EfficientDet: Scalable and Efficient Object Detection 论文学习
Abstract
模型效率在计算机视觉领域愈发重要。本文中,作者系统地研究了神经网络结构设计,提出了多项关键优化以提升模型效率。首先,作者提出了一个加权的双向特征金字塔网络(BiFPN),使得多尺度特征融合更加简单而快速;其次,作者提出了一个混合缩放的方法,同时对主干网络、特征网络和边框/类别预测网络的深度、分辨率和宽度进行缩放。基于这些改进,作者设计了多个目标检测器,叫做EfficientDet,在资源有限的条件下,它们可以持续地取得性能提升。特别地,EfficientDet-D6 在单个模型与单个尺度的情况下,在COCO数据集上实现了SOTA的 50.9 % 50.9\% 50.9%的mAP,参数量为5200万个,FLOPs数量为2290亿次,这要比目前最佳的模型参数量少 4 x 4x 4x倍,FLOPs 要少 13 x 13x 13x倍,但是mAP要高出 + 0.2 % +0.2\% +0.2%。代码位于:https://github.com/google/automl/tree/master/efficientdet。
1. Introduction
近些年,目标检测领域取得了显著的突破;同时,SOTA目标检测器对算力的消耗也越来越高。例如,最新的基于 AmoebaNet 的 NAS-FPN 检测器实现了SOTA的准确率,但是它需要1.67亿个参数和30450亿次FLOPs(要比RetinaNet高出30倍)。这么大的模型与昂贵的算力成本使它们在实际部署时非常困难,比如机器人和自动驾驶领域对模型大小和延迟有非常高的限制。因为这些资源限制,目标检测模型的效率就变得非常关键。

之前已经有许多工作在朝高效率检测模型努力,如单阶段和anchor-free检测器,或压缩现有的模型。尽管这些方法都朝着更高效率的方向努力,但是可能会牺牲一定的准确率。而且大多数的工作对资源的要求非常特定,而实际应用中(从移动设备到数据中心)所需要的资源都不太一样。
一个自然的问题就是:我们是否可以去构建一个可扩展的检测框架,在给定资源要求范围(如从30亿FLOPs到3000亿次FLOPs)的前提下,它的准确率和效率更高?本文为的就是解决这个问题,系统研究检测器架构的设计。基于单阶段检测方式,作者研究了主干网络、特征融合、类/边框网络的设计选项,找出两个主要的挑战:
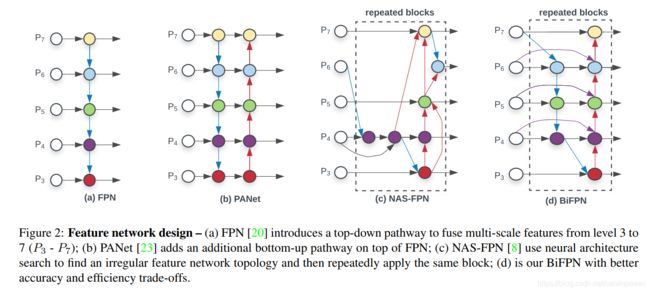
挑战1:高效率的多尺度特征融合—自从[20]提出,FPN被广泛用在多尺度特征融合上。最近 PANet,NAS-FPN 等方法针对跨尺度特征融合,设计了多个网络结构。对于不同的输入特征融合,大多数的工作都只简单地将它们加起,而没有加以区分。但是由于不同的输入特征有着不同的分辨率,作者观测到它们对融合后的输出特征所做的贡献是不一样。为了解决这个问题,作者提出了一个简单而高效率的加权双向特征金字塔网络(BiFPN),加入了可训练的权重来学习不同输入特征的重要度,重复地进行自上而下和自下而上的多尺度特征融合。
挑战2:模型缩放—之前的工作为了实现更高的准确率,主要依赖于更大的主干网络或者更大的输入图像,作者发现当我们既要考虑准确性,也要考虑效率时,对特征网络和类别/边框预测网络进行缩放也很重要。受[36]启发, 作者提出了一个目标检测器的混合缩放方法,对所有的主干网络、特征网络和边框/类别预测网络协同地缩放分辨率/深度/宽度。
最后作者发现 EfficientNets 实现的准确率要比之前常用的主干网络(ResNets, ResNeXt, AmoebaNet)更高。将 EfficientNet 与本文提出的 BiFPN 和混合缩放方法结合起来,就提出了一个新的目标检测方法,称作EfficientDet,在较少参数量和FLOPs的情况下,它可以取得更高的准确率。图1和图4为COCO数据集上模型的性能比较。在相似的准确率要求下,EfficientDet 使用的 FLOPs要比 YOLOv3 少 28倍,比 RetinaNet 少30倍,比最近基于 ResNet 的 NAS-FPN 少 19倍。在单模型和单测试尺度下,EfficientDet-D6 实现了 50.9 50.9 50.9 mAP,参数量为5200万个,FLOPs 是2290亿次,要比之前最好的模型小4倍,FLOPs少13倍。在CPU和GPU上,EfficientDet 同样要比之前的检测器快3倍和8倍。
做了简单的调整,在 Pascal VOC 2012 语义分割任务上,本文的单模型单尺度的 EfficientDet 取得的 mIOU 是 81.74 % 81.74\% 81.74%,FLOPs为 180亿次,超越了 DeepLab V3+ 1.7 % 1.7\% 1.7%,FLOPs要少9.8倍。
2. Related Work
单阶段检测器:现有的检测器分类多是看它是否包含兴趣区域候选步骤(有就是双阶段,没有就是单阶段)。双阶段检测器通常更加灵活、准确,单阶段检测器更加简单、高效。由于单阶段检测器的效率高而且非常简洁,最近获得了大量的关注。本文中,作者主要遵循了单阶段检测器的设计,证明我们通过优化网络结构,既可以实现更高的准确率,也可以实现更高的效率。
多尺度特征表示:目标检测的一个主要难题就是,有效地表示和处理多尺度特征。早期的检测器通常在主干网络的金字塔特征层级上直接进行预测。FPN 提出了一个自上而下的 pathway,结合多尺度特征。PANet 延续了这个想法,在FPN之上增加了一个自下而上的 path 聚合网络;STDL 提出了一个尺度转换模块,研究跨尺度特征;M2det 提出了一个 U形模块,融合多尺度特征,G-FRNet 引入了门单元,控制不同特征间的信息流。最近 NAS-FPN 利用神经结构搜索,自动地设计特征网络拓扑结构。尽管它的效果不错,NAS-FPN在搜索时需要几千小时的GPU计算,最终的特征网络非常不规则,不易理解。本文的目的在于以更直观、规则的方式去优化多尺度特征融合。
模型缩放:为了实现更高的准确率,利用更大的主干网络,或增大输入图像分辨率是常用的增强 baseline 模型的方法。近来的一些工作证明了增加通道大小,堆叠特征网络可以实现更高的准确率。这些缩放方法主要关注在单一或有限的缩放维度中。最近[36]通过协同地增大网络的宽度、深度和分辨率,在图像分类中实现了显著的性能提升。
3. BiFPN
这部分,作者先是梳理了多尺度特征融合问题,然后介绍了BiFPN的核心思想:高效的双向跨尺度连接与加权的特征融合。
3.1 Problem Formulation
多尺度特征融合的目的就是在不同的分辨率上聚合特征。给定一组多尺度特征 P ⃗ i n = ( P l 1 i n , P l 2 i n , . . . ) \vec P^{in} = (P^{in}_{l_1}, P^{in}_{l_2},...) Pin=(Pl1in,Pl2in,...),其中 P l i i n P^{in}_{l_i} Pliin 表示第 l i l_i li个层级,我们目的是找到一个数学变换 f f f,可以高效率地聚合不同的特征,输出一组新的特征: P ⃗ o u t = f ( P ⃗ i n ) \vec P^{out} = f(\vec P^{in}) Pout=f(Pin)。图2(a) 为传统的自上而下的 FPN。它将层级3到7作为输入特征, P ⃗ i n = ( P 3 i n , . . . , P 7 i n ) \vec P^{in} = (P_3^{in},...,P_7^{in}) Pin=(P3in,...,P7in),其中 P i i n P_i^{in} Piin代表一个特征层级,分辨率是原图的 1 / 2 i 1/2^i 1/2i。如果原始输入分辨率是 640 × 640 640\times 640 640×640,则 P 3 i n P_3^{in} P3in代表的第三个特征层级分辨率就是 ( 640 / 2 3 ) × ( 640 / 2 3 ) = 80 × 80 (640/2^3)\times (640/2^3)=80\times 80 (640/23)×(640/23)=80×80,而 P 7 i n P_7^{in} P7in代表的第七个层级就是 5 × 5 5\times 5 5×5。传统的FPN通过自上而下的方式聚合多尺度特征:
P 7 o u t = C o n v ( P 7 i n ) P_7^{out}=Conv(P^{in}_7) P7out=Conv(P7in)
P 6 o u t = C o n v ( P 6 i n + R e s i z e ( P 7 o u t ) ) P_6^{out}=Conv(P^{in}_6 + Resize(P_7^{out})) P6out=Conv(P6in+Resize(P7out))
. . . ... ...
P 3 o u t = C o n v ( P 3 i n + R e s i z e ( P 4 o u t ) ) P_3^{out}=Conv(P^{in}_3 + Resize(P_4^{out})) P3out=Conv(P3in+Resize(P4out))
其中, R e s i z e Resize Resize通常是上采样或下采样,将分辨率匹配起来,而 C o n v Conv Conv是特征处理的一个卷积操作。
3.2 Cross-Scale Connections
传统自上而下的FPN只有一条信息流。为了解决这个问题,PANet 增加了一条自下而上的 path 聚合网络,如图2(b)所示。最近 NAS-FPN 利用神经结构搜索来搜寻更优的跨尺度特征网络结构,但是它需要数千小时的GPU搜索,而且找到的模型也是不规则的,很难去理解或改造,如图2©所示。
通过研究这三个网络的性能和效率(表5),作者发现 PANet 的准确率要比 FPN 和 NAS-FPN 高,但是它的参数量和计算量要更高。为了提升模型效率,本文提出了几个针对跨尺度连接优化的地方:首先,去除只有单个输入 edge 的节点。这个想法很简单:如果一个节点只有一个输入 edge,没有特征融合,那么它对特征网络的贡献就比较少。这就产生了一个简化版的双向网络。其次,从原始输入到输出节点,增加了一条 edge,如果它们位于同一个层级上,目的是融合更多的特征,而不带来额外的成本;第三,与PANet只有自上而下和自下而上的path不同,作者将每个双向path(top-down, bottom-up)看作为一个特征网络层,多次重复该层,使我们拥有更加高层级的特征融合。4.2 节会讨论在不同资源的条件下,使用一个混合缩放的方法来选择该层的数量。有了上述改进,作者将这个新的特征网络称作双向特征金字塔网络(BiFPN),如图2和图3所示。
3.3 Weighted Feature Fusion
融合不同分辨率的多个输入特征时,常用方式是首先将它们缩放到相同大小,然后再加起来。特征注意力网络[19]引入了全局自注意力上采样,恢复像素点的位置信息,在[8]中进一步得到研究。
之前的特征融合方法将所有的输入特征同等对待,不加区分。但是,作者发现因为不同分辨率的输入特征不一样,它们对输出特征的贡献也不相等。为了解决这个问题,本文在特征融合时为每个输入加上了一个权重,使得网络可以学习每个输入特征的重要程度。基于此想法,作者想出了三个加权融合方法:
Unbounded Fusion: O = ∑ i ω i ⋅ I i O=\sum_{i} \omega_i \cdot I_i O=∑iωi⋅Ii,其中 ω i \omega_i ωi是一个可以学习的权重,可以是标量(逐特征),也可以是向量(逐通道)或多维矩阵(逐像素)。作者发现标量就可以取得不错的准确率,而且计算成本最小。但是由于标量权重无界,它可能会引起训练不稳定。因而作者为了让每个权重大小有界,使用了权重归一化。
Softmax-based Fusion: O = ∑ i e ω i ∑ j e ω j ⋅ I i O=\sum_i \frac{e^{\omega_i}}{\sum_j e^{\omega_j}}\cdot I_i O=∑i∑jeωjeωi⋅Ii。可以对每个权重使用 softmax,这样所有的权重都被归一化为 [ 0 , 1 ] [0,1] [0,1]区间的概率值,表示每个输入的重要度。但是如6.3节所说的,softmax会造成GPU硬件明显的降速。为了尽可能地降低延迟,作者进一步提出了一个快速融合的方法。
Fast Normalization Fusion: O = ∑ i ω i ϵ + ∑ j ω j ⋅ I i O=\sum_i \frac{\omega_i}{\epsilon + \sum_j \omega_j} \cdot I_i O=∑iϵ+∑jωjωi⋅Ii,对每个 ω i \omega_i ωi使用 ReLU,保证 ω i ≥ 0 \omega_i \geq 0 ωi≥0,其中 ϵ = 0.0001 \epsilon=0.0001 ϵ=0.0001,避免数值不稳定。相似地,每个归一化后的权重位于0和1之间,但是因为没有使用softmax,这种实现就更加高效。实验表明这种方法与基于softmax的方法有着类似的学习行为和准确率,但是在GPU上要快 30 % 30\% 30%(表6)。
最终的BiFPN整合了双向跨尺度连接和快速归一化融合。举个例子,图2(d)中所展示的BiFPN的第六个层级如下:
P 6 t d = C o n v ( ω 1 ⋅ P 6 i n + ω 2 ⋅ R e s i z e ( P 7 i n ) ω 1 + ω 2 + ϵ ) P_6^{td} = Conv(\frac{\omega_1 \cdot P_6^{in} + \omega_2 \cdot Resize(P_7^{in})}{\omega_1 + \omega_2 + \epsilon}) P6td=Conv(ω1+ω2+ϵω1⋅P6in+ω2⋅Resize(P7in))
P 6 o u t = C o n v ( ω 1 ′ ⋅ P 6 i n + ω 2 ′ ⋅ P 6 t d + ω 3 ′ ⋅ R e s i z e ( P 5 o u t ) ω 1 ′ + ω 2 ′ + ω 3 ′ + ϵ ) P_6^{out} = Conv(\frac{\omega_1' \cdot P_6^{in} + \omega_2' \cdot P_6^{td} + \omega_3' \cdot Resize(P_5^{out})}{\omega_1' + \omega_2' + \omega_3' + \epsilon}) P6out=Conv(ω1′+ω2′+ω3′+ϵω1′⋅P6in+ω2′⋅P6td+ω3′⋅Resize(P5out))
其中 P 6 t d P_6^{td} P6td是top-down pathway中第六层级的中间特征, P 6 o u t P_6^{out} P6out是bottom-up pathway中第六层级的输出特征。其它特征的构建方式都差不多。为了进一步提升效率,作者在特征融合时使用了深度可分离卷积,在每个后面使用了batch normalization和激活函数。
4. EfficientDet
基于BiFPN,作者设计了多个检测模型,叫做EfficientDet。这一部分,作者介绍了网络的结构和一个新的混合缩放方法。
4.1 EfficientDet Architecture

图3展示了EfficientDet的整体结构,大致遵循了单阶段检测器的模式。作者使用了 ImageNet 预训练的 EfficientNets 作为主干网络。BiFPN 作为特征网络,将主干网络中的第3到第7层级 { P 3 , P 4 , P 5 , P 6 , P 7 } \{P_3, P_4, P_5, P_6,P_7\} { P3,P4,P5,P6,P7}的特征作为输入,然后重复地使用top-down和bottom-up双向特征融合。融合后的特征输入进类别与边框网络,输出目标类别和边框预测。与[21]相似,类别与边框网络的权重在所有的特征层级共享。
4.2 Compound Scaling
为了优化准确率和效率,作者设计了多个模型来符合各项资源要求,核心就是如何增强 baseline EfficientDet 模型。
之前的工作都是通过更大的主干网络(ResNeXt或AmoebaNet)、更大的输入图像,或堆叠更多的FPN层来增强基线检测器。这些方法通常都没什么效果,因为它们只关注在单个或有限的缩放维度上。最近的工作证明在图像分类任务上,协同地扩大网络的所有维度(宽度、深度、分辨率)能够取得显著的性能提升。受这些工作启发,作者提出了一个新的针对目标检测任务的混合缩放方法,使用一个简单的混合系数 ϕ \phi ϕ来协同地增大主干网络、BiFPN 网络、类别/边框网络和分辨率。目标检测器的缩放维度要多于图像分类模型,这样网格搜索法的计算成本就太高了。因而,作者使用了一个基于启发式学习的缩放方法,但仍然遵循协同缩放所有维度的思想。
主干网络:作者复用了EfficientNet-B0到B6的宽度/深度缩放系数,这样就可以复用ImageNet预训练checkpoints了。
BiFPN:作者线性增加BiFPN 的深度 D b i f p n D_{bifpn} Dbifpn(层数),因为深度需要被四舍五入为较小的整数。对于BiFPN的宽度 W b i f p n W_{bifpn} Wbifpn(通道数),指数地增长BiFPN宽度 W b i f p n W_{bifpn} Wbifpn(通道数)。作者对一组值 { 1.2 , 1.25 , 1.3 , 1.35 , 1.4 , 1.45 } \{1.2,1.25,1.3,1.35,1.4,1.45\} { 1.2,1.25,1.3,1.35,1.4,1.45}使用网格搜索,选择最佳值1.35作为BiFPN的宽度缩放因子。BiFPN的宽度和深度通过下面等式来缩放:
W b i f p n = 64 ⋅ ( 1.3 5 ϕ ) , D b i f p n = 3 + ϕ W_{bifpn}=64\cdot (1.35^\phi),\quad \quad D_{bifpn}=3+\phi Wbifpn=64⋅(1.35ϕ),Dbifpn=3+ϕ
边框/类别预测网络:将它们的宽度与BiFPN设为一样大,即 W p r e d = W b i f p n W_{pred}=W_{bifpn} Wpred=Wbifpn,但是通过下面的等式线性地增加其深度(层个数):
D b o x = D c l a s s = 3 + ⌊ ϕ / 3 ⌋ D_{box}=D_{class}=3+\lfloor \phi/3 \rfloor Dbox=Dclass=3+⌊ϕ/3⌋
输入图像分辨率:因为我们在BiFPN中使用了第三特征层级到第七个特征层级,输入分辨率必须可以被 2 7 = 128 2^7=128 27=128整除,所以我们使用下面的等式线性地增大分辨率:
R i n p u t = 512 + ϕ ⋅ 128 R_{input}=512+\phi \cdot 128 Rinput=512+ϕ⋅128
对上面三个等式输入不同的 ϕ \phi ϕ,作者构建了表1中的EfficientDet-D0 ( ϕ = 0 ) (\phi=0) (ϕ=0)到D6 ( ϕ = 6 ) (\phi=6) (ϕ=6)。注意这些缩放因子都是基于启发式学习的,可能不是最优的,但是作者证明相较于其它的单一维度缩放方法,该缩放方法可以显著地提升效率,如图6所示。


5. Experiments
5.1 EfficientDet for Object Detection
作者在COCO 2017检测数据集上评估了EfficientDet性能。每个模型都是通过SGD来训练,momentum是0.9, weight decay是 4 e − 5 4e-5 4e−5。学习率在第一个epoch中线性地从0增大到0.16,然后通过cosine decay rule 进行退火。每个卷积后都加上一个同步 Batch Normalization,BN decay 是0.997, ϵ \epsilon ϵ是 1 e − 4 1e-4 1e−4。作者使用了Swish激活函数与指数滑动平均数,decay是0.9998。作者也使用了focal loss, α = 0.25 , γ = 1.5 \alpha=0.25,\gamma=1.5 α=0.25,γ=1.5,aspect ratio是 { 1 / 2 , 1 , 2 } \{1/2,1,2\} { 1/2,1,2}。每个模型训练的batch size是128,在32个TPUv3核上训练,每个核的batch size是4。作者使用RetinaNet预处理,训练时多分辨率裁剪/缩放与翻转增强。注意,作者对本文模型没有使用自动增强。
表2比较了EfficientDet与其它目标检测模型,在相同的单模型单尺度设定下进行,没用测试时增强。在不同的准确率和资源要求下,EfficientDet 取得的准确率和效率都要高于其它检测器。当准确率要求相对较低时,EfficientDet-D0 取得的准确率与YOLOv3接近,但是FLOPs要少28倍。与RetinaNet和Mask R-CNN相比,EfficientDet-D1 的准确率相似,但是参数少8倍,FLOPs少25倍。在高准确率要求下,EfficientDet 也超过了 NAS-FPN 和它的增强版本,参数和FLOPs都少许多。EfficientDet-D6 在单模型单尺度下,实现了 50.9 50.9 50.9的mAP,而模型要比之前最优的模型小4倍,FLOPs要少13倍。与AmoebaNet+NAS-FPN+AutoAugment模型不同,它需要特别的设定(比如将anchors从 3 × 3 3\times 3 3×3改为 9 × 9 9\times 9 9×9,并行训练模型),所有的EfficientDet 模型使用的都是 3 × 3 3\times 3 3×3 anchors,没有用并行训练。
除了参数量和FLOPs,作者在Titan-V 显卡和单线程Xeon CPU上也比较了速度。每个模型跑10遍,batch size为1, 然后计算均值和标准方差。图4展示了模型大小、GPU延迟和单线程CPU延迟的比较。为了公平比较,这些结果都是在同一台设备上得到的。与之前的检测器相比,EfficientDet 的模型在GPU上要快3.2倍,CPU上要快8.1倍。