精度 vs 效率:模型越小,精度就一定越低吗?
导语:深度学习是否朝着正确的方向发展?

以下是我最近在伦敦 O’Reilly AI Conference 和 DroidCon 上的两次谈话的改编。
今年早些时候,NVIDIA 的研究人员发布了 MegatronLM。这是一个拥有 83 亿个参数(比 BERT 大 24 倍)的大型 transformer 模型,它在各种语言任务上都达到了最先进的性能。虽然这无疑是一项令人印象深刻的技术成就,但我不禁要问自己:深度学习是否朝着正确的方向发展?
单是这些参数在磁盘上的权重就超过了 33GB,训练最终的模型需要 512v100 GPU 连续运行 9.2 天。考虑到每张卡的能量需求,训练这一模型所用的能量量是美国平均年能源消耗量的 3 倍多。
我不想单独列出这个项目。有许多例子表明,大量的模型正在被训练,以便在各种基准上获得更高的精度。尽管 MegatronLM 比 BERT 大 24 倍,但它在语言建模方面只比 BERT 强 34%。作为演示新硬件性能的一次性实验,这里没有太大的危害。但从长远来看,这一趋势将导致一些问题。
首先,它阻碍了民主化。如果我们相信,在这个世界上,数以百万计的工程师将使用深度学习来改进每一个应用程序和设备,那么我们就不会拥有需要大量时间和金钱来训练的大型模型。
其次,它限制了规模。世界上每一个公共和私有云中可能只有不到 1 亿个处理器,但现在已经有 30 亿部手机、120 亿部物联网设备和 1500 亿个微控制器。从长远来看,正是这些小型、低功耗的设备最需要深度学习,大规模的模型根本不会是一个选择。

为了确保深度学习实现其承诺,我们需要重新对研究进行定位,不要追求最高的准确性和最先进的效率。我们需要关心的是,模型是否能够让最大数量的人使用,是否能够在大多数设备上用最少的资源尽可能快地迭代。
好消息是,我们正在努力使深度学习模型更小、更快、更高效。早期的回报令人难以置信,例如,Han 等人 2015 年的一篇论文得出了这样一个结果。
「在 ImageNet 数据集上,我们的方法将 AlexNet 所需的存储空间减少了 35 倍——从 240MB 减少到 6.9MB,而且不失准确性。我们的方法将 VGG-16 的大小从 552MB 减少到 11.3MB,减少了 49 倍,同样没有精度损失。」
为了达到这样的效果,我们必须考虑从模型选择、训练到部署的整个机器学习生命周期。在本文的其余部分,我们将深入到这些阶段,并研究如何创建更小、更快、更高效的模型。
模型选择
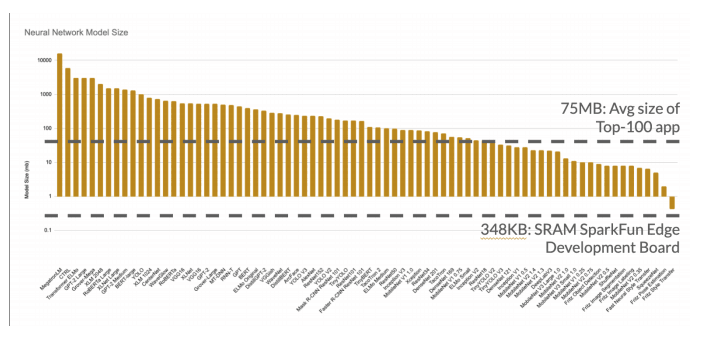
以更小、更高效的模式结束的最好方法是开始一个模型的建立。上图描绘了各种模型架构的大致大小(兆字节)。我已经覆盖了表示移动应用程序的典型大小(包括代码)以及嵌入式设备中可用的 SRAM 数量。
Y 轴上的对数刻度软化了视觉打击,但不幸的事实是,大多数模型架构对于除了数据中心的任何地方来说,数量级都太大了。
令人难以置信的是,右边较小的架构的性能并没有比左边的大架构差多少。像 VGG-16 这样的架构(300-500MB)的性能和 MobileNet(20MB)的差不多,尽管它的体积小了近 25 倍。
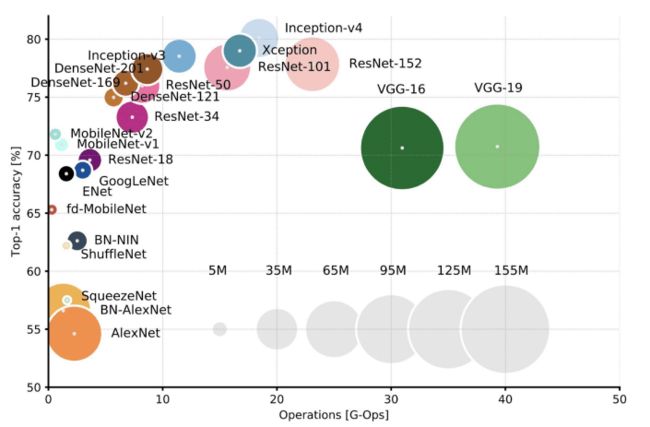
是什么让 MobileNet 和 SquezeNet 这样的小型架构如此高效?基于 Iandola 等人(SquezeNet)、Howard 等人(MobileNet3)和 Chen 等人(DeepLab V3)的实验,一些答案存在于模型的宏观和微观结构中。
宏体系结构指的是模型使用的层的类型,以及如何将它们排列成模块和块。要生成高效的宏架构,请执行以下操作:
-
通过降采样或使用空洞卷积保持激活图的大小
-
使用更多的通道,更少的层
-
在计算过程中使用跳接和剩余连接来提高精度,重复使用参数
-
用可分离的标准卷积替换
模型的微观结构与各个层相关。最佳做法包括:
-
使输入和输出块尽可能高效,因为它们通常占模型计算成本的 15-25%
-
减小卷积核的大小
-
添加一个宽度倍增器,用超参数 alpha 控制每次卷积的通道数
-
排列图层,以便可以融合参数(例如偏差和批量标准化)
模型训练
在选择了模型架构之后,要缩小它并使其在训练期间更有效,仍然有很多工作可以做。如果还不明显的话,大多数神经网络都是参数化的,许多经过训练的权重对整体精度影响很小,可以去除。Frankle 等人发现,在许多网络中,80-90% 的网络权值可以被移除,同时这些权值中的大多数精度也可以被移除,而精度损失很小。
寻找和移除这些参数的策略主要有三种:知识蒸馏、剪枝和量化。它们可以一起使用,也可以单独使用。
知识蒸馏
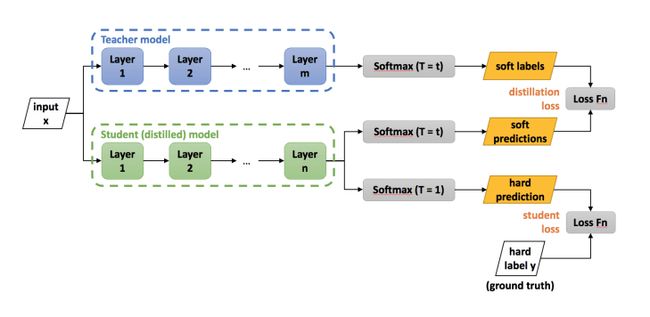
知识蒸馏采用较大的「教师」模型来训练较小的「学生」模型。这项技术最初由 Hinton 等人于 2015 年提出,其关键在于两个损失项:一个是学生模型的硬预测,另一个是基于学生在所有班级,产生相同分数分布的能力。
Polino 等人能够在 CIFAR10 上训练的 ResNet 模型的大小减少 46 倍,精度损失只有 10%;在 ImageNet 上,大小减少 2 倍,精度损失只有 2%。最近,Jiao 等人蒸馏 BERT 来制造 TinyBERT:小 7.5 倍,快 9.4 倍,并且精确度只降低了 3% 。有一些很好的开源库实现了蒸馏框架,包括 Distiller 和用于 transformer 的 Distil。
剪枝
缩小模型的第二种技术是剪枝。剪枝包括评估模型中权重的重要性,并删除那些对整体模型精度贡献最小的权重。剪枝可以在一个网络的多个尺度上进行,最小的模型是通过在单独的权重级别上剪枝来实现的,小量级的权重设置为零,当模型被压缩或以稀疏格式存储时,其存储效率非常高。
Han 等人使用这种方法将普通的计算机视觉体系结构缩小了 9~13 倍,精度变化可以忽略不计。不幸的是,缺少对快速稀疏矩阵操作的支持意味着权重级别的剪枝也不会提高运行速度。
要创建更小、更快的模型,需要在滤波器或层级别进行剪枝,例如,删除对总体预测精度贡献最小的卷积层的滤波器。在滤波器级别剪枝的模型并没有那么小,但通常速度更快。Li 等人使用该技术能够将 VGG 模型的大小和运行时间减少 34%,而不损失准确性。
最后,值得注意的是,对于是否最好从更大的模型开始,从零开始剪枝或训练更小的模型,Liu 等人的结果好坏参半。
量化
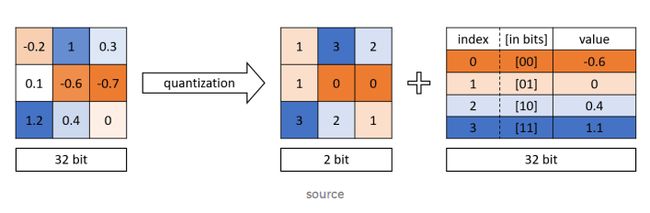
图源:https://medium.com/@kaustavtamuly/compressing-and-accelerating-high-dimensional-neural-networks-6b501983c0c8
模型经过训练后,需要为部署做好准备。这里也有一些技术可以对模型进行更多的优化。通常,模型的权重存储为 32 位浮点数,但对于大多数应用程序,这远比所需的精度高。我们可以通过量化这些权重来节省空间和时间,同时对精度产生最小的影响。
量化将每个浮点权重映射到一个固定精度的整数,该整数包含的 bit 数少于原始值。虽然有许多量化技术,但最重要的两个因素是最终模型的 bit 深度和训练期间或之后是否量化权重。
最后,量化权重和激活对于加快模型的运行是很重要的。激活函数是自然产生浮点数的数学运算,如果不修改这些函数来产生量化的输出,那么由于需要转换,模型甚至可能运行得更慢。
在一篇精彩的测评文中,Krishnamoorthi 测试了许多量化方案和配置,以提供一组最佳实践:
结果如下:
-
后训练通常可以应用到 8 位,模型减小 4 倍,模型精度损失小于 2%
-
训练感知量化,以最小的精度损失将位深度减少到 4 或 2 位(模型减小 8~16 倍)
-
量化权重和激活可以使 CPU 的速度提高 2-3 倍
部署
这些技术中的一个共同点是,它们生成了一个连续的模型,每个模型都有不同的形状、大小和精度。虽然这会产生一些管理和组织问题,但它很好地映射到了各种各样的硬件和软件条件的模型将面临的问题。
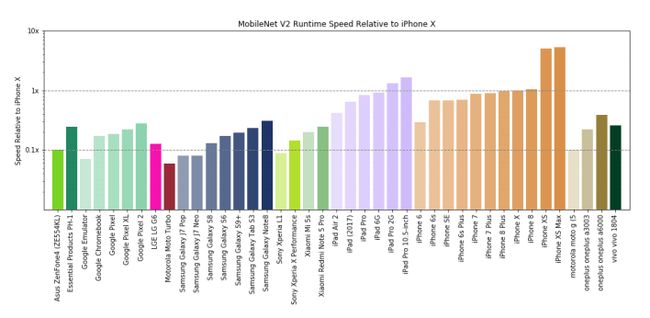
上图显示了 MobileNetV2 模型在各种智能手机上的运行速度,最低端和最高端设备之间可能存在 80 倍的速度差。为了给用户提供一致的体验,在正确的设备上放置正确的型号是很重要的,这意味着训练多个模型,并根据可用资源将它们部署到不同的设备上。
通常,最佳的设备性能是通过以下方式实现的:
-
使用本机格式和框架(例如 iOS 上的 Core ML 和 Android 上的 TFLite)
-
利用任何可用的加速器,如 GPU 或 DSP
-
监视设备的性能,确定模型瓶颈,并迭代特定硬件的体系结构
当然,监视和管理所有模型的不同版本并不总是那么容易。
总结
通过应用这些技术,可以将大多数模型缩小并加速至少一个数量级。下面引用到目前为止讨论过的几篇论文:
-
「TinyBERT 在经验上是有效的,并且在 GLUE 数据集中取得了与 BERT 相当的结果,同时比 BERT 小了 7.5 倍,推理速度快了 9.4 倍。」—Jiao 等人
-
「我们的方法将 VGG-16 的大小从 552MB 减少到 11.3MB,减少了 49 倍,没有精度损失。」—Han 等人
-
「模型本身占用的闪存空间不到 20KB……而且它只需要 30KB 的 RAM 就可以运行。」—Peter Warden 在 TensorFlow Dev Summit 2019 上如是说
为了证明普通人也可以完成这件事情,我冒昧地创建了一个小的 17KB 风格的传输模型,它只包含 11686 个参数,但仍然产生了与 160 万个参数的模型一样好的结果。
左:原始图像;中:我们 17KB 的小模型的样式化图像;右:更大的 7MB 模型的样式化图像
我一直认为这样的结果很容易实现,但并不是每一篇论文都采用了标准的过程。如果我们不改变我们的实践,我担心我们会浪费时间、金钱和资源,同时无法将深度学习用到可能从中受益的应用程序和设备中。
不过,好消息是,大模型的边际效益似乎正在下降,而且由于这里概述的这些技术,我们也可以对其大小和速度进行优化,而不会牺牲太多的准确性。
额外资源:
-
Distiller — A library for optimizing PyTorch models
-
TensorFlow Model Optimization Toolkit
-
Keras Tuner — Hyperparameter optimization for Keras
-
TinyML — Group dedicated to embedded ML

via:https://heartbeat.fritz.ai/deep-learning-has-a-size-problem-ea601304cd8