在「HBase」中, 从逻辑上来讲数据大概就长这样:
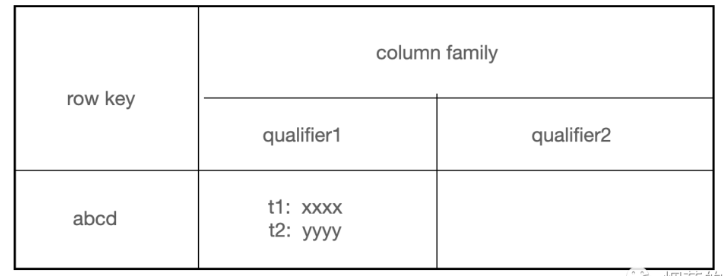
单从图中的逻辑模型来看, HBase 和 MySQL 的区别就是:
将不同的列归属与同一个列族下
支持多版本数据
这看着感觉也没有那么太大的区别呀, 它解决了 MySQL 的那些问题呢? 每一个新事物的出现, 都是为了解决原本存在的问题.
对写入友好, 支持异步大批量并发写入
可动态添加列
按列存储数据, 不存在的列不会落盘, 节省空间. 而 MySQL 中不存在的内容也要用 null 填充
支持海量数据分布式存储(BigTable 最开始就是 Google 为了解决数据存储问题而提出来的)
等等
那么他是如何解决这些问题的呢? 他的数据是如何进行存储的呢?
HBase 数据物理结构
在介绍其物理结构之前, 要先简单提一下 LSM 树
LSM树
和 MySQL 所使用的B+树一样, 也是一种磁盘数据的索引结构. B+树是一种对读取友好的存储结构, 但是当大量写入的时候, 比如日志信息, 因为涉及到随机写入, 就显得捉襟见肘了.
而「LSM树」就是针对这种大量写入的场景而提出的. 他的中文名字叫: 日志结构合并树. 文件存储的是对数据的修改操作, 数据会 append 但不会去修改原有的数据. 是顺序写入操作.
但是, 如果不管不顾的将所有的操作都顺序写入了, 大数据培训那读取数据的时候没有任何根据, 需要扫描所有操作才能读到. 「LSM 树」的做法是, 先在内存中维护一份小的有序的数据(内存不存在随机读写的问题), 当这份数据超过一定大小的时候, 将其整个放入磁盘中.
这样, 磁盘中就存在很多个有序的文件了, 但是会有大量的小文件, 读取数据时要依次查找, 导致读取性能降低. 这时就需要对多个小文件进行多路归并合成一个文件来优化读取的性能.
至此, 基本就是「LSM 树」的全部思想了.
在内存中维护一个有序的数据
将内存中的数据push 到磁盘中
将磁盘中的多个有序文件进行归并, 合成一个较大的有序文件
HBase存储
在「HBase」中, 数据的存储就使用了 「LSM 树」进行存储. 其中每一条数据都是一条操作记录. 那么在「HBase」实现中的部分内容如下.
「内存有序结构的实现」
通过跳表来维护内存中的有序结构, 当一个跳表装满之后, 将禁止新的写入操作并将其 push 到磁盘中, 同时开一个新的数据结构来接收新到的操作请求.
「每条数据的存储内容」
存储了一个KV 键值对, 其中的 V 就是我们写入的值, 而这个 key 由以下部分组成:
row key
列族
列名
时间戳
操作类型: Put、Delete、DeleteColumn、DeleteFamily 等等
整个列表是 key 的顺序列表. 其排序规则如下:
row key小的排在前面
同 row key 比较列族
同列族比较列名
同列名比较时间戳, 时间戳大的在前面.
按照这个顺序进行读取指定 row key 的某一列数据时, 最先拿到的数据就是最新的版本, 若是 delete 操作, 说明最后执行了删除操作, 即使后面有数据, 最新数据也是空.
「磁盘文件的结构」
由三部分组成:
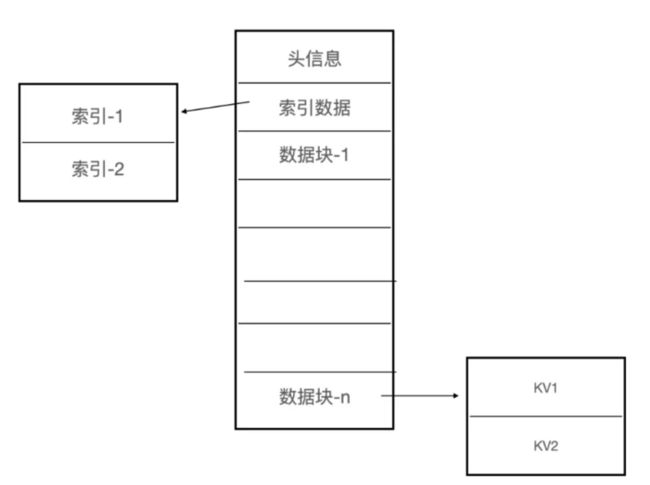
头信息: 存储文件大小, 文件块数量, 索引位置, 索引大小等信息
索引数据: 用户对文件中所有数据块进行索引, 其中每一个数据块都包含一条索引数据, 索引内容包括
数据块的最后一条数据. 用于对索引进行二分查找, 快速定位到指定的数据块
数据块在文件中的位置
数据块的大小
布隆过滤器. 用户在扫描时快速过滤不存在的数据块
数据块. 其中存储了每一条 KV 数据.
按照这个结构, 上海大数据培训用户在进行指定row_key 读取的时候, 每个文件的操作如下:
根据头信息内容, 加载索引数据
通过二分查找, 找到 row_key 在哪一数据块下
根据布隆过滤器过滤掉不存在的数据块, 加速读取
根据数据块的位置和大小, 找到指定数据块并二分查找指定数据
HBase 数据列族式存储
先简单回顾一下行式存储和列式存储.
「行式存储」
行式存储, 将一行数据存储在一起, 一行数据写完了才会写下一行. 例如典型的 MySQL.
行式存储在读取一行数据的时候是比较快的, 但如果读取的是某一列数据, 也需要将整行读取到内存中进行过滤.
「列式存储」
与行式存储相对应的就是列式存储, 既将一列数据存储在一起, 不同列的数据分别存储.
列式存储对于只读取某一列比较友好, 但相对的, 如果要读取多列数据, 需要读取多次并进行合并.
「列族式存储」
而 HBase 中选用了一种折中的方案, 列族式存储, 将列族放到一起存储, 不同列族分别存储.
那么也就是说, 如果一个表有多个列族, 每个列族下只有一列, 那么就等同于列式存储
如果一个表只有一个列族, 该列族下有多个列, 那么就等同与行式存储.
HBase 会将一张表同一列族的数据, 分配到同一个 region 上, 这个region 分配在集群中的某一个 regionServer. 所有的 region 存储在表: hbase:meta 表中, 表结构如下:
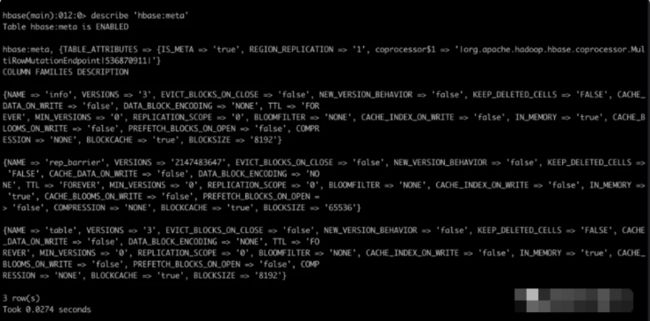
表不同列含义如下:
row_key 由以下字段拼接(逗号)而成
表名
起始 row_key
创建时间戳
上面三个字段的md5
info:regioninfo 主要存储以下数据(json)
STARTKEY: 起始 row_key
ENDKEY: 结束 row_key
NAME: region 名
ENCODED: 不清楚是什么
info:seqnumDuringOpen 表示regionServer 在线时长
info:server 落在哪个 regionServer 上
info:serverstartcode regionServer 的启动时间
等等