ELK日志集成(filebeat+kafka+logstash+elasticsearch+kibana)
1、日志文件准备
首先日志集成json格式,这个在我搭建的项目案例中的logback-spring.xml中有过配置如何将日志转成json格式,具体参考gitee项目的logback-spring.xml配置,也可参考之前写过的一篇文章。
2、准备安装包及环境
需要kafka集群,Elasticsearch集群, logstash,filebeat,Kibana
Elasticsearch集群参考我之前的https://blog.csdn.net/xibei19921101/article/details/112527812这篇文章
Kafka集群参考https://blog.csdn.net/xibei19921101/article/details/119419868这篇文章
Elasticsearch、Kibana、filebeat、logstash下载都可以在 elastic 的官方网站获取自己想要的版本

##下载filebeat,6.8.7的版本
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.8.7-linux-x86_64.tar.gz
##下载kibana,6.8.7的版本
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.8.7-linux-x86_64.tar.gz
##下载logstash,6.8.7的版本
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.8.7.tar.gz3、安装filebeat
在应用启动的机器上安装filebeat,将日志推送到kafka集群中
安装步骤:解压缩下载的压缩包,修改filebeat.yml文件,创建启动脚本restart.sh
restart.sh
#!/bin/bash
pids=`ps -ef| grep filebeat |grep -v grep |awk '{print $2}'`
if [[ -z $pids ]]; then
echo 'process of filebeat not exist,begin to run'
nohup ./filebeat -e -c filebeat.yml >filebeat.log 2>&1 &
##可以防止日志爆盘,将所有标准输出及标准错误输出到/dev/null空设备,即没有任何输出信息。
#nohup ./filebeat -e -c filebeat.yml >/dev/null &
else
echo 'filebeat exist,will be killed and restart'
kill -9 $pids
echo 'filebeat has been killed...'
echo 'filebeat restart now...'
nohup ./filebeat -e -c filebeat.yml >filebeat.log 2>&1 &
fifilebeat.yml:
filebeat:
prospectors:
-
paths:
- /home/scene/bin/logs/springboot_demo/json.log
#filebeat可推送多个日志文件,可以继续换行添加
#- /home/scene/bin/*/json.log #可以使用通配符指定扫描一系列日志
input_type: log
exclude_files: ['health.log$']
scan_freqency: "10s"
backoff: "1s"
json.message_key: log
json.keys_under_root: true
json.overwrite_keys: true
#fields: {project: "myproject", instance-id: "123452341435"} #可在最终日志输出字段中添加额外的字段
#fields_under_root: true #若此字段设置为true,则自定义字段将存储为输出文档中的顶级字段,而不是在fields字段下分组,若自定义字段与其他字段名冲突,则自定义字段将覆盖其他字段
#include_lines: ['ERROR','WARN']
output:
kafka:
enable: true
hosts: ["192.168.236.131:9092","192.168.236.130:9092","192.168.236.129:9092"] #服务集群
topic: "elklog"
partition.hash:
reachable_only: true
compression: gzip
max_message_bytes: 1000000
required_acks: 1在kafka集群中创建filebeat.yml配置的elklog主题
#在kafka的bin目录下
./kafka-topics.sh --create --zookeeper 192.168.236.131:2181,192.168.236.130:2181,192.168.236.129:2181 --replication-factor 1 --partitions 3 --topic elklog启动filebeat,以及之前的kafka集群,即可看到elklog主题有消息推送

4、安装kibana
解压下载的压缩包,进入config目录
修改kibana.yml文件配置,直接配置成如下即可,对应的ip地址改下
# 具体kibana.yml的配置参数说明参考https://www.cnblogs.com/sanduzxcvbnm/p/12837155.html
server.port: 5601
server.host: "192.168.236.131"
# 用来处理所有查询的Elasticsearch实例的URL
elasticsearch.hosts: ["http://192.168.236.131:9200"]
# 用来控制证书的认证,可选的值为full,none,certificate。此处由于没有证书,所以设置为null,否则启动会提示错误.
elasticsearch.ssl.verificationMode: none
# 搜索数据请求超时时间
elasticsearch.requestTimeout: 30000
# 修改 i18n.locale: “zh-CN” 这样 kibana 界面会显示为中文
i18n.locale: "zk-CN"启动kibana方式,进入 kibana 的bin目录, 执行 ./kibana (注意:kibana 也不能用 root 用户启动)
打开浏览器, 输入htt//ip:5601地址, 若长时间没有响应,试着开放端口或者关闭防火墙
若要关闭kibana,找到kibana启动的pid,有如下几种方法
sudo ps -ef |grep node
sudo fuser -n tcp 5601
sudo netstat -ntulp|grep 5601 ##或者sudo netstat -anltp|grep 5601
##然后kill -9 进程号 即可关闭
5、安装LogStash
目的是将上述filebeat推送到kafka的消息记录消费至elasticsearch中,便于接下来kibana搜索elasticsearch
解压缩下载的logstash文件,进入到config目录下修改jvm.options的参数配置,实际情形的物理机应该内存够,我的是虚拟机,配置不够,需要修改;还是在config目录下参考logstash-sample.conf编写配置文件logstash.conf,然后在启动脚本中指定所使用的的配置文件
logstash.conf
注意bootstrap_servers必须是字符串,不能用数组,我启动的时候用数组报错了,然后根据日志改成字符串再启动就成功了
input {
kafka {
bootstrap_servers => "192.168.236.131:9092,192.168.236.130:9092,192.168.236.129:9092"
topics => ["elklog"]
auto_offset_reset => "earliest" #偏移量
codec => json {
charset => "UTF-8"
}
#消费线程数,不大于分区个数consumer_threads => 2
}
# 如果有其他数据源,直接在下面追加
}
##过滤,可要可不要
filter {
# 将message转为json格式
#if [type] == "log" {
# json {
# source => "message"
# target => "message"
# }
#}
}
output {
# 处理后的日志落到本地文件
#file {
# path => "/config-dir/test.log"
# flush_interval => 0
#}
# 处理后的日志入es
elasticsearch {
hosts => ["192.168.236.131:9200","192.168.236.130:9200","192.168.236.129:9200"]
index => "elklog-%{+YYYYMMdd}"
}
}后台启动logstash的脚本,注意文件路径
#!/bin/bash
pids=`ps -ef| grep logstash |grep -v grep |awk '{print $2}'`
if [[ -z $pids ]]; then
echo 'process of logstash not exist,begin to run'
nohup ./logstash/bin/logstash -f /home/elker/logstash/config/logstash.conf > /home/elker/nohup.log 2>&1 &
else
echo 'logstash exist,will be killed and restart'
kill -9 $pids
echo 'logstash has been killed...'
echo 'logstash restart now...'
nohup ./logstash/bin/logstash -f /home/elker/logstash/config/logstash.conf > /home/elker/nohup.log 2>&1 &
fi然后启动准备好的java应用(无需太复杂,这篇文章中的就行,因为日志有json格式的日志),做一笔应用的交易,查看应用的日志,再查看es的数据记录
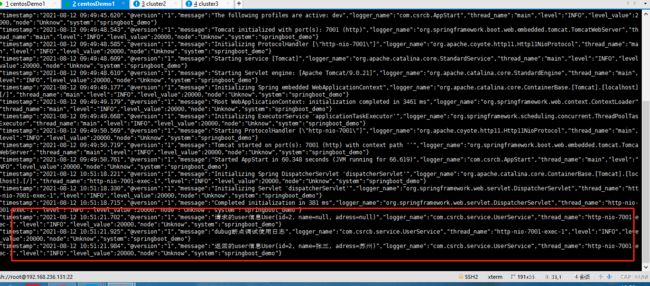
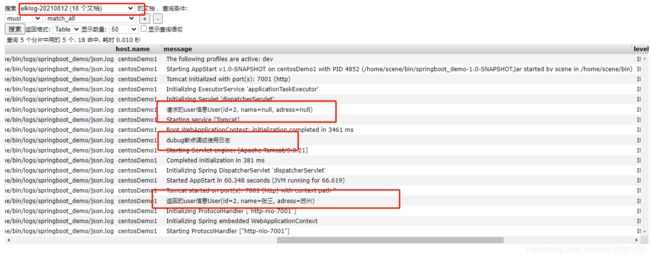
完美成功将kafka的记录推送至es,据此elk日志集成搭建成功仅一步之遥
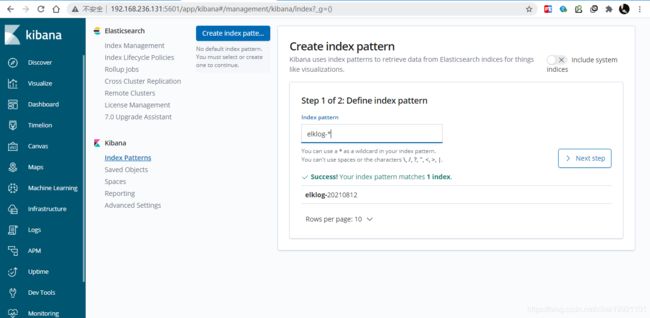
启动kibana,在浏览器查看,初步启动配置一下,然后使用@timestamp,elk日志集成搞定

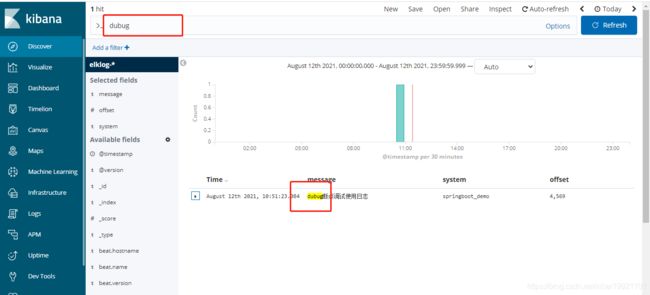
 我的应用是单点应用没有结合微服务,就没有结合日志链路跟踪,实际在微服务中一笔交易可能涉及多应用之间的服务调用,此时普通的方法根据报文中的某些特殊的内容去搜索日志,然后定位就有些不足了,此时日志链路跟踪就发挥作用了,先根据特殊的字符在某一应用中找到交易的traceId,然后根据traceId去定位分析就很方便快捷
我的应用是单点应用没有结合微服务,就没有结合日志链路跟踪,实际在微服务中一笔交易可能涉及多应用之间的服务调用,此时普通的方法根据报文中的某些特殊的内容去搜索日志,然后定位就有些不足了,此时日志链路跟踪就发挥作用了,先根据特殊的字符在某一应用中找到交易的traceId,然后根据traceId去定位分析就很方便快捷