前言
- 本篇是关于 MIT 6.S081-2020-Lab10(mmap) 的实现;
- 如果内容上发现有什么问题请不要吝啬您的键盘。
准备工作
mmap() 和 munmap() 这两个系统调用本身是类 UNIX 系统中才有的,这个实验只是仿照着实现它的一部分文件内存映射的功能(玩具)。具体 mmap() 的作用可以看看 [Linux中的mmap映射 [一]](https://zhuanlan.zhihu.com/p/...),了解真实 Linux 中的 mmap() 作用可以为完成这次实验作一个不错的部分的参考。
正式动手做实验之前简单梳理一下我仅从这个实验的角度对 mmap() 的理解,想清楚再做才是第一位。
mmap() 可以将磁盘中文件的内容拷贝到某个物理内存区域中,并在用户进程空间建立指定虚拟地址区域与这个物理内存区域之间的映射。但是在实现中,mmap() 并不会去关心文件的内容,实际数据的拷贝动作是通过 Lazy Allocation 实现的,这也是我们实验五做过的内容。所以 mmap() 大部分的工作将交给 kernel/trap.c 下的 user trap handler(void usertrap(void)) 去处理 page fault、分配新的内存页、拷贝文件内容,而 mmap() 本身只会做很少的相关的初始化的工作。
具体是哪些初始化工作呢?mmap() 的函数签名为 void* mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset)。参考 Lazy Allocation 里 sys_sbrk() 的实现,mmap() 会将在用户进程空间中找到一个足够大的区域,并记录参数信息,以便作为 page fault 处理时的输入。实验指导上提到,这里需要用一个结构体与 process 关联。考虑到用户进程可能 mmap() 多次文件,我们就用一个大小为 16 的结构体数组来存储每一次 mmap() 的相关信息,这里的实现很像每个进程的打开文件表(myproc()->ofile)。
当 (flags & MAP_SHARED) != 0 时,用户对内存中文件数据的任何修改最终都需要通过进程 exit 时调用 munmap() 落盘;而当 (flags & MAP_PRIVATE) != 0 时,这个内存中的文件数据则可以完全游离于磁盘中的对应文件数据,相互之间是透明的。有个问题就是,同时有不同的进程对同一个文件落盘的时候需不需要考虑同步的问题呢?肯定是需要的,只要提前拿好 inode 的互斥锁用完再释放就可以了。获取 inode 锁是为了保护 inode 引用数,并且 inode layer 会为有效屏蔽 buffer cache layer 块落盘的同步操作,我们不用去关心 inode layer 以下的问题。
可能需要提个醒,当 (flags & MAP_SHARED) != 0 时,在真实 Linux 的 mmap() 中对内存文件数据的修改是需要对所有映射这块内存的进程可见的。而实验这里是不需要的,就算需要,考虑到地址访问同步的问题暂时也想不到从软件的层面去解决,因此实验指导上说:
It's OK if processes that map the same
MAP_SHARED file do
not share physical pages.
最后当然就是 fork() 时,父子进程的内容要一致,但别忘了增加 VMA 的struct file 的引用数。
以上基本步骤能通过 mmaptest 的部分,下面指导书上提到的可优化的空间:
MAP_SHARED页的落盘最好是先判断 PTE 的 dirty 是否有置位来选择性地操作。【√】- 用
cow_fork()优化掉原来的fork()。【×】
实验部分
mmap
struct vma 是核心结构体,每个进程都会有固定数量的 vma,我们用一个长为 16 的 struct vma 数组组合到 struct proc 中。其中 valid 字段值取 1 时表示这个 vma 是空闲的;取 0 时表示改 vma 是正被占用的。每个进程都会仅属于自己的 vma 数组,所以并不需要锁来进行访问控制。
/* kernel/proc.h */
struct vma {
int valid;
struct file *f;
uint64 addr;
uint64 length;
int prot;
int flags;
};
#define MAXVMASSZIE 16
// Per-process state
struct proc {
...
struct vma vmas[MAXVMASSZIE];
};
在 mmap 分配 vma 的时候,需要从 myproc()->vmas 里找到一个空闲块作为此次 mmap 占用。因为调用时用户进程没有给出映射的起始逻辑地址,这需要我们自己在用户进程地址空间中找个合适的位置把它放进去。

回忆之前用户进程虚拟地址空间布局,我们只能把文件内容映射到 heap 区域。但如果像 sbrk(int n) 那样从 myproc()->sz 开始分配的话,又引起大量内存内部碎片不说,到时候释放进程时的工作将会非常麻烦,在执行 void uvmfree(pagetable_t pagetable, uint64 sz) 函数时一不小心就会 panic。所以我选择在 trapframe 的下方开始分配我们 vma,分配释放工作都会更加简单,不用考虑 myproc()->sz 的问题。所以调用分配 mmap() 分配 vma 时,会采用 first fit 算法(首次适应算法),打算从 TRAPFRAME(MAXVA-2*PAGESIZE) 开始向低地址扫描,找到第一个可用的的地址时就把 vma 分配到这儿。
每次mmap() 时,我都会把 vma 数组里的 vma->valid = 1 的 vma 放到数组的最右端,这样直接拿数组最右端的 vma 就是空闲的,然后再在剩余的 vma 中根据地址由高到底进行排序,排序算法就用就简单的冒泡排序。
/* kernel/sysfile.c */
void
swap_vma(struct vma* vma1, struct vma *vma2)
{
if (vma1 == vma2)
return;
struct vma temp = *vma1;
*vma1 = *vma2;
*vma2 = temp;
}
void
sort_vmas(struct vma* vmas)
{
struct vma *l = vmas, *r = vmas+MAXVMASSZIE-1, *bound;
if (l >= r)
return;
while (1) {
while (l < vmas+MAXVMASSZIE && !l->valid)
++l;
while (r >= vmas && r->valid)
--r;
if (l < r)
swap_vma(l, r);
else
break;
}
if (l == vmas)
return;
bound = r;
struct vma *i, *max;
while (vmas < bound) {
max = vmas;
for (i = vmas+1; i <= bound; ++i)
max = max->addr < i->addr ? i : max;
swap_vma(max, bound);
--bound;
}
}
上一部分也说过,mmap() 不会做很多工作,它只会分配并初始化 vma,并且把文件的引用数自增一而已。另外要注意,如果是以 SHARED 的方式 mmap 文件的,我们还需要检验 flags 和文件访问权限的一致性;PRIVATE 就不用了,因为此时内存内容不会写回源文件,你怎么修改内存内容都没关系。
/* kernel/sysfile.c */
uint64
sys_mmap(void)
{
int prot, flags, fd, length;
uint64 top = TRAPFRAME;
if (argint(1, &length) < 0 || argint(2, &prot) < 0 || argint(3, &flags) < 0 || argint(4, &fd) < 0)
return -1;
struct proc *p = myproc();
struct file *f = p->ofile[fd];
if (flags & MAP_SHARED) {
if (f->readable && !f->writable)
if (prot ^ PROT_READ)
return -1;
if (!f->readable && f->writable)
if (prot ^ PROT_WRITE)
return -1;
}
sort_vmas(p->vmas);
struct vma *vma, *res = p->vmas+MAXVMASSZIE-1;
if (!res->valid)
return -1;
for (vma = p->vmas; vma < p->vmas + MAXVMASSZIE; ++vma) {
if (!vma->valid) {
if (top <= vma->addr && vma->addr + vma->length <= top - length) {
break;
} else {
top = vma->addr;
}
} else {
break;
}
}
res->addr = top-length;
res->length = length;
res->flags = flags;
res->prot = prot;
res->valid = 0;
res->f = filedup(p->ofile[fd]);
return res->addr;
}
到了 usertrap() 这里对缺页中断的处理就跟 Lazy Allocation 很像了,都是各种异常和边界检查。新增的部分就是从文件读取内容这一块,我们用了一个辅助函数来封装了这部分的读写逻辑。
/* kernel/trap.c */
void
usertrap(void)
{
...
if(r_scause() == 8){
...
} else if (r_scause() == 13 || r_scause() == 15) {
uint64 va = r_stval();
uint64 sp = PGROUNDUP(p->trapframe->sp);
if (va >= MAXVA || va < sp) {
goto kl;
} else {
va = PGROUNDDOWN(va);
pte_t *pte;
if ((pte = walk(p->pagetable, va, 0)) != 0 && (*pte & PTE_V) != 0)
goto kl;
struct vma *vma;
for (vma = p->vmas; vma < p->vmas + MAXVMASSZIE; ++vma)
if (!vma->valid)
if(va >= vma->addr && va+PGSIZE <= vma->addr+vma->length)
break;
if (vma == &p->vmas[MAXVMASSZIE])
goto kl;
char *pa = kalloc();
if(pa != 0){
if(mappages(p->pagetable, va, PGSIZE, (uint64)pa, (vma->prot << 1) | PTE_U) != 0){
kfree(pa);
goto kl;
}
rw_vma(vma, 1, (uint64)pa, va-vma->addr, PGSIZE);
} else {
goto kl;
}
}
} else if((which_dev = devintr()) != 0){
// ok
} else {
kl:
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
...
}
/* kernel/sysfile.c */
int
rw_vma(struct vma *vma, int r, uint64 addr, uint off, uint n)
{
struct file *f = vma->f;
int res = 0;
if (r) {
ilock(f->ip);
readi(f->ip, 0, addr, off, n);
iunlock(f->ip);
int overflow = f->ip->size - off;
if (overflow <= PGSIZE && overflow > 0)
memset((char*)(addr+n-overflow), 0, overflow);
} else {
ilock(f->ip);
begin_op();
res = writei(f->ip, 0, addr, off, n);
end_op();
iunlock(f->ip);
}
return res;
}
这里是我踩的第一个大坑。注意到 mmap_test() 里先是打开名为 "mmap.dur" 的文件,调用 mmap() 将其映射到内存中。之后 _v1() 会读取 mmap() 分配的地址开始的 2 个 PGSIZE 字节的内容,因此总共会触发两次 page-fault 中断。虽然 usertrap() 会为这里分配两个 page,但实际上 "mmap.dur" 的文件大小只有 6144 字节,即 PGSIZE + (PGSZIE/2) 个字节。我们读第二个页的时候,readi 只会读 PGSIZE/2 个字节就返回了,因此我们需要在内存中剩余 PGSIZE/2 空间里用 0 来进行字节填充,这也是 rw_vma() 的第一个分支内部的所干的事情。否则 _v1() 会在 PGSZIE + (PGSIZE/2) 之后读到一些奇怪的数据,导致连第一个测试都通过不了。
到了 munmap(),由于在进程退出的时候也要释放 vma,因此要把这部分逻辑放到另一个辅助函数中:
/* kernel/sysfile.c */
int
_munmap(uint64 addr, int length, struct vma *vma)
{
struct proc *p = myproc();
if (!vma) {
for (vma = p->vmas; vma < p->vmas + MAXVMASSZIE; ++vma)
if (!vma->valid)
if (addr >= vma->addr && addr+length <= vma->addr+vma->length)
break;
if (vma == p->vmas+MAXVMASSZIE)
return -1;
} else {
addr = vma->addr;
length = vma->length;
}
if (vma->flags & MAP_SHARED)
_uvmunmap(p->pagetable, addr, PGROUNDUP(length)/PGSIZE, vma);
else
_uvmunmap(p->pagetable, addr, PGROUNDUP(length)/PGSIZE, 0);
vma->addr = vma->addr == addr ? addr+length : vma->addr;
vma->length -= length;
if (vma->length == 0) {
fileclose(vma->f);
vma->valid = 1;
}
return 0;
}
释放的逻辑很简单,先是搜索到某个 vma 使得它的范围能够包含住 addr 到 addr + length 的这段区间。但在进程释放的时候我们就不用这样搜索了,可以让调用者直接传入想要释放的 vma 进来。然后在释放内存时还要分情况讨论:如果 SHARED 的内容,就需要还需要写回磁盘里;而 PRIVATE 就释放 page 就好了。由于这两个处理逻辑很像,因此它们都由 _uvmunmap() 函数来处理。
/* kernel/sysfile.c */
void
_uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, struct vma* vma)
{
uint64 a;
pte_t *pte;
if((va % PGSIZE) != 0)
panic("uvmunmap: not aligned");
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0)
continue;
if((*pte & PTE_V) == 0)
continue;
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
uint64 pa = PTE2PA(*pte);
if (vma && *pte & PTE_D)
rw_vma(vma, 0, PTE2PA(*pte), a-vma->addr, PGSIZE);
kfree((void*)pa);
*pte = 0;
}
}
_munmap() 的逻辑能这么简单都要归功于测试不会在 vma 分配的内存区域之间 punch a hole,即测试每次都只从 vma 区域的一端开始释放,大大减小了算法的复杂度。
最后就是分配和释放进程时的一些初始化和回收逻辑:
/* kernel/pro.c */
static struct proc*
allocproc(void)
{
struct proc *p;
...
found:
...
for (struct vma *vma = p->vmas; vma < p->vmas + MAXVMASSZIE; ++vma) {
memset(vma, 0, sizeof(struct vma));
vma->valid = 1;
}
return p;
}
void
exit(int status)
{
...
// Close all open files.
for(int fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd]){
struct file *f = p->ofile[fd];
fileclose(f);
p->ofile[fd] = 0;
}
}
for (struct vma* vma = p->vmas; vma < p->vmas + MAXVMASSZIE; ++vma)
if (!vma->valid)
_munmap(0, 0, vma);
...
}
如果是跟着提示一点一点老老实实做比较好,但我当时看到释放进程时的 vma 的释放处理时,自认为觉得这部分逻辑放在 freeproc(struct proc *p) 里比较好一些,因为毕竟都是在处理页表相关的逻辑嘛。写完之后发现 forktest 一直 panic: freewalk leaf,死活找不到问题在哪里。后来一个个打印了进程的 pid 时发现执行 exit() 时的进程和执行 freeproc() 的进程不一样。这时才意识到进程退出后的资源回收是父进程的工作,而我当时是通过 myproc() 来获取 struct proc 指针的,导致对父进程的页表进行释放了。这是整个实验做下来个人感觉最大的坑。
最后贴一个 make grade 截图:
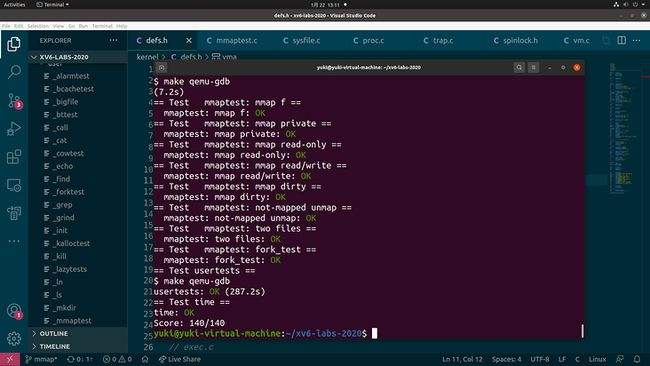
后记
这个实验是前面几个实验的内容的综合应用,不需要提前看很多东西,但毕竟是 hard,想要编译几次就通过全部的测试还是比较难的,我自己应该编译了 100 多次吧……(汗颜)
下一篇文章应该是 6.S081 2020 最后一个网卡驱动的实验实现,届时操作系统的学习就可以暂时告一段了。