大家好,我是查理。
知己知彼,方可百战不殆。在学习技术的时候我们往往面临太多选择而不知所措,可能是各个方面都有涉猎,对某个领域没有深入研究,看似什么都会,真要让你做个什么东西的时候就显得捉肘见襟。如果我们能从招聘职位所需的技能开始学习,便可练就一身硬功夫,为实战应用中打下良好的基础。
我们的目的主要是通过python抓取拉钩网的招聘详情,并筛选其中的技能关键词,存储到excel中。
一、获取职位需求数据
通过观察可以发现,拉勾网的职位页面详情是由 http://www.lagou.com/jobs/ + ***** (PositionId).html 组成,而PositionId可以通过分析Json的XHR获得。而红框里的职位描述内容是我们要抓取的数据。
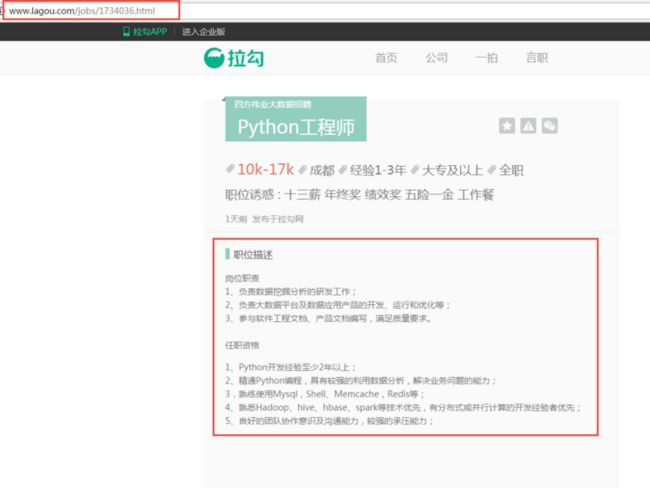

知道了数据的源头,接下来就按照常规步骤包装Headers,提交FormData来获取反馈数据。
获取PositionId列表所在页面:
#获取职位的查询页面,(参数分别为网址,当前页面数,关键词)
def get_page(url, pn, keyword):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Origin': 'http://www.lagou.com'
}
if pn == 1:
boo = 'true'
else:
boo = 'false'
page_data = urllib.urlencode([
('first', boo),
('pn', pn),
('kd', keyword)
])
req = urllib2.Request(url, headers=headers)
page = urllib2.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
通过Json获取PositionId:
#获取所需的岗位ID,每一个招聘页面详情都有一个所属的ID索引
def read_id(page):
tag = 'positionId'
page_json = json.loads(page)
page_json = page_json['content']['positionResult']['result']
company_list = []
for i in range(15):
company_list.append(page_json[i].get(tag))
return company_list
合成目标url:
#获取职位页面,由positionId和BaseUrl组合成目标地址
def get_content(company_id):
fin_url = r'http://www.lagou.com/jobs/%s.html' % company_id
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Origin': 'http://www.lagou.com'
}
req = urllib2.Request(fin_url, headers=headers)
#page = urllib.urlopen(req).read()
page = urllib2.urlopen(req).read()
content = page.decode('utf-8')
return content
二、对数据进行处理
获取数据之后,需要对数据进行清洗,通过BeautifulSoup抓取的职位内容包含Html标签,需要让数据脱去这层“外衣”。
#获取职位需求(通过re来去除html标记),可以将职位详情单独存储
def get_result(content):
soup = Bs(content, 'lxml')
job_description = soup.select('dd[class="job_bt"]')
job_description = str(job_description[0])
rule = re.compile(r'<[^>]+>')
result = rule.sub('', job_description)
return result
现在得到的数据就是职位描述信息,我们要从职位信息当中筛选我们所关注的任职要求关键词。

我们将这些关键词筛选出来,存储到List当中。经过对整个500+职位进行爬取,我们得到了职位技能关键词的总表。
#过滤关键词:目前筛选的方式只是选取英文关键词
def search_skill(result):
rule = re.compile(r'[a-zA-z]+')
skil_list = rule.findall(result)
return skil_list
对关键词按照500+职位需求出现的频次进行排序,选取频次排序Top80的关键词,去除无效的关键词。
# 对出现的关键词计数,并排序,选取Top80的关键词作为数据的样本
def count_skill(skill_list):
for i in range(len(skill_list)):
skill_list[i] = skill_list[i].lower()
count_dict = Counter(skill_list).most_common(80)
return count_dict
三、对数据进行存储和可视化处理
# 对结果进行存储并生成Area图
def save_excel(count_dict, file_name):
book = xlsxwriter.Workbook(r'E:\positions\%s.xls' % file_name)
tmp = book.add_worksheet()
row_num = len(count_dict)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, ['关键词', '频次'])
else:
con_pos = 'A%s' % i
k_v = list(count_dict[i-2])
tmp.write_row(con_pos, k_v)
chart1 = book.add_chart({'type':'area'})
chart1.add_series({
'name' : '=Sheet1!$B$1',
'categories' : '=Sheet1!$A$2:$A$80',
'values' : '=Sheet1!$B$2:$B$80'
})
chart1.set_title({'name':'关键词排名'})
chart1.set_x_axis({'name': '关键词'})
chart1.set_y_axis({'name': '频次(/次)'})
tmp.insert_chart('C2', chart1, {'x_offset':15, 'y_offset':10})
book.close()
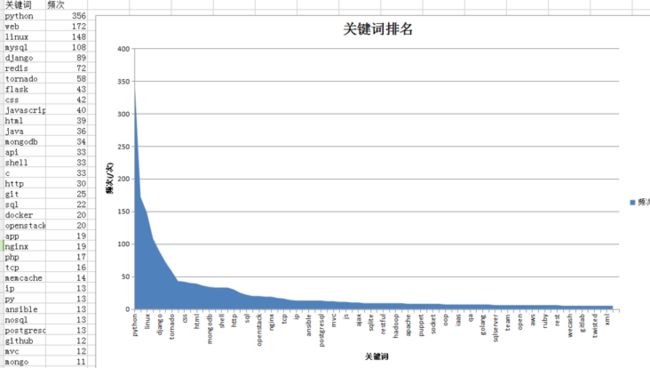
数据可视化展示
如发现错误或看不懂的地方,可在评论区提出,大家一起交流!
如果文章对您有帮助,点赞+关注,您的支持是我最大的动力