读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
-----------
本文是第 7 篇图论算法文章,先列举一下我之前写过的图论算法:
1、图论算法基础
2、二分图判定算法
像图论算法这种高级算法虽然不算难,但是阅读量普遍比较低,我本来是不想写 Prim 算法的,但考虑到算法知识结构的完整性,我还是想把 Prim 算法的坑填上,这样所有经典的图论算法就基本完善了。
Prim 算法和 Kruskal 算法都是经典的最小生成树算法,阅读本文之前,希望你读过前文 Kruskal 最小生成树算法,了解最小生成树的基本定义以及 Kruskal 算法的基本原理,这样就能很容易理解 Prim 算法逻辑了。
对比 Kruskal 算法
图论的最小生成树问题,就是让你从图中找若干边形成一个边的集合 mst,这些边有以下特性:
1、这些边组成的是一棵树(树和图的区别在于不能包含环)。
2、这些边形成的树要包含所有节点。
3、这些边的权重之和要尽可能小。
那么 Kruskal 算法是使用什么逻辑满足上述条件,计算最小生成树的呢?
首先,Kruskal 算法用到了贪心思想,来满足权重之和尽可能小的问题:
先对所有边按照权重从小到大排序,从权重最小的边开始,选择合适的边加入 mst 集合,这样挑出来的边组成的树就是权重和最小的。
其次,Kruskal 算法用到了 Union-Find 并查集算法,来保证挑选出来的这些边组成的一定是一棵「树」,而不会包含环或者形成一片「森林」:
如果一条边的两个节点已经是连通的,则这条边会使树中出现环;如果最后的连通分量总数大于 1,则说明形成的是「森林」而不是一棵「树」。
那么,本文的主角 Prim 算法是使用什么逻辑来计算最小生成树的呢?
首先,Prim 算法也使用贪心思想来让生成树的权重尽可能小,也就是「切分定理」,这个后文会详细解释。
其次,Prim 算法使用 BFS 算法思想 和 visited 布尔数组避免成环,来保证选出来的边最终形成的一定是一棵树。
Prim 算法不需要事先对所有边排序,而是利用优先级队列动态实现排序的效果,所以我觉得 Prim 算法类似于 Kruskal 的动态过程。
下面介绍一下 Prim 算法的核心原理:切分定理。
切分定理
「切分」这个术语其实很好理解,就是将一幅图分为两个不重叠且非空的节点集合:

红色的这一刀把图中的节点分成了两个集合,就是一种「切分」,其中被红线切中的的边(标记为蓝色)叫做「横切边」。
PS:记住这两个专业术语的意思,后面我们会频繁使用这两个词,别搞混了。
当然,一幅图肯定可以有若干种切分,因为根据切分的定义,只要你能一刀把节点分成两部分就行。
接下来我们引入「切分定理」:
对于任意一种「切分」,其中权重最小的那条「横切边」一定是构成最小生成树的一条边。
这应该很容易证明,如果一幅加权无向图存在最小生成树,假设下图中用绿色标出来的边就是最小生成树:
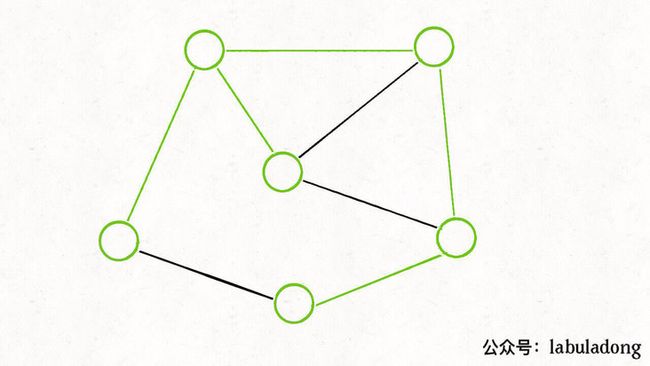
那么,你肯定可以找到若干「切分」方式,将这棵最小生成树切成两棵子树。比如下面这种切分:

你会发现,任选一条蓝色的「横切边」都可以将这两棵子树连接起来,构成一棵生成树。
那么为了让最终这棵生成树的权重和最小,你说你要怎么选?
肯定选权重最小的那条「横切边」对吧,这就证明了切分定理。
关于切分定理,你也可以用反证法证明:
给定一幅图的最小生成树,那么随便给一种「切分」,一定至少有一条「横切边」属于最小生成树。
假设这条「横切边」不是权重最小的,那说明最小生成树的权重和就还有再减小的余地,那这就矛盾了,最小生成树的权重和本来就是最小的,怎么再减?所以切分定理是正确的。
有了这个切分定理,你大概就有了一个计算最小生成树的算法思路了:
既然每一次「切分」一定可以找到最小生成树中的一条边,那我就随便切呗,每次都把权重最小的「横切边」拿出来加入最小生成树,直到把构成最小生成树的所有边都切出来为止。
嗯,可以说这就是 Prim 算法的核心思路,不过具体实现起来,还是要有些技巧的。
因为你没办法让计算机理解什么叫「随便切」,所以应该设计机械化的规则和章法来调教你的算法,并尽量减少无用功。
Prim 算法实现
我们思考算法问题时,如果问题的一般情况不好解决,可以从比较简单的特殊情况入手,Prim 算法就是使用的这种思路。
按照「切分」的定义,只要把图中的节点切成两个不重叠且非空的节点集合即可算作一个合法的「切分」,那么我只切出来一个节点,是不是也算是一个合法的「切分」?
是的,这是最简单的「切分」,而且「横切边」也很好确定,就是这个节点的边。
那我们就随便选一个点,假设就从 A 点开始切分:

既然这是一个合法的「切分」,那么按照切分定理,这些「横切边」AB, AF 中权重最小的边一定是最小生成树中的一条边:

好,现在已经找到最小生成树的第一条边(边 AB),然后呢,如何安排下一次「切分」?
按照 Prim 算法的逻辑,我们接下来可以围绕 A 和 B 这两个节点做切分:
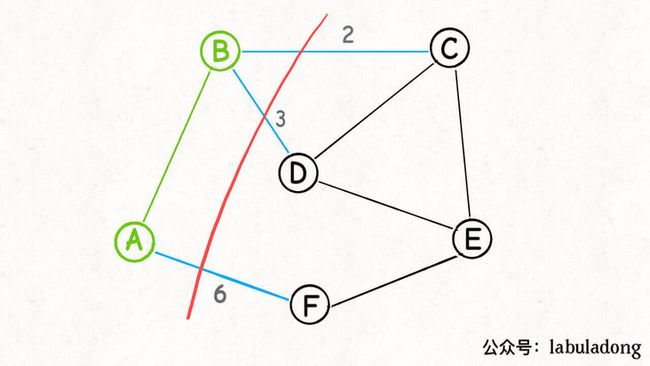
然后又可以从这个切分产生的横切边(图中蓝色的边)中找出权重最小的一条边,也就又找到了最小生成树中的第二条边 BC:

接下来呢?也是类似的,再围绕着 A, B, C 这三个点做切分,产生的横切边中权重最小的边是 BD,那么 BD 就是最小生成树的第三条边:

接下来再围绕 A, B, C, D 这四个点做切分……
Prim 算法的逻辑就是这样,每次切分都能找到最小生成树的一条边,然后又可以进行新一轮切分,直到找到最小生成树的所有边为止。
这样设计算法有一个好处,就是比较容易确定每次新的「切分」所产生的「横切边」。
比如回顾刚才的图,当我知道了节点 A, B 的所有「横切边」(不妨表示为 cut({A, B})),也就是图中蓝色的边:
是否可以快速算出 cut({A, B, C}),也就是节点 A, B, C 的所有「横切边」有哪些?
是可以的,因为我们发现:
cut({A, B, C}) = cut({A, B}) + cut({C})而 cut({C}) 就是节点 C 的所有邻边:

这个特点使我们用我们写代码实现「切分」和处理「横切边」成为可能:
在进行切分的过程中,我们只要不断把新节点的邻边加入横切边集合,就可以得到新的切分的所有横切边。
当然,细心的读者肯定发现了,cut({A, B}) 的横切边和 cut({C}) 的横切边中 BC 边重复了。
不过这很好处理,用一个布尔数组 inMST 辅助,防止重复计算横切边就行了。
最后一个问题,我们求横切边的目的是找权重最小的横切边,怎么做到呢?
很简单,用一个优先级队列存储这些横切边,就可以动态计算权重最小的横切边了。
明白了上述算法原理,下面来看一下 Prim 算法的代码实现:
class Prim {
// 核心数据结构,存储「横切边」的优先级队列
private PriorityQueue pq;
// 类似 visited 数组的作用,记录哪些节点已经成为最小生成树的一部分
private boolean[] inMST;
// 记录最小生成树的权重和
private int weightSum = 0;
// graph 是用邻接表表示的一幅图,
// graph[s] 记录节点 s 所有相邻的边,
// 三元组 int[]{from, to, weight} 表示一条边
private List[] graph;
public Prim(List[] graph) {
this.graph = graph;
this.pq = new PriorityQueue<>((a, b) -> {
// 按照边的权重从小到大排序
return a[2] - b[2];
});
// 图中有 n 个节点
int n = graph.length;
this.inMST = new boolean[n];
// 随便从一个点开始切分都可以,我们不妨从节点 0 开始
inMST[0] = true;
cut(0);
// 不断进行切分,向最小生成树中添加边
while (!pq.isEmpty()) {
int[] edge = pq.poll();
int to = edge[1];
int weight = edge[2];
if (inMST[to]) {
// 节点 to 已经在最小生成树中,跳过
// 否则这条边会产生环
continue;
}
// 将边 edge 加入最小生成树
weightSum += weight;
inMST[to] = true;
// 节点 to 加入后,进行新一轮切分,会产生更多横切边
cut(to);
}
}
// 将 s 的横切边加入优先队列
private void cut(int s) {
// 遍历 s 的邻边
for (int[] edge : graph[s]) {
int to = edge[1];
if (inMST[to]) {
// 相邻接点 to 已经在最小生成树中,跳过
// 否则这条边会产生环
continue;
}
// 加入横切边队列
pq.offer(edge);
}
}
// 最小生成树的权重和
public int weightSum() {
return weightSum;
}
// 判断最小生成树是否包含图中的所有节点
public boolean allConnected() {
for (int i = 0; i < inMST.length; i++) {
if (!inMST[i]) {
return false;
}
}
return true;
}
} 明白了切分定理,加上详细的代码注释,你应该能够看懂 Prim 算法的代码了。
这里我们可以再回顾一下本文开头说的 Prim 算法和 Kruskal 算法 的联系:
Kruskal 算法是在一开始的时候就把所有的边排序,然后从权重最小的边开始挑选属于最小生成树的边,组建最小生成树。
Prim 算法是从一个起点的切分(一组横切边)开始执行类似 BFS 算法的逻辑,借助切分定理和优先级队列动态排序的特性,从这个起点「生长」出一棵最小生成树。
说到这里,Prim 算法的时间复杂度是多少呢?
这个不难分析,复杂度主要在优先级队列 pq 的操作上,由于 pq 里面装的是图中的「边」,假设一幅图边的条数为 E,那么最多操作 O(E) 次 pq。每次操作优先级队列的时间复杂度取决于队列中的元素个数,取最坏情况就是 O(logE)。
所以这种 Prim 算法实现的总时间复杂度是 O(ElogE)。回想一下 Kruskal 算法,它的时间复杂度主要是给所有边按照权重排序,也是 O(ElogE)。
不过话说回来,和前文 Dijkstra 算法 类似,Prim 算法的时间复杂度也是可以优化的,但优化点在于优先级队列的实现上,和 Prim 算法本身的算法思想关系不大,所以我们这里就不做讨论了,有兴趣的读者可以自行搜索。
接下来,我们实操一波,把之前用 Kruskal 算法解决的力扣题目运用 Prim 算法再解决一遍。
题目实践
第一题是力扣第 1135 题「最低成本联通所有城市」,这是一道标准的最小生成树问题:

函数签名如下:
int minimumCost(int n, int[][] connections);每座城市相当于图中的节点,连通城市的成本相当于边的权重,连通所有城市的最小成本即是最小生成树的权重之和。
那么解法就很明显了,我们先把题目输入的 connections 转化成邻接表形式,然后输入给之前实现的 Prim 算法类即可:
public int minimumCost(int n, int[][] connections) {
// 转化成无向图邻接表的形式
List[] graph = buildGraph(n, connections);
// 执行 Prim 算法
Prim prim = new Prim(graph);
if (!prim.allConnected()) {
// 最小生成树无法覆盖所有节点
return -1;
}
return prim.weightSum();
}
List[] buildGraph(int n, int[][] connections) {
// 图中共有 n 个节点
List[] graph = new LinkedList[n];
for (int i = 0; i < n; i++) {
graph[i] = new LinkedList<>();
}
for (int[] conn : connections) {
// 题目给的节点编号是从 1 开始的,
// 但我们实现的 Prim 算法需要从 0 开始编号
int u = conn[0] - 1;
int v = conn[1] - 1;
int weight = conn[2];
// 「无向图」其实就是「双向图」
// 一条边表示为 int[]{from, to, weight}
graph[u].add(new int[]{u, v, weight});
graph[v].add(new int[]{v, u, weight});
}
return graph;
}
class Prim { /* 见上文 */ } 关于 buildGraph 函数需要注意两点:
一是题目给的节点编号是从 1 开始的,所以我们做一下索引偏移,转化成从 0 开始以便 Prim 类使用;
二是如何用邻接表表示无向加权图,前文 图论算法基础 说过「无向图」其实就可以理解为「双向图」。
这样,我们转化出来的 graph 形式就和之前的 Prim 算法类对应了,可以直接施展 Prim 算法计算最小生成树。
再来看看力扣第 1584 题「连接所有点的最小费用」:
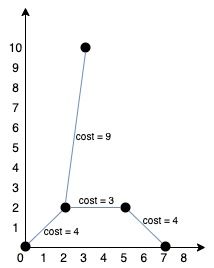
比如题目给的例子:
points = [[0,0],[2,2],[3,10],[5,2],[7,0]]算法应该返回 20,按如下方式连通各点:
函数签名如下:
int minCostConnectPoints(int[][] points);很显然这也是一个标准的最小生成树问题:每个点就是无向加权图中的节点,边的权重就是曼哈顿距离,连接所有点的最小费用就是最小生成树的权重和。
所以我们只要把 points 数组转化成邻接表的形式,即可复用之前实现的 Prim 算法类:
public int minCostConnectPoints(int[][] points) {
int n = points.length;
List[] graph = buildGraph(n, points);
return new Prim(graph).weightSum();
}
// 构造无向图
List[] buildGraph(int n, int[][] points) {
List[] graph = new LinkedList[n];
for (int i = 0; i < n; i++) {
graph[i] = new LinkedList<>();
}
// 生成所有边及权重
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
int xi = points[i][0], yi = points[i][1];
int xj = points[j][0], yj = points[j][1];
int weight = Math.abs(xi - xj) + Math.abs(yi - yj);
// 用 points 中的索引表示坐标点
graph[i].add(new int[]{i, j, weight});
graph[j].add(new int[]{j, i, weight});
}
}
return graph;
}
class Prim { /* 见上文 */ } 这道题做了一个小的变通:每个坐标点是一个二元组,那么按理说应该用五元组表示一条带权重的边,但这样的话不便执行 Prim 算法;所以我们用 points 数组中的索引代表每个坐标点,这样就可以直接复用之前的 Prim 算法逻辑了。
到这里,Prim 算法就讲完了,整个图论算法也整的差不多了,更多精彩文章,敬请期待。