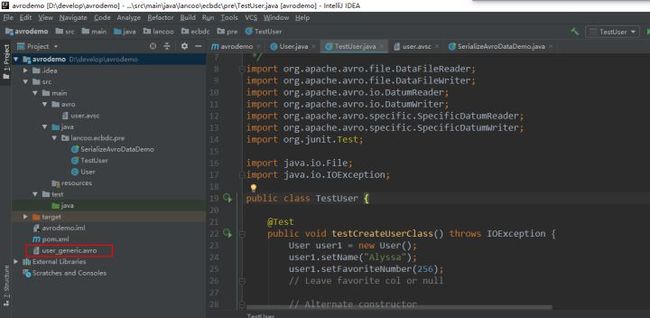
User user1 = new User();
user1.setName("Alyssa");
user1.setFavoriteNumber(256);
// Leave favorite col or null
// Alternate constructor
User user2 = new User("Ben", 7, "red");
// Construct via builder
User user3 = User.newBuilder()
.setName("Charlie")
.setFavoriteColor("blue")
.setFavoriteNumber(null)
.build();
// Serialize user1, user2 and user3 to disk
DatumWriter userDatumWriter = new SpecificDatumWriter(User.class);
DataFileWriter dataFileWriter = new DataFileWriter(userDatumWriter);
dataFileWriter.create(user1.getSchema(), new File("user_generic.avro"));
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.append(user3);
dataFileWriter.close();
// Deserialize Users from disk
DatumReader userDatumReader = new SpecificDatumReader(User.class);
DataFileReader dataFileReader = new DataFileReader(new File("user_generic.avro"), userDatumReader);
User user = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
user = dataFileReader.next(user);
System.out.println(user);
}
#
# A fatal error has been detected by the Java Runtime Environment:
#
# EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x00000000777c3290, pid=5632, tid=6656
#
# JRE version: Java(TM) SE Ru
Spring 中提供一些Aware相关de接口,BeanFactoryAware、 ApplicationContextAware、ResourceLoaderAware、ServletContextAware等等,其中最常用到de匙ApplicationContextAware.实现ApplicationContextAwaredeBean,在Bean被初始后,将会被注入 Applicati
在Java项目中,我们通常会自己写一个DateUtil类,处理日期和字符串的转换,如下所示:
public class DateUtil01 {
private SimpleDateFormat dateformat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public void format(Date d
问题描述:
在实现类中的某一或某几个Override方法发生编译错误如下:
Name clash: The method put(String) of type XXXServiceImpl has the same erasure as put(String) of type XXXService but does not override it
当去掉@Over