决策树预测音乐喜好(弱)
文章目录
- pandas
- 决策树实现:年龄性别预测喜欢歌曲风格
- 输出可视化决策树
pandas
本文档代码语法为jupyter notebook格式
:数据来源
视频教程,Youtube
import pandas as pd # 导包
df = pd.read_csv('vgsales.csv') # 导入数据
df.shape # 显示几行几列
df.describe() # 返回数据集中每一列的一些基本信息
df.values # 二维数组输出
决策树实现:年龄性别预测喜欢歌曲风格
:数据来源
sklearn机器学习库
需要对数据进行清洗(去重,删空值),准确率才高
- 导入需要的包和数据集
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split # 方便拆分数据集
from sklearn.metrics import accuracy_score # 比对准确度
# from sklearn.externals import joblib # 保存和加载模型的方法
import joblib
music_data = pd.read_csv('music.csv')
- 将数据集拆分为,输入集和输出集
X = music_data.drop(columns=['genre']) # 新建数据一个集,不包含columns中的值
y = music_data['genre'] # 输出集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # 测试大小 0.2=20个
# 训练数据,测试数据,训练答案,测试答案
# 数据选择是随机的,所以每次准确度都不同
- 构建机器学习算法模型
model = DecisionTreeClassifier()
model.fit(X_train,y_train) # 导入训练数据
- 保存或者加载模型
joblib.dump(model, 'music-recommender.joblib') # 保存
model = joblib.load('music-recommender.joblib') # 加载
- 预测,与答案比较出准确度
predictions = model.predict(X_test) # 预测
source = accuracy_score(y_test, predictions) # 准确度
print(source) # 1.0
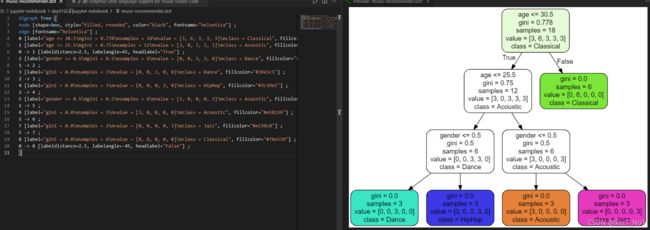
输出可视化决策树
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
music_data = pd.read_csv('music.csv')
X = music_data.drop(columns=['genre'])
y = music_data['genre']
model = DecisionTreeClassifier()
model.fit(X, y)
# ==================
tree.export_graphviz(model, out_file='music-recommender.dot',
feature_names=['age', 'gender'],
class_names = sorted(y.unique()),
label = 'all',
rounded = True,
filled = True)
# 输出可视化决策树文件
在vscode中安装Graphviz (dot) language ...插件,打开.dot文件,右键open....就可以看到