量化感知训练QAT,quantization aware training
神经网络量化分为两类,一类是训练以后再量化,第二类是边训练边量化
量化感知训练是神经网络常见的量化方式,可以模拟量化,量化的方式主要有
常用的量化方式有PACT、Dorefa、LSQ等内容
PACT:https://arxiv.org/abs/1805.06085v2
Dorefa:(PDF) DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients (researchgate.netL
LSQ: [1902.08153] Learned Step Size Quantization (arxiv.org)
LSQ+:[2004.09576] LSQ+: Improving low-bit quantization through learnable offsets and better initialization (arxiv.org)
量化的主要过程是先模拟量化然后再反量化,像0.32,量化到8bit,先乘以255,0.32*255=81.6,经过round函数以后就是82。然后再反量化到32-bit,82/255=0.321568627451,这样子量化前和反量化以后的值就不相同了,原来的值等于0.32,反量化以后等于0.321568627451
round(0.32*255)/255=0.321568627451
LSQ和LSQ的实现可以看这个GitHub - ZouJiu1/LSQplus: LSQ+ or LSQplus ,实现了LSQ和LSQ+的相应内容,实现语言是Pytorch
量化时反向传播梯度使用了 STE,即straight-through estimator,去掉round函数,然后直接将梯度传递给浮点数
概念
量化公式一般是这个形式:x1 = round(x*s+z)
反量化公式一般是这个形式:x2 = (x1-z)/s
公式变化形式多,但基本都是这样子的格式的
QAT时,要进行两步的,要经过量化和反量化,前向传播进行量化和反量化,反向传播梯度还是给的浮点数
对称量化和非对称量化,对称量化是指零点为0,非对称量化是指零点不一定为0
per_channel和per_layer,per_channel只针对权重weight而言,每个weight的channel都有单独的量化参数scale和零点z,由于计算复杂度和时间的原因,输入不会做per_channel。per_layer针对权重和输入,所有的channel共用同一对量化参数scale和零点z
Dorefa
主要是对权重、输入、和梯度进行了量化,这个是基础量化公式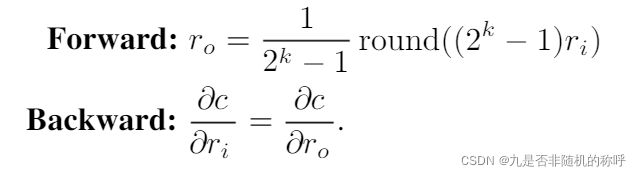
这个是权重的量化公式,这里的![]() 代表基础量化公式,括号内将权重限制到0~1之间
代表基础量化公式,括号内将权重限制到0~1之间
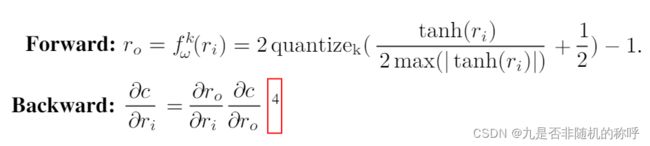 输入的量化公式就是基础量化方式
输入的量化公式就是基础量化方式
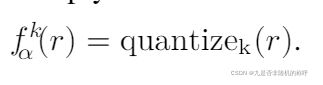
PACT:
PACT对使用relu激活值的神经网络进行量化,主要加入了一个可训练的参数α,由于relu=max(0, x),没有上界,因此PACT对relu激活函数加入了上界限制,不能大于值α,PACT=min(α, max(0, x)),数值量化方式还是常见的均匀量化方式
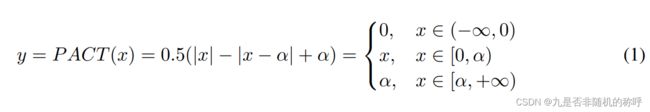
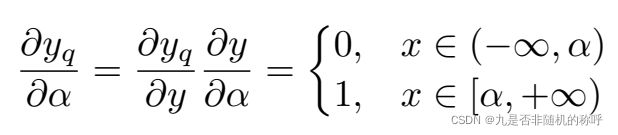
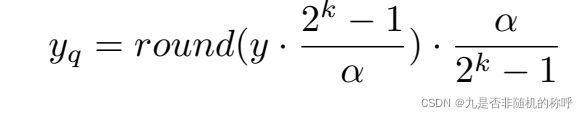
α值得初始化使用了浮点模型经过relu以后得激活值得绝对值的最大值
LSQ
LSQ对量化公式里的参数scale进行了调整,可以让网络训练的同时,训练scale值,不再是定值了。这里的s就是scale,-Qn是下界,Qp是上界,先量化到v横杠,然后反量化到v帽
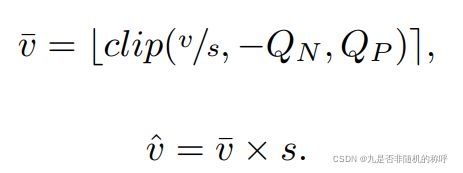
梯度传递也是使用了STE方式,去掉了round函数,也就是上图的最外层括号
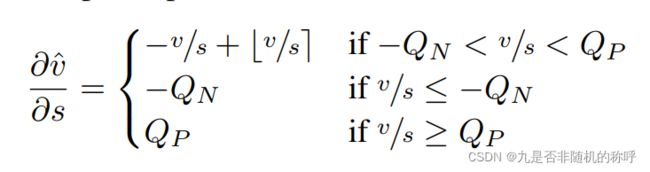
s值得初始化,使用了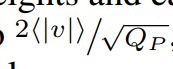 ,即权重或者输入的绝对值得平均值乘以2然后除以上界Qp开根号
,即权重或者输入的绝对值得平均值乘以2然后除以上界Qp开根号
在反向传播梯度update值s的时候,对梯度进行了处理,乘上了相应的系数,不然可能难以收敛,![]() ,这里的Nw是权重的元素总个数,Qp是上界。
,这里的Nw是权重的元素总个数,Qp是上界。
![]() ,这里的Nf是输入也就是feature map元素的个数,Qp是上界
,这里的Nf是输入也就是feature map元素的个数,Qp是上界
LSQ+
在LSQ的基础上进一步,LSQ可以训练量化参数s即scale,这里可以训练量化参数β,即零点z,

反向传播梯度仍然是使用了STE,去掉了round函数
权重的量化使用了对称量化,即β=0,s的初始化值使用了这个公式
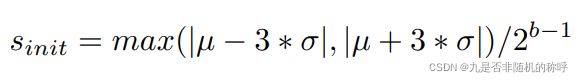
输入量化默认是非对称量化,初始化使用了这个公式进行反向传播,在最开始的几个steps,梯度update并初始化s和β,过了相应的steps以后,就使用上图的公式进行update
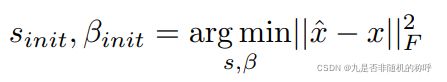
当然,也可以使用这个公式进行初始化
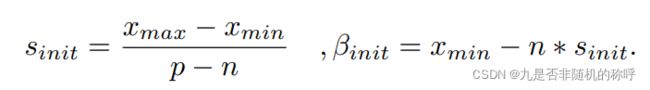
常见
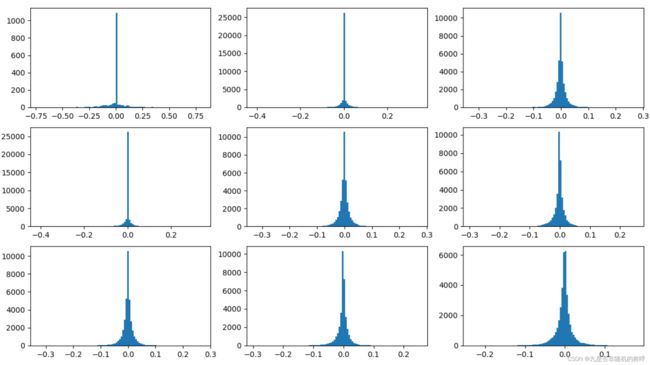
权重一般是对称分布的,符合高斯分布或者高斯混合分布
激活值即输入一般是非对称分布的,也就是不关于Y轴对称
LSQ、LSQ+里的量化参数的梯度计算,要乘以相应的系数,不然可能会难以收敛,或者梯度爆炸,可以参考这个github: ZouJiu1/LSQplus: LSQ+ or LSQplus (github.com)
权重值的分布情况
画图使用的是每个layer的权重,per_layer,不是per_channel