做。
3.企业对数据分析师的受教育程度要求是怎样的
> ggplot(data=lagou,aes(x=education,y=..count..))+geom_bar(width = 0.5)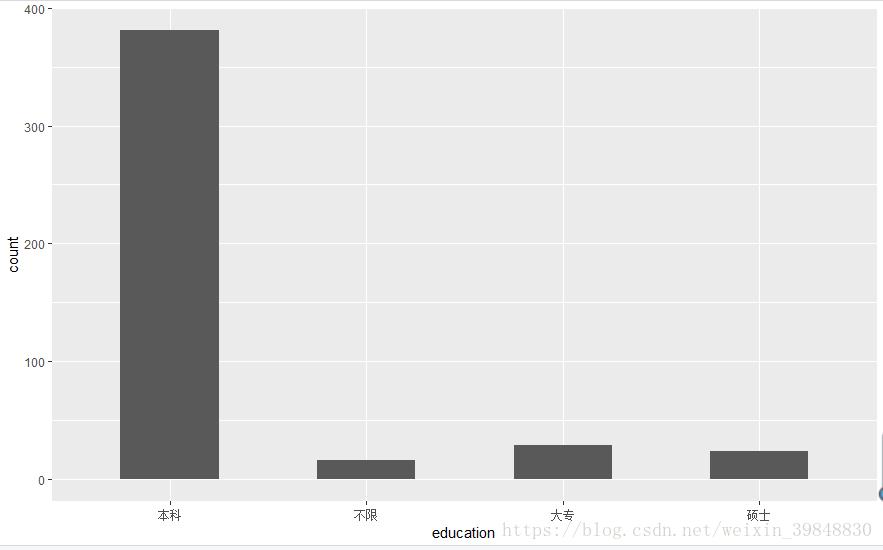
- 企业对于数据分析师的受教育程度以本科为主
- 可以单独对大专和硕士要求的招聘条件进行分析,了解学历不同,在招聘条件上是否更严格或更宽松
4.招聘数据分析师的企业规模是有怎样的分布规律的
> ggplot(data=lagou,aes(x=companySize,y=..count..,fill=workyear))+geom_bar(position = 'stack',alpha=0.9,width = 0.8,linetype=1,size=1)> ggplot(data=lagou,aes(x=companySize,y=salary))+geom_boxplot(fill=c('#BCD2EE','#BC8F8F','#BDBDBD','#C5C1AA','#B8860B','#BC8F8F'))
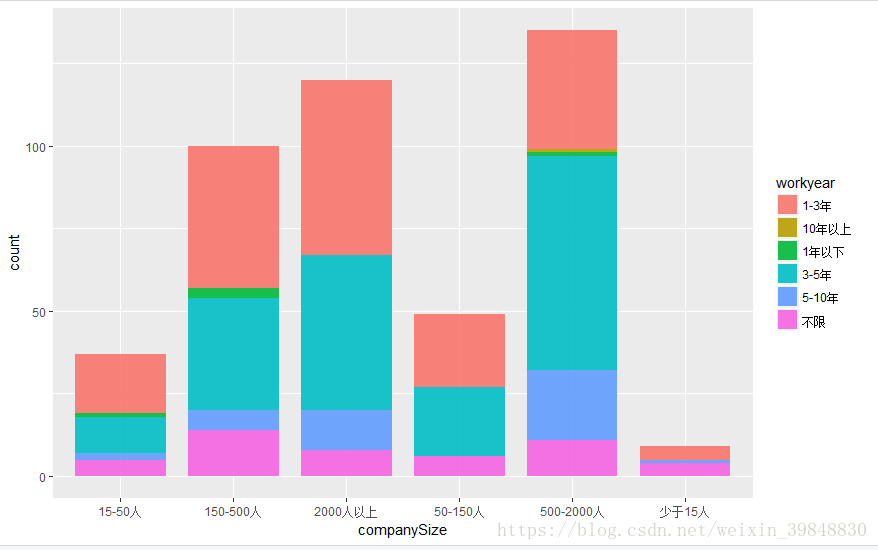
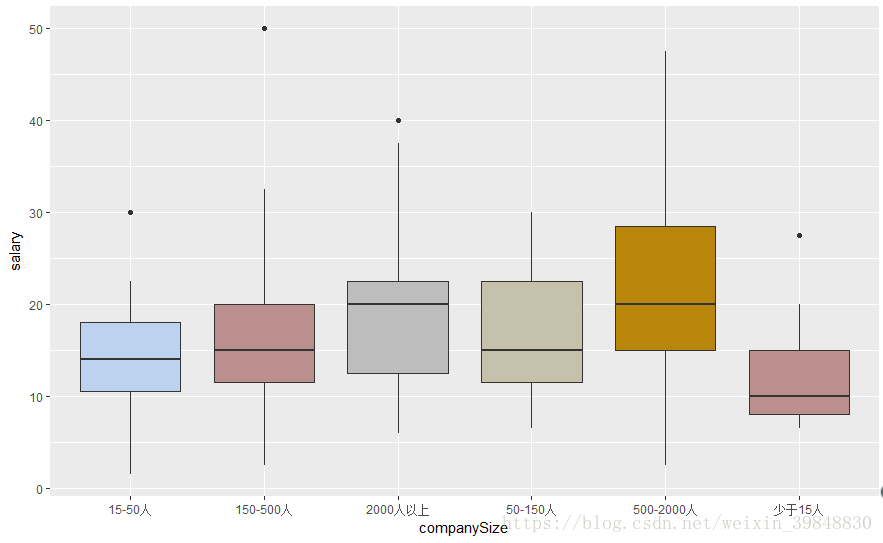
- 结果显示,人数规模越大的企业对数据分析师的需求更多,这也侧面证明了企业越大,数据越多
- 规模越大的企业,对于有更多年工作经验的数据分析需求占比越高
- 150人规模以下的企业需求量较少,但给出的薪资较高(甚至有异常的高薪),该类企业可能处于快速融资且高速的发展阶段,需要有丰富经验的数据分析专家来建设整个数据体系
- 对于转型的新人,尽可能往大企业走,越大规模的企业,整个体系越成熟,因此可以在150人以上的规模从上往下选择自己合适的企业才是比较科学的方式,且需求量巨大
5.薪资与工作年限的关系
> ggplot(data=lagou,aes(x=workyear,y=salary))+geom_boxplot(fill=c('#BCD2EE','#BC8F8F','#BDBDBD','#C5C1AA','#B8860B','#BC8F8F'))
- 可以很明显的看出,工作年限越久,薪资越高,这也符合主流的薪资提升标准
- 以5-10年的薪资幅度较大,3年之内的薪资变动幅度不大,要想拿高薪水,在行业中浸淫3年以上是必须的,俗话3年说一个坎,看来没毛病^_^
6.企业提供的福利待遇怎样
这里采用Python进行可视化展示
from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
from scipy.misc import imread
import pymysql
plt.rcParams['font.sans-serif']=['SimHei'] #处理中文乱码
plt.rcParams['axes.unicode_minus']=False #防止符号方块化
#连接数据库
coon=pymysql.connect(host='localhost',user='root',passwd='123456',db='dy',charset='utf8')
cursor=coon.cursor()
sql = 'select positionAdvantage from lagou'
cursor.execute(sql)
industry = cursor.fetchall()
industry_list=[item[0] for item in industry] #生成列表并提取其中的元素值
industry_text =' '.join(industry_list) #通过空格分割,产生字符串
coloring=imread('1.jpg') #定义背景图片
font='C:\Windows\Fonts\simkai.ttf' #指定当前字库
my_wordcloud=WordCloud(font_path=font,max_font_size=300,background_color='white',
mask=coloring).generate(industry_text)
image_colors=ImageColorGenerator(coloring) #从背景图片生成颜色值
plt.imshow(my_wordcloud.recolor(color_func=image_colors)) #生成词云图片(对内)
plt.axis('off') #关闭显示坐标轴
plt.show()
- 可以看出,公司在‘五险一金’、‘弹性工作’、‘发展空间大’、‘带薪年假’等国家硬性条件下福利待遇出现的频次最高
总结:
1.从总体需求来看,企业更加需要具备多年工作经验,且动手能力强,解决实际问题的分析人才,随着工作经验的增加,其对应的薪资也有可观的增长。
2.从企业规模看,150人以上规模的企业更加适合新人进去锻炼,一方面企业已经完成了基本的数据体系架构,且越大的企业数据量级越大,另一方面,企业需要逐步培养强大的数据分析团队来支撑业务的增长。
不足:
1.此次分析并没有以数据报告的形式来呈现,仅以个人角度来进行分析撰写,欢迎能与各位交流指正。
2.分析的数据量不足,且仅以上海地区为主,后期不仅需要对北上广深杭等地区数据进行爬取,综合对比分析,还需要放宽采集字段,添加企业要求的技能,工具、数据分析师所属方向(偏业务,还是偏建模等)
3.这次分析仅仅只是数据的一些可视化展示,并未涉及到建模分析领域